 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWidget2Code: From Visual Widgets to UI Code via Multimodal LLMs
Dec 22, 2025User interface to code (UI2Code) aims to generate executable code that can faithfully reconstruct a given input UI. Prior work focuses largely on web pages and mobile screens, leaving app widgets underexplored. Unlike web or mobile UIs with rich hierarchical context, widgets are compact, context-free micro-interfaces that summarize key information through dense layouts and iconography under strict spatial constraints. Moreover, while (image, code) pairs are widely available for web or mobile UIs, widget designs are proprietary and lack accessible markup. We formalize this setting as the Widget-to-Code (Widget2Code) and introduce an image-only widget benchmark with fine-grained, multi-dimensional evaluation metrics. Benchmarking shows that although generalized multimodal large language models (MLLMs) outperform specialized UI2Code methods, they still produce unreliable and visually inconsistent code. To address these limitations, we develop a baseline that jointly advances perceptual understanding and structured code generation. At the perceptual level, we follow widget design principles to assemble atomic components into complete layouts, equipped with icon retrieval and reusable visualization modules. At the system level, we design an end-to-end infrastructure, WidgetFactory, which includes a framework-agnostic widget-tailored domain-specific language (WidgetDSL) and a compiler that translates it into multiple front-end implementations (e.g., React, HTML/CSS). An adaptive rendering module further refines spatial dimensions to satisfy compactness constraints. Together, these contributions substantially enhance visual fidelity, establishing a strong baseline and unified infrastructure for future Widget2Code research.
Distribution Alignment for Fully Test-Time Adaptation with Dynamic Online Data Streams
Jul 16, 2024
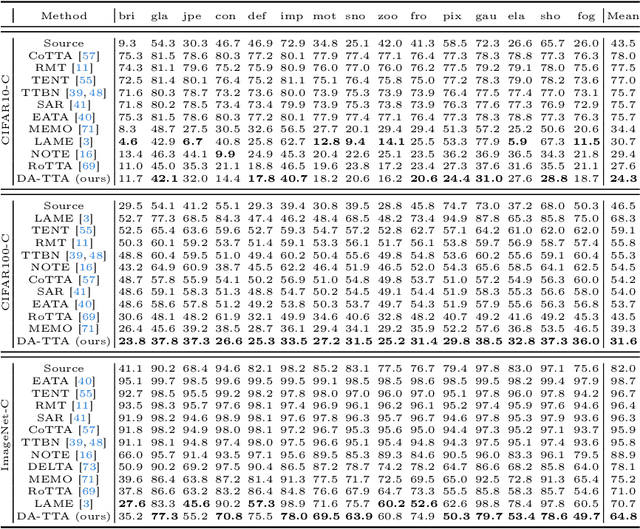

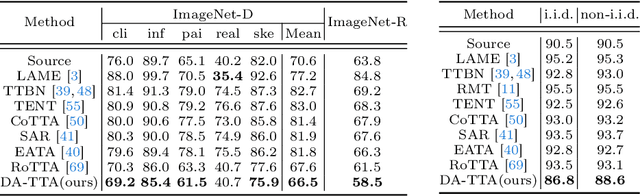
Given a model trained on source data, Test-Time Adaptation (TTA) enables adaptation and inference in test data streams with domain shifts from the source. Current methods predominantly optimize the model for each incoming test data batch using self-training loss. While these methods yield commendable results in ideal test data streams, where batches are independently and identically sampled from the target distribution, they falter under more practical test data streams that are not independent and identically distributed (non-i.i.d.). The data batches in a non-i.i.d. stream display prominent label shifts relative to each other. It leads to conflicting optimization objectives among batches during the TTA process. Given the inherent risks of adapting the source model to unpredictable test-time distributions, we reverse the adaptation process and propose a novel Distribution Alignment loss for TTA. This loss guides the distributions of test-time features back towards the source distributions, which ensures compatibility with the well-trained source model and eliminates the pitfalls associated with conflicting optimization objectives. Moreover, we devise a domain shift detection mechanism to extend the success of our proposed TTA method in the continual domain shift scenarios. Our extensive experiments validate the logic and efficacy of our method. On six benchmark datasets, we surpass existing methods in non-i.i.d. scenarios and maintain competitive performance under the ideal i.i.d. assumption.
Ontology-aware Network for Zero-shot Sketch-based Image Retrieval
Feb 20, 2023Zero-Shot Sketch-Based Image Retrieval (ZSSBIR) is an emerging task. The pioneering work focused on the modal gap but ignored inter-class information. Although recent work has begun to consider the triplet-based or contrast-based loss to mine inter-class information, positive and negative samples need to be carefully selected, or the model is prone to lose modality-specific information. To respond to these issues, an Ontology-Aware Network (OAN) is proposed. Specifically, the smooth inter-class independence learning mechanism is put forward to maintain inter-class peculiarity. Meanwhile, distillation-based consistency preservation is utilized to keep modality-specific information. Extensive experiments have demonstrated the superior performance of our algorithm on two challenging Sketchy and Tu-Berlin datasets.
Fully Automated Deep Learning-enabled Detection for Hepatic Steatosis on Computed Tomography: A Multicenter International Validation Study
Nov 06, 2022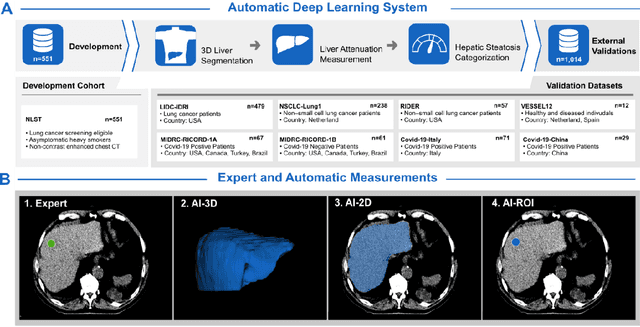

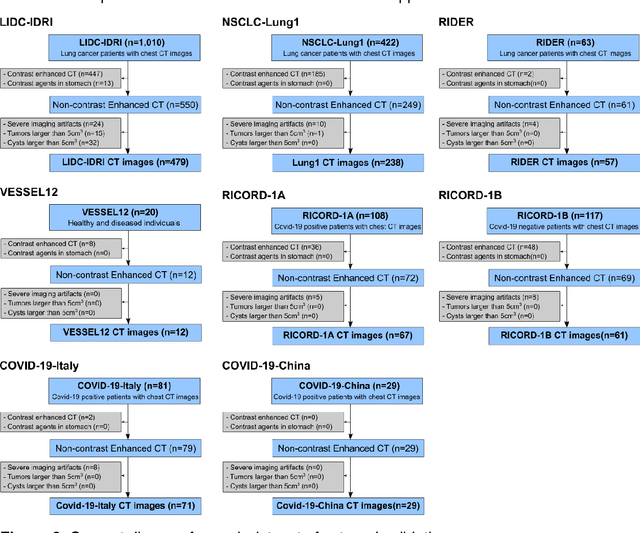

Despite high global prevalence of hepatic steatosis, no automated diagnostics demonstrated generalizability in detecting steatosis on multiple international datasets. Traditionally, hepatic steatosis detection relies on clinicians selecting the region of interest (ROI) on computed tomography (CT) to measure liver attenuation. ROI selection demands time and expertise, and therefore is not routinely performed in populations. To automate the process, we validated an existing artificial intelligence (AI) system for 3D liver segmentation and used it to purpose a novel method: AI-ROI, which could automatically select the ROI for attenuation measurements. AI segmentation and AI-ROI method were evaluated on 1,014 non-contrast enhanced chest CT images from eight international datasets: LIDC-IDRI, NSCLC-Lung1, RIDER, VESSEL12, RICORD-1A, RICORD-1B, COVID-19-Italy, and COVID-19-China. AI segmentation achieved a mean dice coefficient of 0.957. Attenuations measured by AI-ROI showed no significant differences (p = 0.545) and a reduction of 71% time compared to expert measurements. The area under the curve (AUC) of the steatosis classification of AI-ROI is 0.921 (95% CI: 0.883 - 0.959). If performed as a routine screening method, our AI protocol could potentially allow early non-invasive, non-pharmacological preventative interventions for hepatic steatosis. 1,014 expert-annotated liver segmentations of patients with hepatic steatosis annotations can be downloaded here: https://drive.google.com/drive/folders/1-g_zJeAaZXYXGqL1OeF6pUjr6KB0igJX.
Learning-based multiplexed transmission of scattered twisted light through a kilometer-scale standard multimode fiber
Jan 17, 2022Multiplexing multiple orbital angular momentum (OAM) modes of light has the potential to increase data capacity in optical communication. However, the distribution of such modes over long distances remains challenging. Free-space transmission is strongly influenced by atmospheric turbulence and light scattering, while the wave distortion induced by the mode dispersion in fibers disables OAM demultiplexing in fiber-optic communications. Here, a deep-learning-based approach is developed to recover the data from scattered OAM channels without measuring any phase information. Over a 1-km-long standard multimode fiber, the method is able to identify different OAM modes with an accuracy of more than 99.9% in parallel demultiplexing of 24 scattered OAM channels. To demonstrate the transmission quality, color images are encoded in multiplexed twisted light and our method achieves decoding the transmitted data with an error rate of 0.13%. Our work shows the artificial intelligence algorithm could benefit the use of OAM multiplexing in commercial fiber networks and high-performance optical communication in turbulent environments.
A Computational Efficient Maximum Likelihood Direct Position Determination Approach for Multiple Emitters Using Angle and Doppler Measurements
Dec 04, 2021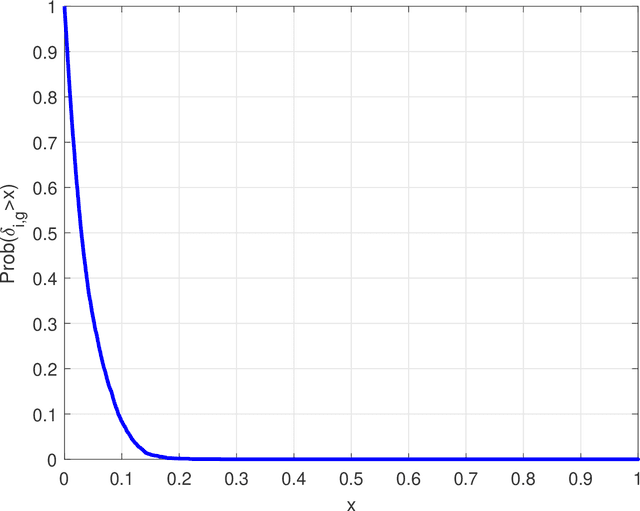
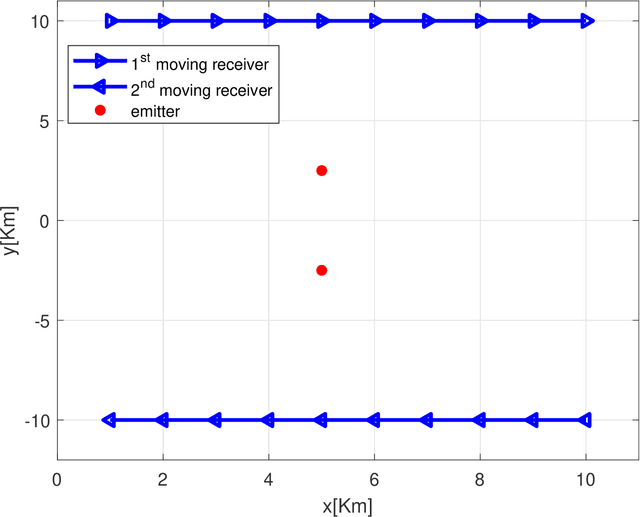
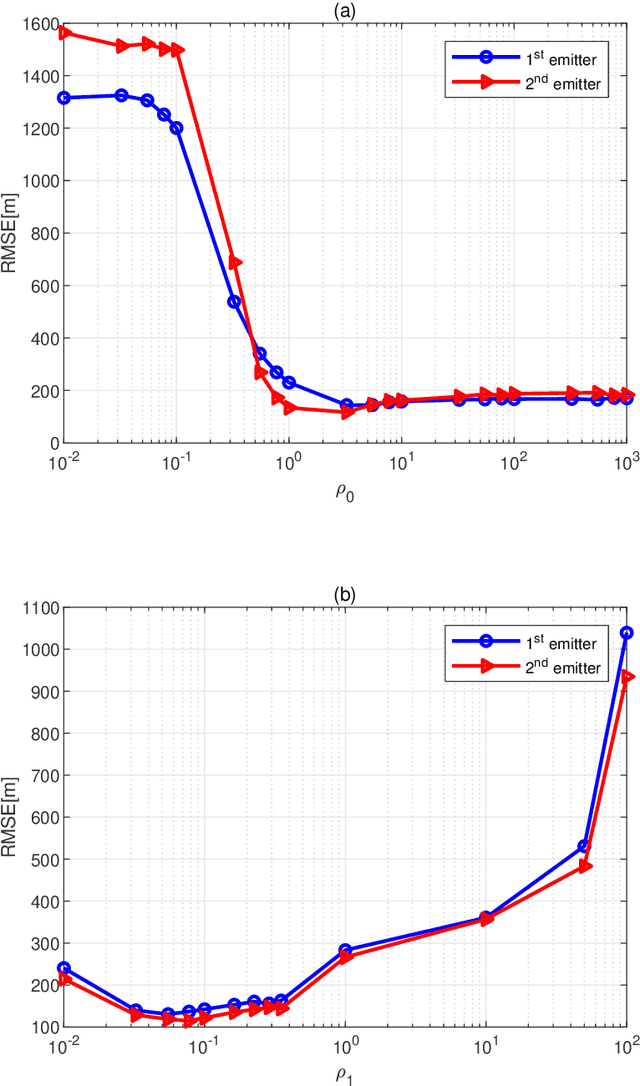
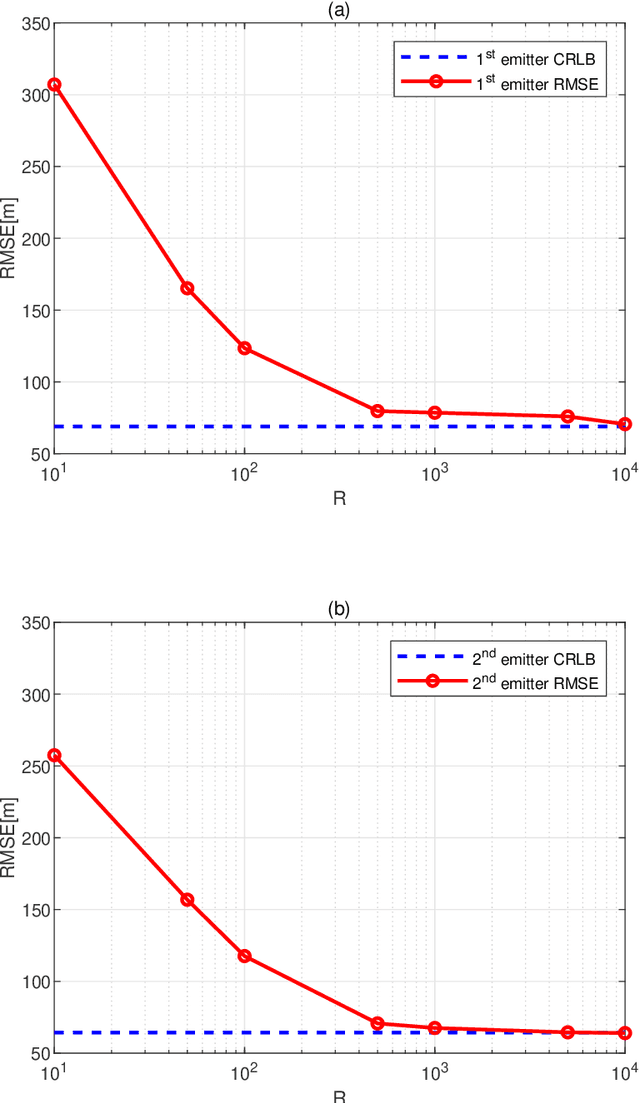
Emitter localization is widely applied in the military and civilian _elds. In this paper, we tackle the problem of position estimation for multiple stationary emitters using Doppler frequency shifts and angles by moving receivers. The computational load for the exhaustive maximum likelihood (ML) direct position determination (DPD) search is insu_erable. Based on the Pincus' theorem and importance sampling (IS) concept, we propose a novel non-iterative ML DPD method. The proposed method transforms the original multidimensional grid search into random variables generation with multiple low-dimensional pseudo-probability density functions (PDF), and the circular mean is used for superior position estimation performance. The computational complexity of the proposed method is modest, and the o_-grid problem that most existing DPD techniques face is signi_cantly alleviated. Moreover, it can be implemented in parallel separately. Simulation results demonstrate that the proposed ML DPD estimator can achieve better estimation accuracy than state-of-the-art DPD techniques. With a reasonable parameter choice, the estimation performance of the proposed technique is very close to the Cram_er-Rao lower bound (CRLB), even in the adverse conditions of low signal-to-noise ratios (SNR) levels.
Spatio-Temporal Self-Attention Network for Video Saliency Prediction
Aug 24, 2021
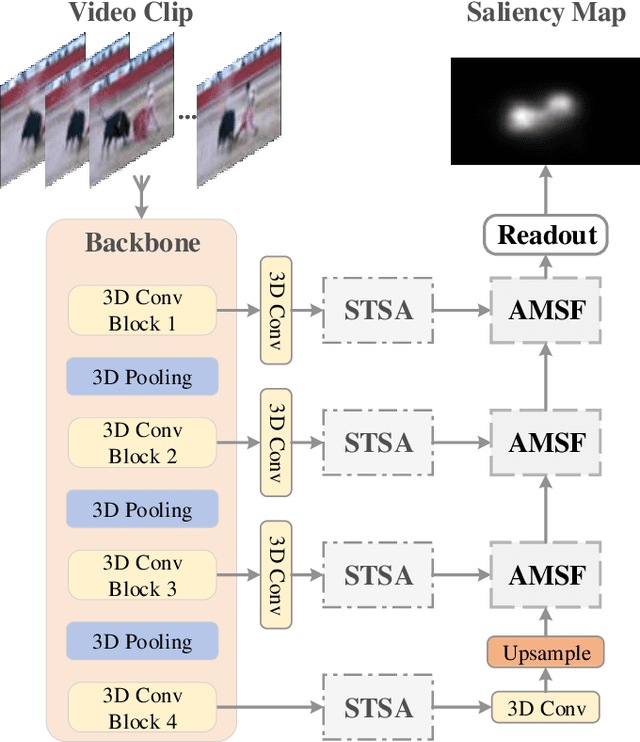
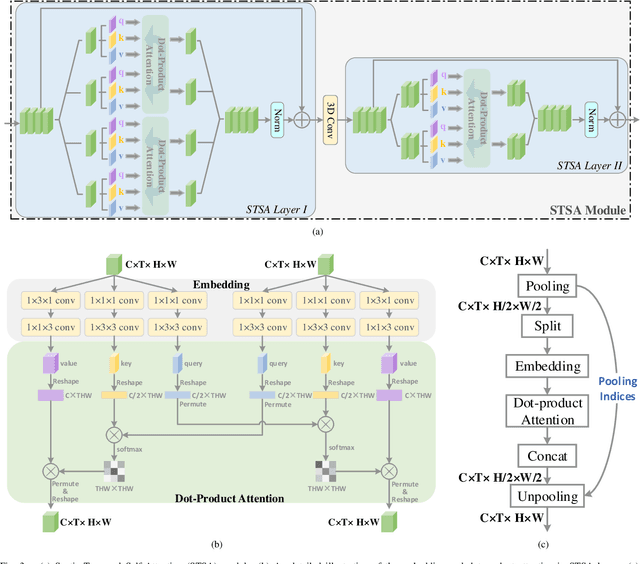
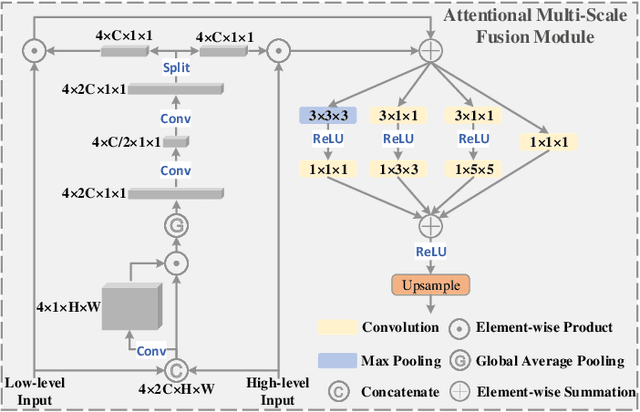
3D convolutional neural networks have achieved promising results for video tasks in computer vision, including video saliency prediction that is explored in this paper. However, 3D convolution encodes visual representation merely on fixed local spacetime according to its kernel size, while human attention is always attracted by relational visual features at different time of a video. To overcome this limitation, we propose a novel Spatio-Temporal Self-Attention 3D Network (STSANet) for video saliency prediction, in which multiple Spatio-Temporal Self-Attention (STSA) modules are employed at different levels of 3D convolutional backbone to directly capture long-range relations between spatio-temporal features of different time steps. Besides, we propose an Attentional Multi-Scale Fusion (AMSF) module to integrate multi-level features with the perception of context in semantic and spatio-temporal subspaces. Extensive experiments demonstrate the contributions of key components of our method, and the results on DHF1K, Hollywood-2, UCF, and DIEM benchmark datasets clearly prove the superiority of the proposed model compared with all state-of-the-art models.
Wheeled Robots Path Planing and Tracking System Based on Monocular Visual SLAM
Jul 17, 2018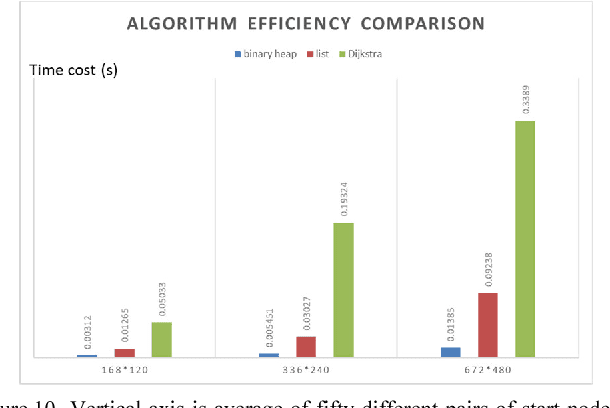
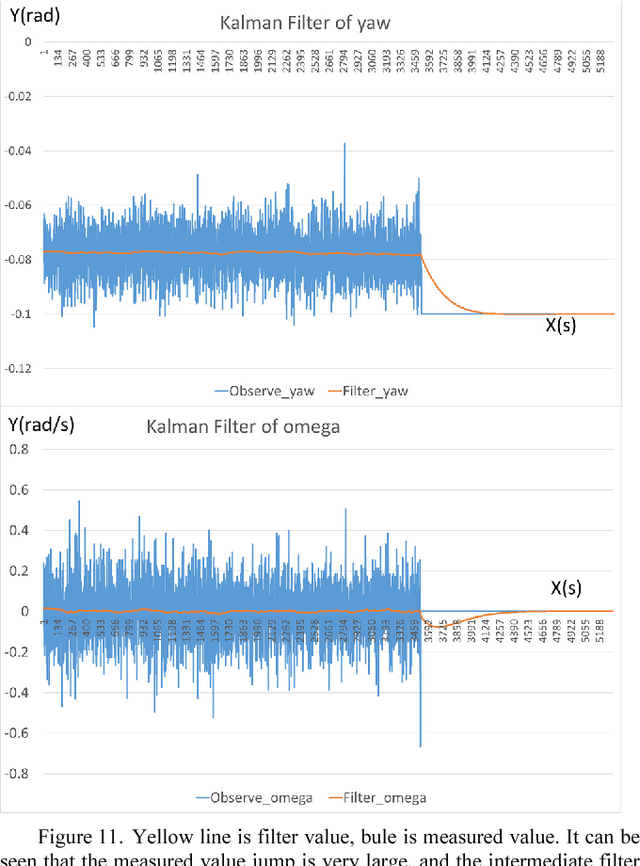
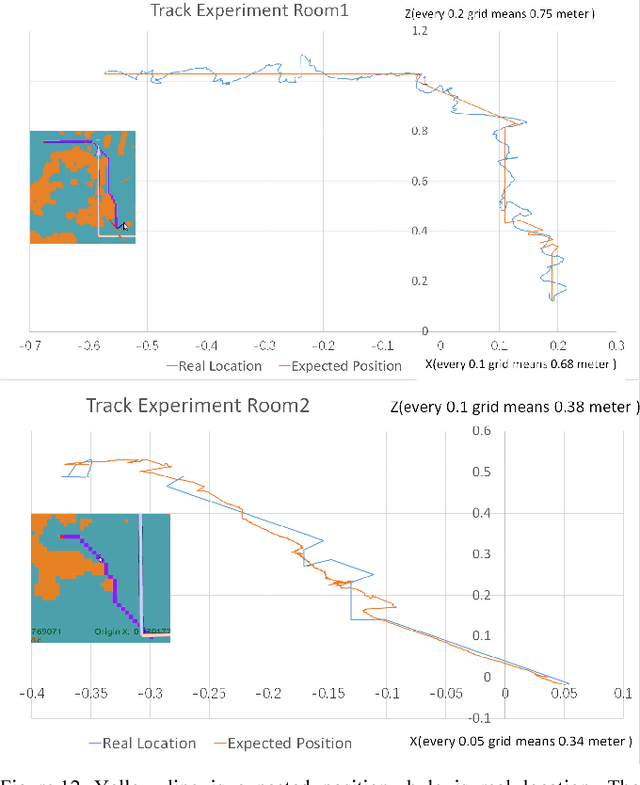
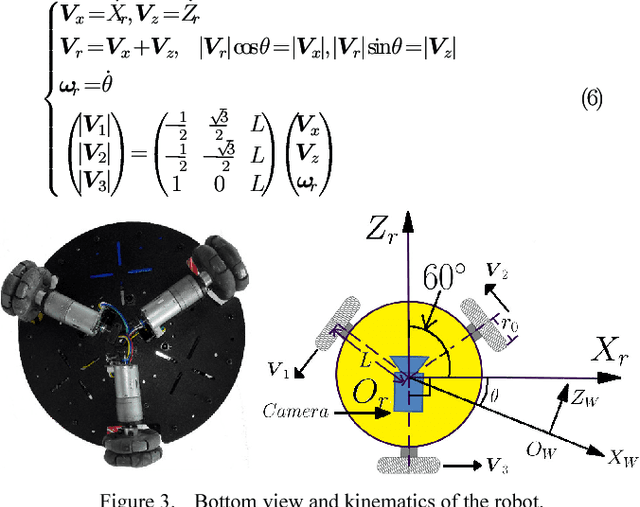
Warehouse logistics robots will work in different warehouse environments. In order to enable robots to perceive environment and plan path faster without modifying existing warehouses, we uses monocular camera to achieve an efficient robot integrated system. Mapping and path planning the two main tasks presented in this paper. The direct method visual odometry is applied to localize, and the 3D position of major obstacles in the environment is calculated. We describe the terrain with occupied grid map, the 3D points are projected onto the robot motion plane, thus accessibility of each grid is determined. Based on the terrain information, the optimized A* algorithm is used for path planning. Finally, according to localization and planning, we control the robot to track path. We also develop a path-tracking robot prototype. Simulation and experimental results verify the effectiveness and reliability of the proposed method.