 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-GRU Enhanced End-to-End Design for Long-haul Coherent Transmission Systems
Apr 28, 2023In recent years, the end-to-end (E2E) scheme based on deep learning (DL), jointly optimizes the encoder and decoder parameters located of the system. Since the center-oriented Gated Recurrent Unit (Co-GRU) network structure satisfying gradient BP while having the ability to learn and compensate for intersymbol interference (ISI) with low computation cost, it is adopted for both the channel modeling and decoder implementation in the E2E design scheme proposed. Meanwhile, to obtain the constellation with the symmetrical distribution characteristic, the encoder and decoder are first E2E joint trained through NLIN model, and further trained on the Co-GRU channel replacing the SSFM channel as well as the subsequent digital signal processing (DSP) step. After the E2EDL process, the performance of the encoder and decoder trained is tested on the SSFM channel. For the E2E system with the Co-GRU based decoder, the gain of general mutual information (GMI) and the Q2-factor relative to the conventional QAM system, are respectively improved up to 0.2 bits/sym and 0.48dB for the long-haul 5-channel dual-polarization coherent system with 960 transmission distance at around the optimal launch power point. The work paves the way for the further study of the application for the Co-GRU structure in the data-driven E2E design of the experimental system, both for the channel modeling and the decoder performance improvement.
Spatio-Temporal Self-Attention Network for Video Saliency Prediction
Aug 24, 2021
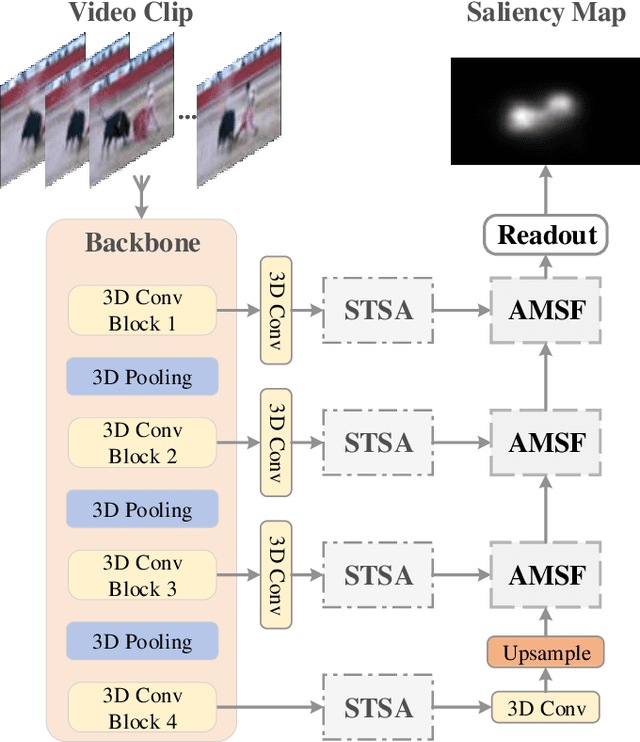
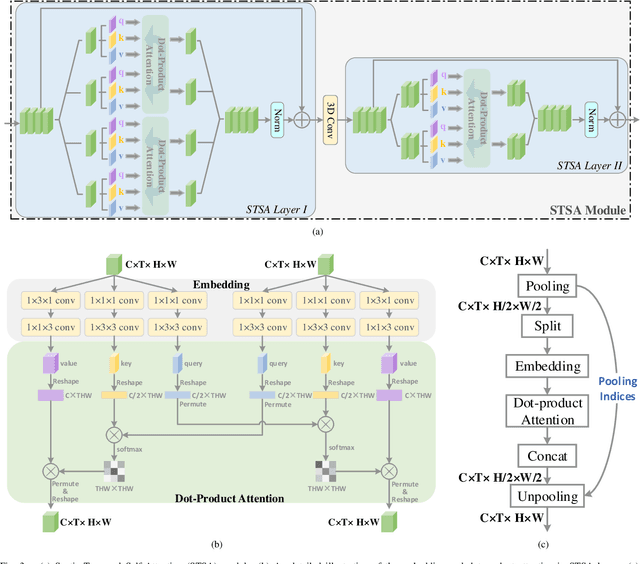
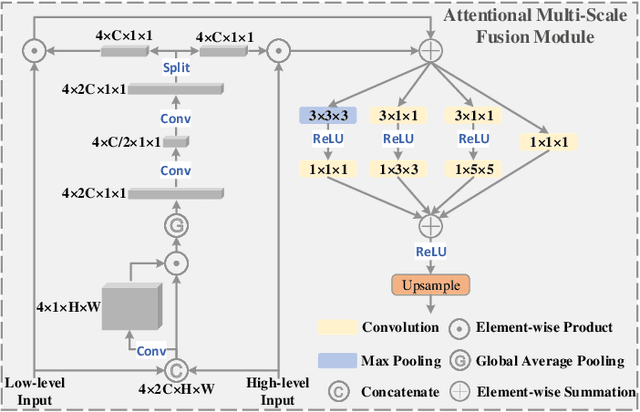
3D convolutional neural networks have achieved promising results for video tasks in computer vision, including video saliency prediction that is explored in this paper. However, 3D convolution encodes visual representation merely on fixed local spacetime according to its kernel size, while human attention is always attracted by relational visual features at different time of a video. To overcome this limitation, we propose a novel Spatio-Temporal Self-Attention 3D Network (STSANet) for video saliency prediction, in which multiple Spatio-Temporal Self-Attention (STSA) modules are employed at different levels of 3D convolutional backbone to directly capture long-range relations between spatio-temporal features of different time steps. Besides, we propose an Attentional Multi-Scale Fusion (AMSF) module to integrate multi-level features with the perception of context in semantic and spatio-temporal subspaces. Extensive experiments demonstrate the contributions of key components of our method, and the results on DHF1K, Hollywood-2, UCF, and DIEM benchmark datasets clearly prove the superiority of the proposed model compared with all state-of-the-art models.
Individual Recognition in Schizophrenia using Deep Learning Methods with Random Forest and Voting Classifiers: Insights from Resting State EEG Streams
Jan 17, 2018
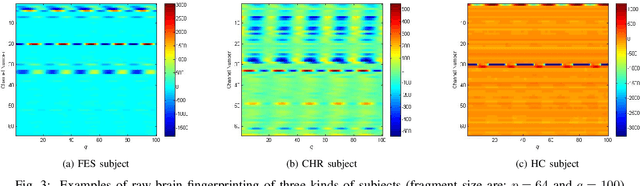
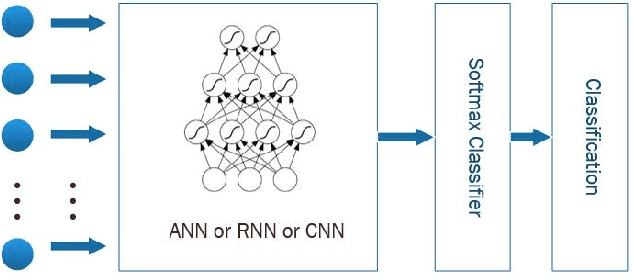
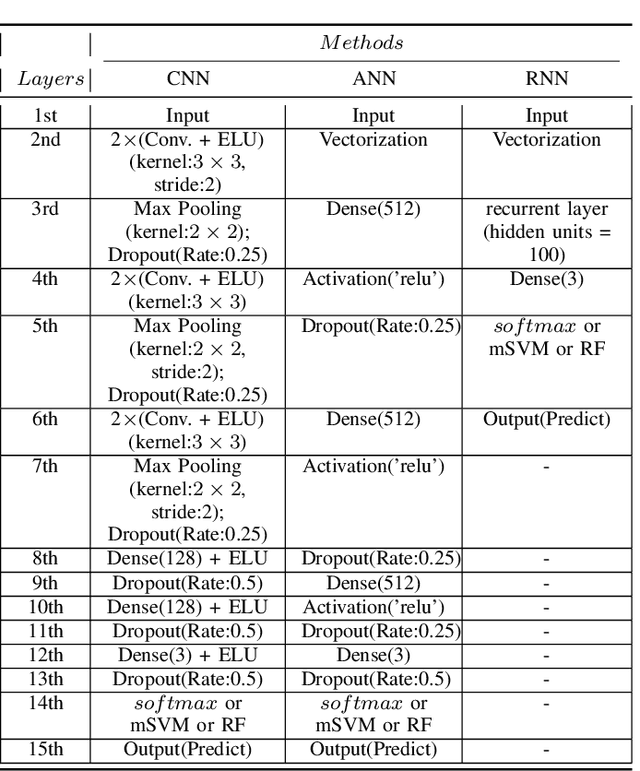
Recently, there has been a growing interest in monitoring brain activity for individual recognition system. So far these works are mainly focussing on single channel data or fragment data collected by some advanced brain monitoring modalities. In this study we propose new individual recognition schemes based on spatio-temporal resting state Electroencephalography (EEG) data. Besides, instead of using features derived from artificially-designed procedures, modified deep learning architectures which aim to automatically extract an individual's unique features are developed to conduct classification. Our designed deep learning frameworks are proved of a small but consistent advantage of replacing the $softmax$ layer with Random Forest. Additionally, a voting layer is added at the top of designed neural networks in order to tackle the classification problem arisen from EEG streams. Lastly, various experiments are implemented to evaluate the performance of the designed deep learning architectures; Results indicate that the proposed EEG-based individual recognition scheme yields a high degree of classification accuracy: $81.6\%$ for characteristics in high risk (CHR) individuals, $96.7\%$ for clinically stable first episode patients with schizophrenia (FES) and $99.2\%$ for healthy controls (HC).