 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the GUI Paradigm: Do Mobile Agents Need the Phone Screen?
Jun 16, 2026Recent advances in mobile agents are dominated by the GUI paradigm, in which agents perceive UI information and emit screen interactions. However, mobile platforms also expose a command-line interface (CLI) that provides direct access to device services and data. We argue CLI deserves first-class consideration alongside GUI. We evaluate three coding agents (Claude Code, Terminus-2, mini-swe-agent) across four model APIs on AndroidWorld and MobileWorld without any mobile-specific post-training, comparing against three reproducible GUI baselines (GUI-Owl-1.5-32B, MAI-UI, Qwen3-VL-32B). Claude Code (Opus 4.7) reaches 71.8\% and 51.9\%, outperforming every reproducible GUI baseline (69.3/68.1/57.8\% on AndroidWorld; 43.2/26.3/13.3\% on MobileWorld), while every other CLI configuration remains competitive. To establish the paradigm's ceiling, we provide oracle CLI solutions that reach 88.8\% on AndroidWorld (103/116 tasks CLI-solvable) and 86.3\% on MobileWorld (101/117 tasks CLI-solvable), indicating substantial room for future improvement. To cover everyday user intents beyond the GUI scope, we introduce the \textbf{CLI-Advantage Task Suite}, comprising 45 templates across five categories: bulk operations, multi-condition filtering, aggregation, cross-app workflows, and hidden device state. Every CLI agent outperforms every GUI baseline in all five categories, with substantially fewer steps per task (10.7 vs.\ 18.6). To support future research on mobile CLI agents, we will open-source agent implementations, oracle solutions, the CLI-Advantage suite, and evaluation infrastructure.
X-Palm: Paired Multispectral-to-Smartphone Dataset for Cross-Domain Palmprint Authentication
Jun 07, 2026Palmprint modality offers a privacy-preserving biometric solution, yet its deployment is hindered by the domain gap between controlled enrollment and unconstrained authentication. Existing datasets are largely restricted to controlled setups and fail to capture the compound variability of real-world environments. In this paper, we introduce X-Palm, a cross-domain dataset comprising 6,006 palm images from 103 individuals (206 hands). To the best of our knowledge, X-Palm is the first palmprint dataset providing novel paired-identity acquisition specifically designed to bridge the gap between reliably controlled multispectral enrollment and unconstrained mobile authentication while encompassing a broad spectrum of in-the-wild variability. Unlike existing datasets that focus on single to a few variations, X-Palm addresses the massive modality and environmental shifts encountered in practical deployments by capturing paired data for identities across two distinct domains: (1) a controlled Multispectral Palmprint setting using our custom-developed scanner, and (2) an unconstrained smartphone palmprint setting that is participant-driven, incorporating simultaneous variations in hardware, hand pose, illumination, background, camera-to-hand distance, perspective, and palm surface conditions (e.g., moisture and occlusions). Our extensive benchmarks of 12 SOTA models reveal that while existing methods achieve high performance on controlled data, they experience severe performance collapse on X-Palm. Conversely, models trained on X-Palm demonstrate consistent robustness across domains, positioning X-Palm as a valuable resource for training a model towards real-world, cross-domain generalization. Data access instructions and the related benchmarking codes are publicly available at: https://github.com/X-Palm/X-Palm-2026
PACO: Proxy-Task Alignment and Online Calibration for On-the-Fly Category Discovery
Apr 13, 2026On-the-Fly Category Discovery (OCD) requires a model, trained on an offline support set, to recognize known classes while discovering new ones from an online streaming sequence. Existing methods focus heavily on offline training. They aim to learn discriminative representations on the support set so that novel classes can be separated at test time. However, their discovery mechanism at inference is typically reduced to a single threshold. We argue that this paradigm is fundamentally flawed as OCD is not a static classification problem, but a dynamic process. The model must continuously decide 1) whether a sample belongs to a known class, 2) matches an existing novel category, or 3) should initiate a new one. Moreover, prior methods treat the support set as fixed knowledge. They do not update their decision boundaries as new evidence arrives during inference. This leads to unstable and inconsistent category formation. Our experiments confirm these issues. With properly calibrated and adaptive thresholds, substantial improvements can be achieved, even without changing the representation. Motivated by this, we propose PACO, a support-set-calibrated, tree-structured online decision framework. The framework models inference as a sequence of hierarchical decisions, including known-class routing, birth-aware novel assignment, and attach-versus-create operations over a dynamic prototype memory. Furthermore, we simulate the proxy discovery process to initialize the thresholds during offline training to align with inference. Thresholds are continuously updated during inference using mature novel prototypes. Importantly, PACO requires no heavy training and no dataset-specific tuning. It can be directly integrated into existing OCD pipelines as an inference-time module. Extensive experiments show significant improvements over SOTA baselines across seven benchmarks.
ETR: Entropy Trend Reward for Efficient Chain-of-Thought Reasoning
Apr 07, 2026Chain-of-thought (CoT) reasoning improves large language model performance on complex tasks, but often produces excessively long and inefficient reasoning traces. Existing methods shorten CoTs using length penalties or global entropy reduction, implicitly assuming that low uncertainty is desirable throughout reasoning. We show instead that reasoning efficiency is governed by the trajectory of uncertainty. CoTs with dominant downward entropy trends are substantially shorter. Motivated by this insight, we propose Entropy Trend Reward (ETR), a trajectory-aware objective that encourages progressive uncertainty reduction while allowing limited local exploration. We integrate ETR into Group Relative Policy Optimization (GRPO) and evaluate it across multiple reasoning models and challenging benchmarks. ETR consistently achieves a superior accuracy-efficiency tradeoff, improving DeepSeek-R1-Distill-7B by 9.9% in accuracy while reducing CoT length by 67% across four benchmarks. Code is available at https://github.com/Xuan1030/ETR
Learning through Creation: A Hash-Free Framework for On-the-Fly Category Discovery
Mar 17, 2026On-the-Fly Category Discovery (OCD) aims to recognize known classes while simultaneously discovering emerging novel categories during inference, using supervision only from known classes during offline training. Existing approaches rely either on fixed label supervision or on diffusion-based augmentations to enhance the backbone, yet none of them explicitly train the model to perform the discovery task required at test time. It is fundamentally unreasonable to expect a model optimized on limited labeled data to carry out a qualitatively different discovery objective during inference. This mismatch creates a clear optimization misalignment between the offline learning stage and the online discovery stage. In addition, prior methods often depend on hash-based encodings or severe feature compression, which further limits representational capacity. To address these issues, we propose Learning through Creation (LTC), a fully feature-based and hash-free framework that injects novel-category awareness directly into offline learning. At its core is a lightweight, online pseudo-unknown generator driven by kernel-energy minimization and entropy maximization (MKEE). Unlike previous methods that generate synthetic samples once before training, our generator evolves jointly with the model dynamics and synthesizes pseudo-novel instances on the fly at negligible cost. These samples are incorporated through a dual max-margin objective with adaptive thresholding, strengthening the model's ability to delineate and detect unknown regions through explicit creation. Extensive experiments across seven benchmarks show that LTC consistently outperforms prior work, achieving improvements ranging from 1.5 percent to 13.1 percent in all-class accuracy. The code is available at https://github.com/brandinzhang/LTC
TALON: Test-time Adaptive Learning for On-the-Fly Category Discovery
Mar 09, 2026On-the-fly category discovery (OCD) aims to recognize known categories while simultaneously discovering novel ones from an unlabeled online stream, using a model trained only on labeled data. Existing approaches freeze the feature extractor trained offline and employ a hash-based framework that quantizes features into binary codes as class prototypes. However, discovering novel categories with a fixed knowledge base is counterintuitive, as the learning potential of incoming data is entirely neglected. In addition, feature quantization introduces information loss, diminishes representational expressiveness, and amplifies intra-class variance. It often results in category explosion, where a single class is fragmented into multiple pseudo-classes. To overcome these limitations, we propose a test-time adaptation framework that enables learning through discovery. It incorporates two complementary strategies: a semantic-aware prototype update and a stable test-time encoder update. The former dynamically refines class prototypes to enhance classification, whereas the latter integrates new information directly into the parameter space. Together, these components allow the model to continuously expand its knowledge base with newly encountered samples. Furthermore, we introduce a margin-aware logit calibration in the offline stage to enlarge inter-class margins and improve intra-class compactness, thereby reserving embedding space for future class discovery. Experiments on standard OCD benchmarks demonstrate that our method substantially outperforms existing hash-based state-of-the-art approaches, yielding notable improvements in novel-class accuracy and effectively mitigating category explosion. The code is publicly available at \textcolor{blue}{https://github.com/ynanwu/TALON}.
Normalized Conditional Mutual Information Surrogate Loss for Deep Neural Classifiers
Jan 05, 2026In this paper, we propose a novel information theoretic surrogate loss; normalized conditional mutual information (NCMI); as a drop in alternative to the de facto cross-entropy (CE) for training deep neural network (DNN) based classifiers. We first observe that the model's NCMI is inversely proportional to its accuracy. Building on this insight, we introduce an alternating algorithm to efficiently minimize the NCMI. Across image recognition and whole-slide imaging (WSI) subtyping benchmarks, NCMI-trained models surpass state of the art losses by substantial margins at a computational cost comparable to that of CE. Notably, on ImageNet, NCMI yields a 2.77% top-1 accuracy improvement with ResNet-50 comparing to the CE; on CAMELYON-17, replacing CE with NCMI improves the macro-F1 by 8.6% over the strongest baseline. Gains are consistent across various architectures and batch sizes, suggesting that NCMI is a practical and competitive alternative to CE.
Few-Shot-Based Modular Image-to-Video Adapter for Diffusion Models
Dec 23, 2025Diffusion models (DMs) have recently achieved impressive photorealism in image and video generation. However, their application to image animation remains limited, even when trained on large-scale datasets. Two primary challenges contribute to this: the high dimensionality of video signals leads to a scarcity of training data, causing DMs to favor memorization over prompt compliance when generating motion; moreover, DMs struggle to generalize to novel motion patterns not present in the training set, and fine-tuning them to learn such patterns, especially using limited training data, is still under-explored. To address these limitations, we propose Modular Image-to-Video Adapter (MIVA), a lightweight sub-network attachable to a pre-trained DM, each designed to capture a single motion pattern and scalable via parallelization. MIVAs can be efficiently trained on approximately ten samples using a single consumer-grade GPU. At inference time, users can specify motion by selecting one or multiple MIVAs, eliminating the need for prompt engineering. Extensive experiments demonstrate that MIVA enables more precise motion control while maintaining, or even surpassing, the generation quality of models trained on significantly larger datasets.
Widget2Code: From Visual Widgets to UI Code via Multimodal LLMs
Dec 22, 2025User interface to code (UI2Code) aims to generate executable code that can faithfully reconstruct a given input UI. Prior work focuses largely on web pages and mobile screens, leaving app widgets underexplored. Unlike web or mobile UIs with rich hierarchical context, widgets are compact, context-free micro-interfaces that summarize key information through dense layouts and iconography under strict spatial constraints. Moreover, while (image, code) pairs are widely available for web or mobile UIs, widget designs are proprietary and lack accessible markup. We formalize this setting as the Widget-to-Code (Widget2Code) and introduce an image-only widget benchmark with fine-grained, multi-dimensional evaluation metrics. Benchmarking shows that although generalized multimodal large language models (MLLMs) outperform specialized UI2Code methods, they still produce unreliable and visually inconsistent code. To address these limitations, we develop a baseline that jointly advances perceptual understanding and structured code generation. At the perceptual level, we follow widget design principles to assemble atomic components into complete layouts, equipped with icon retrieval and reusable visualization modules. At the system level, we design an end-to-end infrastructure, WidgetFactory, which includes a framework-agnostic widget-tailored domain-specific language (WidgetDSL) and a compiler that translates it into multiple front-end implementations (e.g., React, HTML/CSS). An adaptive rendering module further refines spatial dimensions to satisfy compactness constraints. Together, these contributions substantially enhance visual fidelity, establishing a strong baseline and unified infrastructure for future Widget2Code research.
Distribution Alignment for Fully Test-Time Adaptation with Dynamic Online Data Streams
Jul 16, 2024
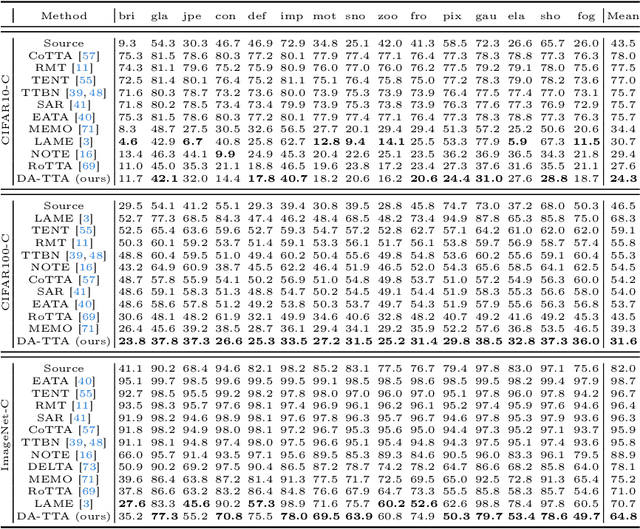

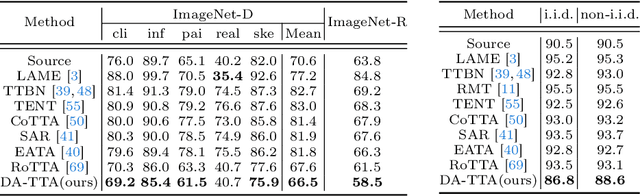
Given a model trained on source data, Test-Time Adaptation (TTA) enables adaptation and inference in test data streams with domain shifts from the source. Current methods predominantly optimize the model for each incoming test data batch using self-training loss. While these methods yield commendable results in ideal test data streams, where batches are independently and identically sampled from the target distribution, they falter under more practical test data streams that are not independent and identically distributed (non-i.i.d.). The data batches in a non-i.i.d. stream display prominent label shifts relative to each other. It leads to conflicting optimization objectives among batches during the TTA process. Given the inherent risks of adapting the source model to unpredictable test-time distributions, we reverse the adaptation process and propose a novel Distribution Alignment loss for TTA. This loss guides the distributions of test-time features back towards the source distributions, which ensures compatibility with the well-trained source model and eliminates the pitfalls associated with conflicting optimization objectives. Moreover, we devise a domain shift detection mechanism to extend the success of our proposed TTA method in the continual domain shift scenarios. Our extensive experiments validate the logic and efficacy of our method. On six benchmark datasets, we surpass existing methods in non-i.i.d. scenarios and maintain competitive performance under the ideal i.i.d. assumption.