 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCL-bench: A Benchmark for Context Learning
Feb 03, 2026Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios.
Analysis of Sensing in OFDM-based ISAC under the Influence of Sampling Jitter
Jan 21, 2026To enable integrated sensing and communication (ISAC) in cellular networks, a wide range of additional requirements and challenges are either imposed or become more critical. One such impairment is sampling jitter (SJ), which arises due to imperfections in the sampling instants of the clocks of digital-to-analog converters (DACs) and analog-to-digital converters (ADCs). While SJ is already well studied for communication systems based on orthogonal frequency-division multiplexing (OFDM), which is expected to be the waveform of choice for most sixth-generation (6G) scenarios where ISAC could be possible, the implications of SJ on the OFDM-based radar sensing must still be thoroughly analyzed. Considering that phase-locked loop (PLL)-based oscillators are used to derive sampling clocks, which leads to colored SJ, i.e., SJ with non-flat power spectral density, this article analyzes the resulting distortion of the adopted digital constellation modulation and sensing performance in OFDM-based ISAC for both baseband (BB) and bandpass (BP) sampling strategies and different oversampling factors. For BB sampling, it is seen that SJ induces intercarrier interference (ICI), while for BP sampling, it causes carrier phase error and more severe ICI due to a phase noise-like effect at the digital intermediate frequency. Obtained results for a single-input single-output OFDM-based ISAC system with various OFDM signal parameterizations demonstrate that SJ-induced degradation becomes non-negligible for both BB and BP sampling only for root mean square (RMS) SJ values above 10^-11 s at both DAC and ADC, which corresponds to 0.5*10^-2 times the considered critical sampling period without oversampling. Based on the achieved results, it can be concluded that state-of-the-art hardware enables sufficient communication and sensing robustness against SJ, as RMS SJ values in the femtosecond range can be achieved.
Embodied Robot Manipulation in the Era of Foundation Models: Planning and Learning Perspectives
Dec 28, 2025Recent advances in vision, language, and multimodal learning have substantially accelerated progress in robotic foundation models, with robot manipulation remaining a central and challenging problem. This survey examines robot manipulation from an algorithmic perspective and organizes recent learning-based approaches within a unified abstraction of high-level planning and low-level control. At the high level, we extend the classical notion of task planning to include reasoning over language, code, motion, affordances, and 3D representations, emphasizing their role in structured and long-horizon decision making. At the low level, we propose a training-paradigm-oriented taxonomy for learning-based control, organizing existing methods along input modeling, latent representation learning, and policy learning. Finally, we identify open challenges and prospective research directions related to scalability, data efficiency, multimodal physical interaction, and safety. Together, these analyses aim to clarify the design space of modern foundation models for robotic manipulation.
Robust Differentiable Collision Detection for General Objects
Nov 09, 2025Collision detection is a core component of robotics applications such as simulation, control, and planning. Traditional algorithms like GJK+EPA compute witness points (i.e., the closest or deepest-penetration pairs between two objects) but are inherently non-differentiable, preventing gradient flow and limiting gradient-based optimization in contact-rich tasks such as grasping and manipulation. Recent work introduced efficient first-order randomized smoothing to make witness points differentiable; however, their direction-based formulation is restricted to convex objects and lacks robustness for complex geometries. In this work, we propose a robust and efficient differentiable collision detection framework that supports both convex and concave objects across diverse scales and configurations. Our method introduces distance-based first-order randomized smoothing, adaptive sampling, and equivalent gradient transport for robust and informative gradient computation. Experiments on complex meshes from DexGraspNet and Objaverse show significant improvements over existing baselines. Finally, we demonstrate a direct application of our method for dexterous grasp synthesis to refine the grasp quality. The code is available at https://github.com/JYChen18/DiffCollision.
FlowVLA: Thinking in Motion with a Visual Chain of Thought
Aug 25, 2025Many Vision-Language-Action (VLA) models rely on an internal world model trained via next-frame prediction. This approach, however, struggles with physical reasoning as it entangles static appearance with dynamic motion, often resulting in implausible visual forecasts and inefficient policy learning. To address these limitations, we introduce the Visual Chain of Thought (Visual CoT): a pre-training framework that encourages a model to reason about how a scene evolves before predicting what it will look like. We instantiate this principle in FlowVLA, which predicts a future frame ($v_{t+1}$) only after generating an intermediate optical flow representation ($f_t$) that encodes motion dynamics. This ``$v_t \rightarrow f_t \rightarrow v_{t+1}$'' reasoning process is implemented within a single autoregressive Transformer, guiding the model to learn disentangled dynamics. As a result, FlowVLA produces coherent visual predictions and facilitates more efficient policy learning. Experiments on challenging robotics manipulation benchmarks demonstrate state-of-the-art performance with substantially improved sample efficiency, pointing toward a more principled foundation for world modeling. Project page: https://irpn-lab.github.io/FlowVLA/
ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
Aug 14, 2025Recent advances in Vision-Language-Action (VLA) models have enabled robotic agents to integrate multimodal understanding with action execution. However, our empirical analysis reveals that current VLAs struggle to allocate visual attention to target regions. Instead, visual attention is always dispersed. To guide the visual attention grounding on the correct target, we propose ReconVLA, a reconstructive VLA model with an implicit grounding paradigm. Conditioned on the model's visual outputs, a diffusion transformer aims to reconstruct the gaze region of the image, which corresponds to the target manipulated objects. This process prompts the VLA model to learn fine-grained representations and accurately allocate visual attention, thus effectively leveraging task-specific visual information and conducting precise manipulation. Moreover, we curate a large-scale pretraining dataset comprising over 100k trajectories and 2 million data samples from open-source robotic datasets, further boosting the model's generalization in visual reconstruction. Extensive experiments in simulation and the real world demonstrate the superiority of our implicit grounding method, showcasing its capabilities of precise manipulation and generalization. Our project page is https://zionchow.github.io/ReconVLA/.
Small-Large Collaboration: Training-efficient Concept Personalization for Large VLM using a Meta Personalized Small VLM
Aug 10, 2025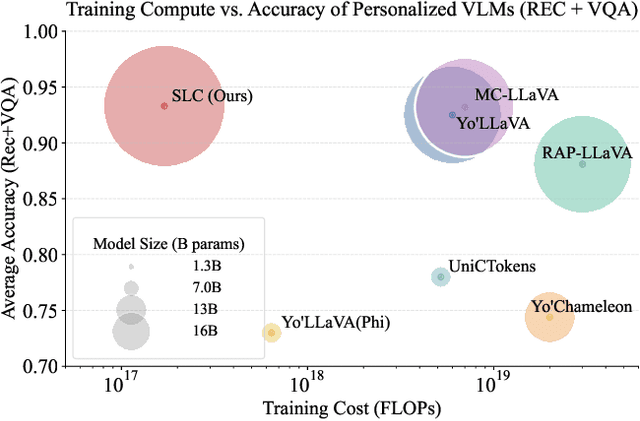
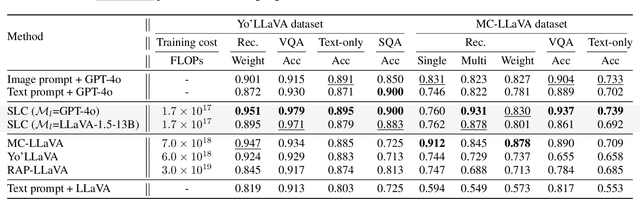
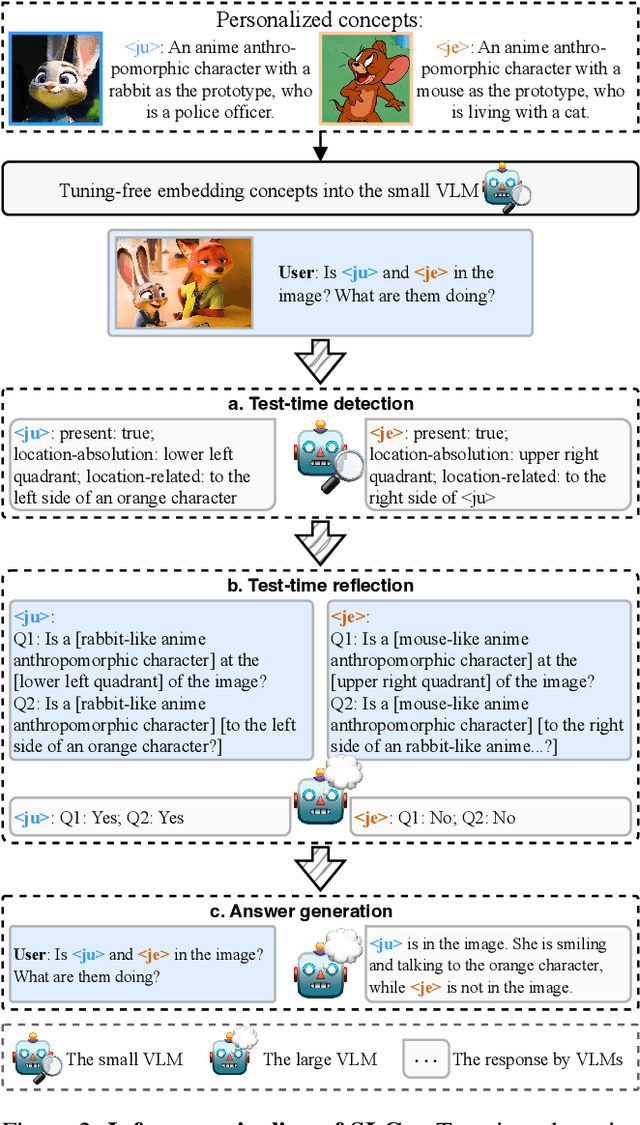
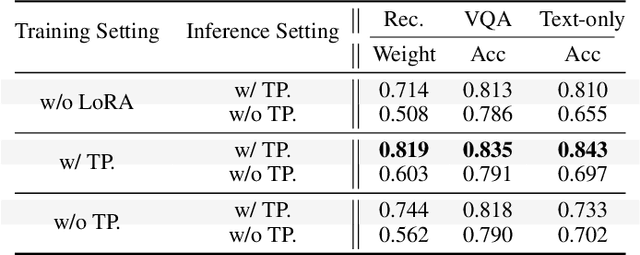
Personalizing Vision-Language Models (VLMs) to transform them into daily assistants has emerged as a trending research direction. However, leading companies like OpenAI continue to increase model size and develop complex designs such as the chain of thought (CoT). While large VLMs are proficient in complex multi-modal understanding, their high training costs and limited access via paid APIs restrict direct personalization. Conversely, small VLMs are easily personalized and freely available, but they lack sufficient reasoning capabilities. Inspired by this, we propose a novel collaborative framework named Small-Large Collaboration (SLC) for large VLM personalization, where the small VLM is responsible for generating personalized information, while the large model integrates this personalized information to deliver accurate responses. To effectively incorporate personalized information, we develop a test-time reflection strategy, preventing the potential hallucination of the small VLM. Since SLC only needs to train a meta personalized small VLM for the large VLMs, the overall process is training-efficient. To the best of our knowledge, this is the first training-efficient framework that supports both open-source and closed-source large VLMs, enabling broader real-world personalized applications. We conduct thorough experiments across various benchmarks and large VLMs to demonstrate the effectiveness of the proposed SLC framework. The code will be released at https://github.com/Hhankyangg/SLC.
DexVLG: Dexterous Vision-Language-Grasp Model at Scale
Jul 03, 2025As large models gain traction, vision-language-action (VLA) systems are enabling robots to tackle increasingly complex tasks. However, limited by the difficulty of data collection, progress has mainly focused on controlling simple gripper end-effectors. There is little research on functional grasping with large models for human-like dexterous hands. In this paper, we introduce DexVLG, a large Vision-Language-Grasp model for Dexterous grasp pose prediction aligned with language instructions using single-view RGBD input. To accomplish this, we generate a dataset of 170 million dexterous grasp poses mapped to semantic parts across 174,000 objects in simulation, paired with detailed part-level captions. This large-scale dataset, named DexGraspNet 3.0, is used to train a VLM and flow-matching-based pose head capable of producing instruction-aligned grasp poses for tabletop objects. To assess DexVLG's performance, we create benchmarks in physics-based simulations and conduct real-world experiments. Extensive testing demonstrates DexVLG's strong zero-shot generalization capabilities-achieving over 76% zero-shot execution success rate and state-of-the-art part-grasp accuracy in simulation-and successful part-aligned grasps on physical objects in real-world scenarios.
Compositional Attribute Imbalance in Vision Datasets
Jun 17, 2025Visual attribute imbalance is a common yet underexplored issue in image classification, significantly impacting model performance and generalization. In this work, we first define the first-level and second-level attributes of images and then introduce a CLIP-based framework to construct a visual attribute dictionary, enabling automatic evaluation of image attributes. By systematically analyzing both single-attribute imbalance and compositional attribute imbalance, we reveal how the rarity of attributes affects model performance. To tackle these challenges, we propose adjusting the sampling probability of samples based on the rarity of their compositional attributes. This strategy is further integrated with various data augmentation techniques (such as CutMix, Fmix, and SaliencyMix) to enhance the model's ability to represent rare attributes. Extensive experiments on benchmark datasets demonstrate that our method effectively mitigates attribute imbalance, thereby improving the robustness and fairness of deep neural networks. Our research highlights the importance of modeling visual attribute distributions and provides a scalable solution for long-tail image classification tasks.
CEED-VLA: Consistency Vision-Language-Action Model with Early-Exit Decoding
Jun 16, 2025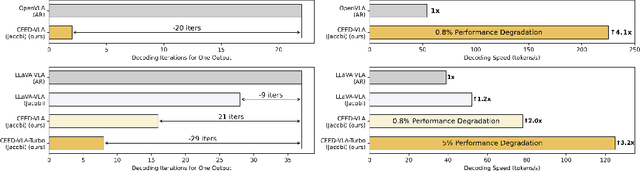
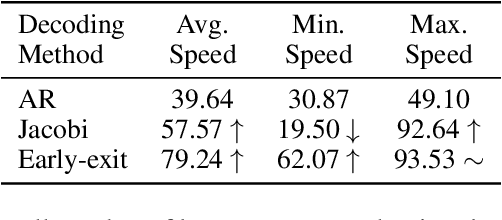
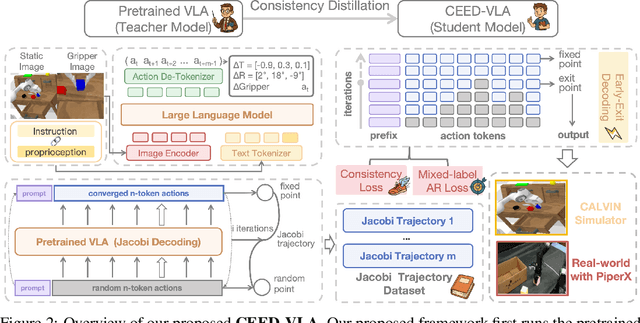
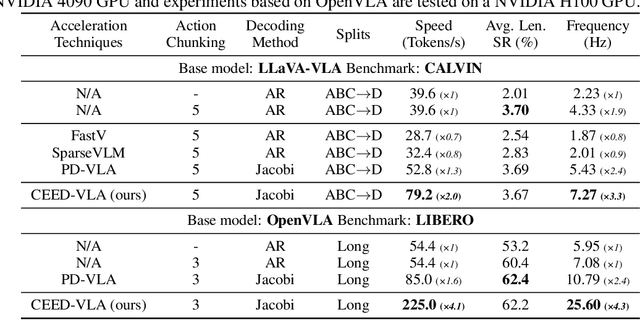
In recent years, Vision-Language-Action (VLA) models have become a vital research direction in robotics due to their impressive multimodal understanding and generalization capabilities. Despite the progress, their practical deployment is severely constrained by inference speed bottlenecks, particularly in high-frequency and dexterous manipulation tasks. While recent studies have explored Jacobi decoding as a more efficient alternative to traditional autoregressive decoding, its practical benefits are marginal due to the lengthy iterations. To address it, we introduce consistency distillation training to predict multiple correct action tokens in each iteration, thereby achieving acceleration. Besides, we design mixed-label supervision to mitigate the error accumulation during distillation. Although distillation brings acceptable speedup, we identify that certain inefficient iterations remain a critical bottleneck. To tackle this, we propose an early-exit decoding strategy that moderately relaxes convergence conditions, which further improves average inference efficiency. Experimental results show that the proposed method achieves more than 4 times inference acceleration across different baselines while maintaining high task success rates in both simulated and real-world robot tasks. These experiments validate that our approach provides an efficient and general paradigm for accelerating multimodal decision-making in robotics. Our project page is available at https://irpn-eai.github.io/CEED-VLA/.