 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasking Stale Observations Helps Search Agents -- Until It Doesn't: A Regime Map and Its Mechanism
May 29, 2026Long-horizon search agents accumulate large amounts of retrieved content across many tool calls, making context-budget efficiency increasingly important. A minimal intervention is to mask stale observations from the context as the trajectory progresses, but it remains unclear when this form of context management helps and why. We study observation masking through a systematic sweep over various agent backbones (4B to 284B parameters) and three retrievers on offline and live-web agentic search benchmarks. We find that the accuracy gain from masking follows an asymmetric inverted-U shape when plotted against the model's accuracy without context management: a plateau under weak retrievers, a peak when a strong retriever meets a mid-capacity model, and a sharp collapse when the model is saturated. This pattern reflects the interaction between retriever recall and the model's implicit filtering capacity, rather than either factor in isolation. Mechanistically, masking implements a token-for-turn trade-off: it removes observations the model has largely stopped attending to and pages the agent rarely re-opens. The added turns help when they convert failures into successes, but they fail when masking removes evidence the model would otherwise have used. We therefore reframe context management as a regime-dependent intervention and provide a holistic perspective for analyzing context use in agentic deep search. We release our scaffold and trajectories here (https://github.com/i-DeepSearch/observation-masking) to support future research.
PointNeRT: A Physics Aware Neural Ray Tracing Surrogate for Propagation Channel Modeling
May 12, 2026Ray tracing (RT) has emerged as a key tool for propagation channel modeling and network planning. Conventional RT is based on electromagnetic (EM) wave theory and its application relies on detailed mesh-based environment representations and material properties. In realistic environments, limited environmental geometry and material uncertainties hinder its scalability to complex scenarios. In this paper, we propose a novel physics aware neural RT surrogate named PointNeRT to address these limitations. The proposed model directly takes point clouds as environmental input, and efficiently reconstruct multipath without explicitly constructing mesh models or manually defining EM interaction rules. PointNeRT adopts a hop-by-hop modeling strategy guided by physical interaction constraints. It supports sequential prediction of multipath propagation and power attenuation. Numerical results and experiments demonstrate that the proposed method implicitly captures surface normal characteristics and EM material effects. It further achieves robust generalization in mobility scenarios and provides a physics-guided neural modeling of multipath propagation.
ReviewGrounder: Improving Review Substantiveness with Rubric-Guided, Tool-Integrated Agents
Apr 15, 2026The rapid rise in AI conference submissions has driven increasing exploration of large language models (LLMs) for peer review support. However, LLM-based reviewers often generate superficial, formulaic comments lacking substantive, evidence-grounded feedback. We attribute this to the underutilization of two key components of human reviewing: explicit rubrics and contextual grounding in existing work. To address this, we introduce REVIEWBENCH, a benchmark evaluating review text according to paper-specific rubrics derived from official guidelines, the paper's content, and human-written reviews. We further propose REVIEWGROUNDER, a rubric-guided, tool-integrated multi-agent framework that decomposes reviewing into drafting and grounding stages, enriching shallow drafts via targeted evidence consolidation. Experiments on REVIEWBENCH show that REVIEWGROUNDER, using a Phi-4-14B-based drafter and a GPT-OSS-120B-based grounding stage, consistently outperforms baselines with substantially stronger/larger backbones (e.g., GPT-4.1 and DeepSeek-R1-670B) in both alignment with human judgments and rubric-based review quality across 8 dimensions. The code is available \href{https://github.com/EigenTom/ReviewGrounder}{here}.
CocoaBench: Evaluating Unified Digital Agents in the Wild
Apr 14, 2026LLM agents now perform strongly in software engineering, deep research, GUI automation, and various other applications, while recent agent scaffolds and models are increasingly integrating these capabilities into unified systems. Yet, most evaluations still test these capabilities in isolation, which leaves a gap for more diverse use cases that require agents to combine different capabilities. We introduce CocoaBench, a benchmark for unified digital agents built from human-designed, long-horizon tasks that require flexible composition of vision, search, and coding. Tasks are specified only by an instruction and an automatic evaluation function over the final output, enabling reliable and scalable evaluation across diverse agent infrastructures. We also present CocoaAgent, a lightweight shared scaffold for controlled comparison across model backbones. Experiments show that current agents remain far from reliable on CocoaBench, with the best evaluated system achieving only 45.1% success rate. Our analysis further points to substantial room for improvement in reasoning and planning, tool use and execution, and visual grounding.
Channel Measurements and Modeling based on Composite Environmental Factor for Urban Street-Canyon Intersections
Apr 02, 2026In urban environments, vehicle-to-everything (V2X) communications require accurate wireless channel characterization. This requirement is particularly critical at street-canyon intersections, where building blockage and rich multipath propagation can severely degrade link reliability. Due to its unique environmental layout, the channel characteristics in urban canyon are influenced by building distribution. However, this feature has not been well captured in existing channel models. In this paper, we propose an environment-related statistical channel model based on 5.8~GHz channel measurements. We construct a composite environmental factor to characterize environmental differences in intersections. Then, the factor is incorporated into 3GPP path-loss model and further linked to small-scale channel parameters. Finally, accuracy of the proposed model is validated using second-order channel statistics. The results show that the proposed model can effectively characterize propagation properties of urban street-canyon intersection channels with different building conditions. The proposed model provides a physically interpretable and statistically effective framework for channel simulation and performance evaluation in urban vehicular scenarios.
AIDev: Studying AI Coding Agents on GitHub
Feb 09, 2026AI coding agents are rapidly transforming software engineering by performing tasks such as feature development, debugging, and testing. Despite their growing impact, the research community lacks a comprehensive dataset capturing how these agents are used in real-world projects. To address this gap, we introduce AIDev, a large-scale dataset focused on agent-authored pull requests (Agentic-PRs) in real-world GitHub repositories. AIDev aggregates 932,791 Agentic-PRs produced by five agents: OpenAI Codex, Devin, GitHub Copilot, Cursor, and Claude Code. These PRs span 116,211 repositories and involve 72,189 developers. In addition, AIDev includes a curated subset of 33,596 Agentic-PRs from 2,807 repositories with over 100 stars, providing further information such as comments, reviews, commits, and related issues. This dataset offers a foundation for future research on AI adoption, developer productivity, and human-AI collaboration in the new era of software engineering. > AI Agent, Agentic AI, Coding Agent, Agentic Coding, Agentic Software Engineering, Agentic Engineering
GR-Dexter Technical Report
Dec 30, 2025Vision-language-action (VLA) models have enabled language-conditioned, long-horizon robot manipulation, but most existing systems are limited to grippers. Scaling VLA policies to bimanual robots with high degree-of-freedom (DoF) dexterous hands remains challenging due to the expanded action space, frequent hand-object occlusions, and the cost of collecting real-robot data. We present GR-Dexter, a holistic hardware-model-data framework for VLA-based generalist manipulation on a bimanual dexterous-hand robot. Our approach combines the design of a compact 21-DoF robotic hand, an intuitive bimanual teleoperation system for real-robot data collection, and a training recipe that leverages teleoperated robot trajectories together with large-scale vision-language and carefully curated cross-embodiment datasets. Across real-world evaluations spanning long-horizon everyday manipulation and generalizable pick-and-place, GR-Dexter achieves strong in-domain performance and improved robustness to unseen objects and unseen instructions. We hope GR-Dexter serves as a practical step toward generalist dexterous-hand robotic manipulation.
Deep Learning Based Dynamic Environment Reconstruction for Vehicular ISAC Scenarios
Aug 07, 2025



Integrated Sensing and Communication (ISAC) technology plays a critical role in future intelligent transportation systems, by enabling vehicles to perceive and reconstruct the surrounding environment through reuse of wireless signals, thereby reducing or even eliminating the need for additional sensors such as LiDAR or radar. However, existing ISAC based reconstruction methods often lack the ability to track dynamic scenes with sufficient accuracy and temporal consistency, limiting the real world applicability. To address this limitation, we propose a deep learning based framework for vehicular environment reconstruction by using ISAC channels. We first establish a joint channel environment dataset based on multi modal measurements from real world urban street scenarios. Then, a multistage deep learning network is developed to reconstruct the environment. Specifically, a scene decoder identifies the environmental context such as buildings, trees and so on; a cluster center decoder predicts coarse spatial layouts by localizing dominant scattering centers; a point cloud decoder recovers fine grained geometry and structure of surrounding environments. Experimental results demonstrate that the proposed method achieves high-quality dynamic environment reconstruction with a Chamfer Distance of 0.29 and F Score@1% of 0.87. In addition, complexity analysis demonstrates the efficiency and practical applicability of the method in real time scenarios. This work provides a pathway toward low cost environment reconstruction based on ISAC for future intelligent transportation.
The Hitchhikers Guide to Production-ready Trustworthy Foundation Model powered Software (FMware)
May 15, 2025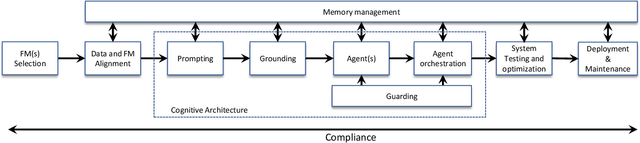
Foundation Models (FMs) such as Large Language Models (LLMs) are reshaping the software industry by enabling FMware, systems that integrate these FMs as core components. In this KDD 2025 tutorial, we present a comprehensive exploration of FMware that combines a curated catalogue of challenges with real-world production concerns. We first discuss the state of research and practice in building FMware. We further examine the difficulties in selecting suitable models, aligning high-quality domain-specific data, engineering robust prompts, and orchestrating autonomous agents. We then address the complex journey from impressive demos to production-ready systems by outlining issues in system testing, optimization, deployment, and integration with legacy software. Drawing on our industrial experience and recent research in the area, we provide actionable insights and a technology roadmap for overcoming these challenges. Attendees will gain practical strategies to enable the creation of trustworthy FMware in the evolving technology landscape.
A Microgravity Simulation Experimental Platform For Small Space Robots In Orbit
Apr 26, 2025This study describes the development and validation of a novel microgravity experimental platform that is mainly applied to small robots such as modular self-reconfigurable robots. This platform mainly consists of an air supply system, a microporous platform and glass. By supplying air to the microporous platform to form an air film, the influence of the weight of the air foot and the ventilation hose of traditional air-float platforms on microgravity experiments is solved. The contribution of this work is to provide a platform with less external interference for microgravity simulation experiments on small robots.