 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Self-Attention Network for Video Saliency Prediction
Aug 24, 2021
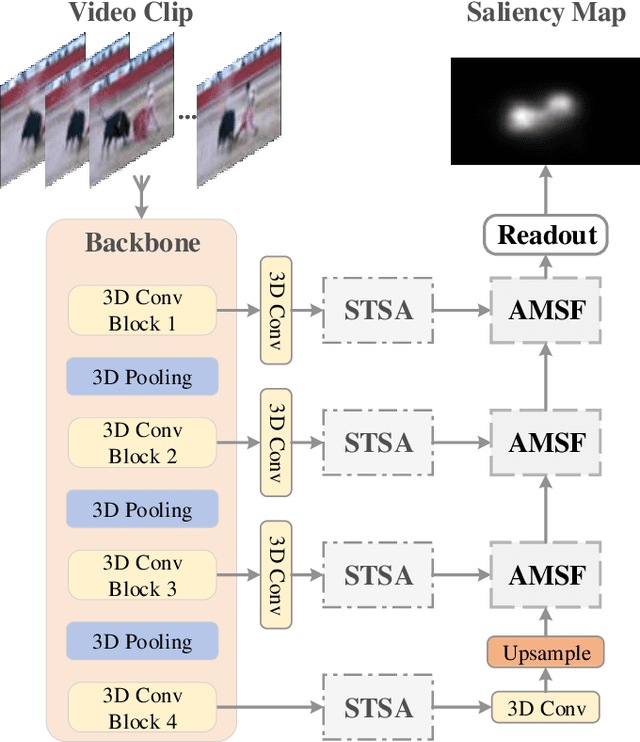
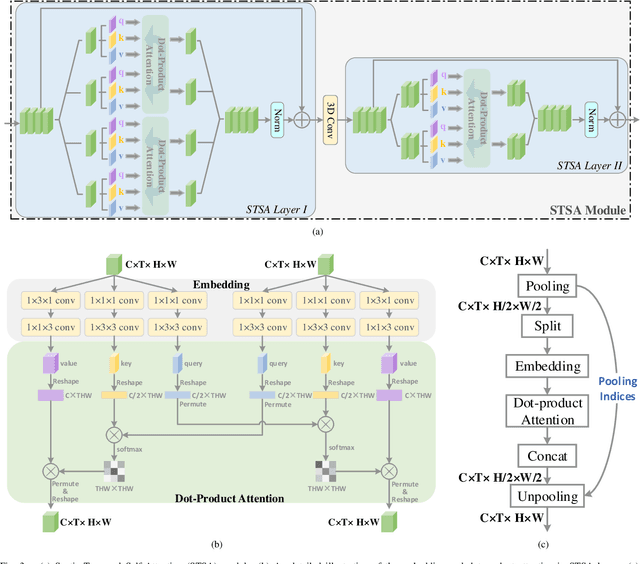
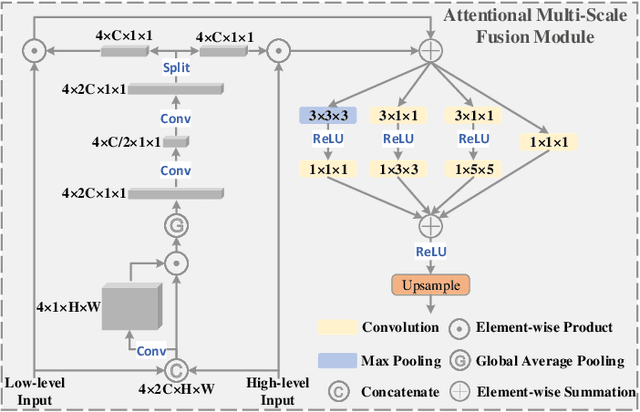
3D convolutional neural networks have achieved promising results for video tasks in computer vision, including video saliency prediction that is explored in this paper. However, 3D convolution encodes visual representation merely on fixed local spacetime according to its kernel size, while human attention is always attracted by relational visual features at different time of a video. To overcome this limitation, we propose a novel Spatio-Temporal Self-Attention 3D Network (STSANet) for video saliency prediction, in which multiple Spatio-Temporal Self-Attention (STSA) modules are employed at different levels of 3D convolutional backbone to directly capture long-range relations between spatio-temporal features of different time steps. Besides, we propose an Attentional Multi-Scale Fusion (AMSF) module to integrate multi-level features with the perception of context in semantic and spatio-temporal subspaces. Extensive experiments demonstrate the contributions of key components of our method, and the results on DHF1K, Hollywood-2, UCF, and DIEM benchmark datasets clearly prove the superiority of the proposed model compared with all state-of-the-art models.