 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromptCD: Test-Time Behavior Enhancement via Polarity-Prompt Contrastive Decoding
Feb 24, 2026Reliable AI systems require large language models (LLMs) to exhibit behaviors aligned with human preferences and values. However, most existing alignment approaches operate at training time and rely on additional high-quality data, incurring significant computational and annotation costs. While recent work has shown that contrastive decoding can leverage a model's internal distributions to improve specific capabilities, its applicability remains limited to narrow behavioral scopes and scenarios. In this work, we introduce Polarity-Prompt Contrastive Decoding (PromptCD), a test-time behavior control method that generalizes contrastive decoding to broader enhancement settings. PromptCD constructs paired positive and negative guiding prompts for a target behavior and contrasts model responses-specifically token-level probability distributions in LLMs and visual attention patterns in VLMs-to reinforce desirable outcomes. This formulation extends contrastive decoding to a wide range of enhancement objectives and is applicable to both LLMs and Vision-Language Models (VLMs) without additional training. For LLMs, experiments on the "3H" alignment objectives (helpfulness, honesty, and harmlessness) demonstrate consistent and substantial improvements, indicating that post-trained models can achieve meaningful self-enhancement purely at test time. For VLMs, we further analyze contrastive effects on visual attention, showing that PromptCD significantly improves VQA performance by reinforcing behavior-consistent visual grounding. Collectively, these results highlight PromptCD as a simple, general, and cost-efficient strategy for reliable behavior control across modalities.
PIS: Linking Importance Sampling and Attention Mechanisms for Efficient Prompt Compression
Apr 23, 2025Large language models (LLMs) have achieved remarkable progress, demonstrating unprecedented capabilities across various natural language processing tasks. However, the high costs associated with such exceptional performance limit the widespread adoption of LLMs, highlighting the need for prompt compression. Existing prompt compression methods primarily rely on heuristic truncation or abstractive summarization techniques, which fundamentally overlook the intrinsic mechanisms of LLMs and lack a systematic evaluation of token importance for generation. In this work, we introduce Prompt Importance Sampling (PIS), a novel compression framework that dynamically compresses prompts by sampling important tokens based on the analysis of attention scores of hidden states. PIS employs a dual-level compression mechanism: 1) at the token level, we quantify saliency using LLM-native attention scores and implement adaptive compression through a lightweight 9-layer reinforcement learning (RL) network; 2) at the semantic level, we propose a Russian roulette sampling strategy for sentence-level importance sampling. Comprehensive evaluations across multiple domain benchmarks demonstrate that our method achieves state-of-the-art compression performance. Notably, our framework serendipitously enhances reasoning efficiency through optimized context structuring. This work advances prompt engineering by offering both theoretical grounding and practical efficiency in context management for LLMs.
Innate Reasoning is Not Enough: In-Context Learning Enhances Reasoning Large Language Models with Less Overthinking
Mar 25, 2025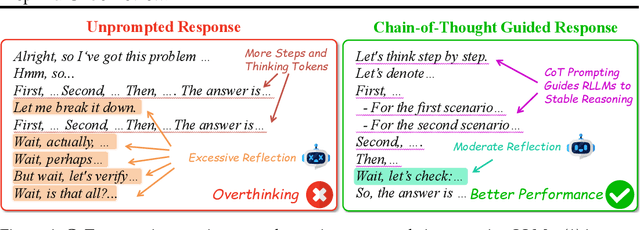
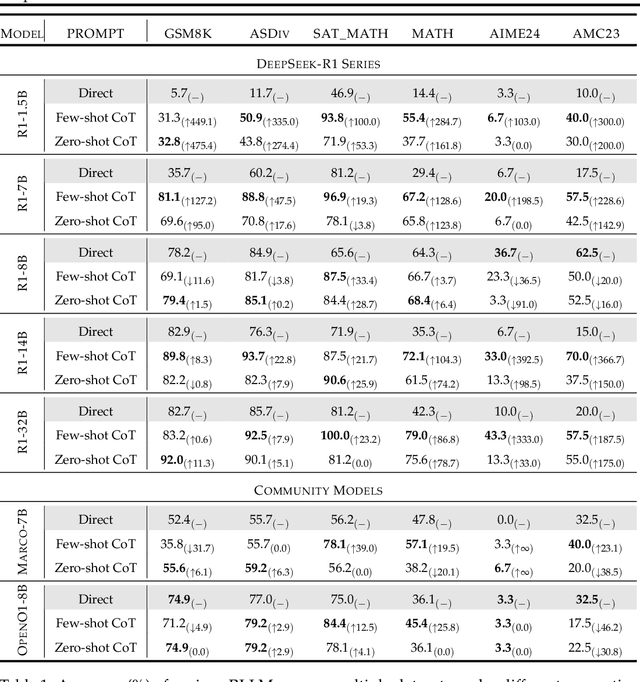
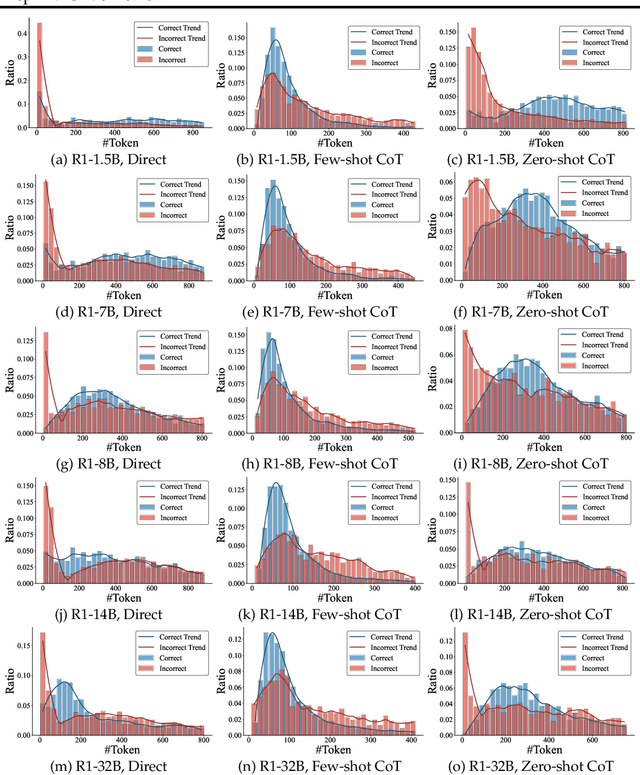
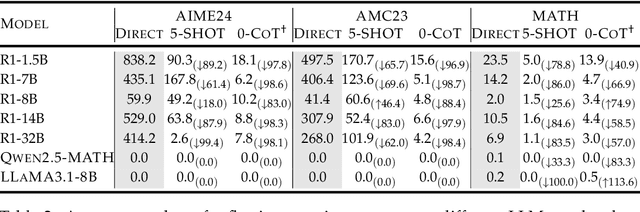
Recent advances in Large Language Models (LLMs) have introduced Reasoning Large Language Models (RLLMs), which employ extended thinking processes with reflection and self-correction capabilities, demonstrating the effectiveness of test-time scaling. RLLMs exhibit innate Chain-of-Thought (CoT) reasoning capability obtained from training, leading to a natural question: "Is CoT prompting, a popular In-Context Learning (ICL) method for chat LLMs, necessary to enhance the reasoning capability of RLLMs?" In this work, we present the first comprehensive analysis of the impacts of Zero-shot CoT and Few-shot CoT on RLLMs across mathematical reasoning tasks. We examine models ranging from 1.5B to 32B parameters, finding that contrary to concerns, CoT prompting significantly enhances RLLMs' performance in most scenarios. Our results reveal distinct patterns: large-capacity models show minimal improvement on simple tasks but substantial gains on complex problems, while smaller models exhibit the opposite behavior. Further analysis demonstrates that CoT prompting effectively controls the distribution of the numbers of thinking tokens and reasoning steps, reducing excessive reflections by approximately 90% in some cases. Moreover, attention logits analysis reveals the RLLMs' overfitting to reflection-related words, which is mitigated by external CoT guidance. Notably, our experiments indicate that for RLLMs, one-shot CoT consistently yields superior performance compared to Few-shot CoT approaches. Our findings provide important insights for optimizing RLLMs' performance through appropriate prompting strategies.
Graph Descriptive Order Improves Reasoning with Large Language Model
Feb 24, 2024
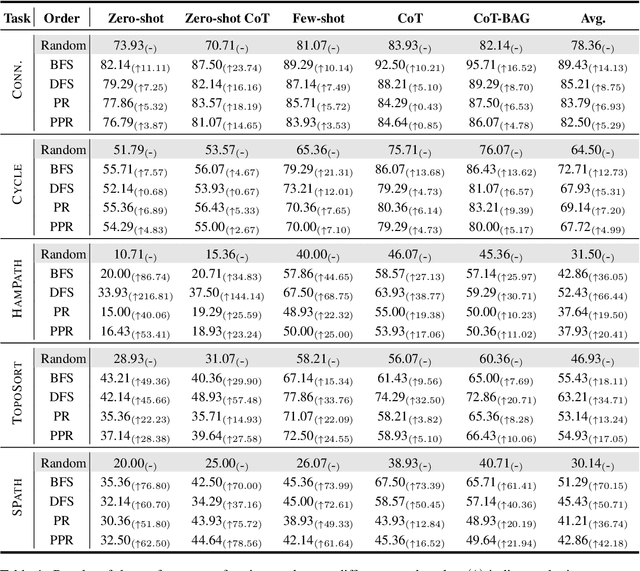
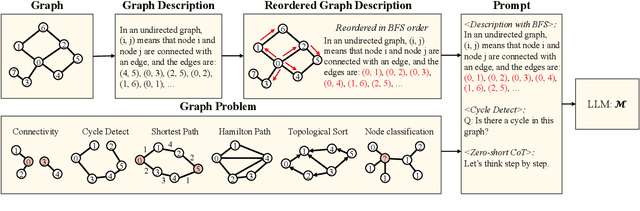
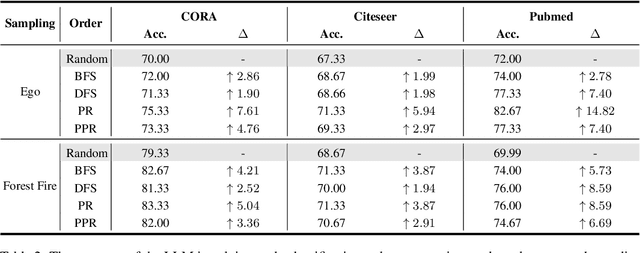
In recent years, large language models have achieved state-of-the-art performance across multiple domains. However, the progress in the field of graph reasoning with LLM remains limited. Our work delves into this gap by thoroughly investigating graph reasoning with LLMs. In this work, we reveal the impact of the order of graph description on LLMs' graph reasoning performance, which significantly affects LLMs' reasoning abilities. By altering this order, we enhance the performance of LLMs from 42.22\% to 70\%. Furthermore, we introduce the Scaled Graph Reasoning benchmark for assessing LLMs' performance across various graph sizes and evaluate the relationship between LLMs' graph reasoning abilities and graph size. We discover that the graph reasoning performance of LLMs does not monotonically decrease with the increase in graph size. The experiments span several mainstream models, including GPT-3.5, LLaMA-2-7B, and LLaMA-2-13B, to offer a comprehensive evaluation.
Self-supervised Spatiotemporal Representation Learning by Exploiting Video Continuity
Jan 10, 2022
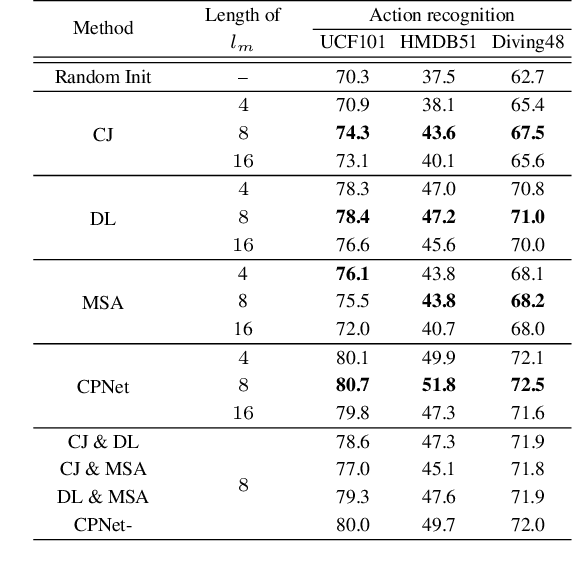
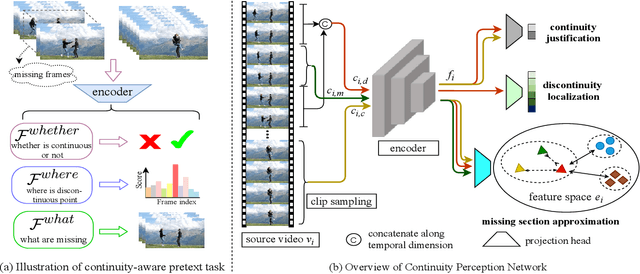
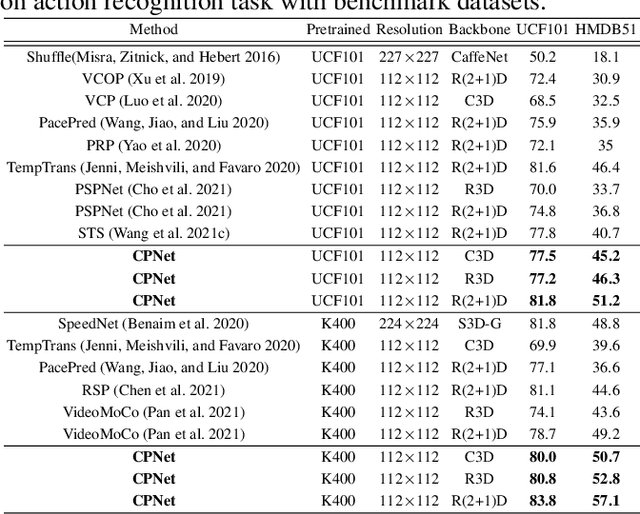
Recent self-supervised video representation learning methods have found significant success by exploring essential properties of videos, e.g. speed, temporal order, etc. This work exploits an essential yet under-explored property of videos, the video continuity, to obtain supervision signals for self-supervised representation learning. Specifically, we formulate three novel continuity-related pretext tasks, i.e. continuity justification, discontinuity localization, and missing section approximation, that jointly supervise a shared backbone for video representation learning. This self-supervision approach, termed as Continuity Perception Network (CPNet), solves the three tasks altogether and encourages the backbone network to learn local and long-ranged motion and context representations. It outperforms prior arts on multiple downstream tasks, such as action recognition, video retrieval, and action localization. Additionally, the video continuity can be complementary to other coarse-grained video properties for representation learning, and integrating the proposed pretext task to prior arts can yield much performance gains.