 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoCo Challenge at AAAI 2026: Benchmarking Robotic Collaborative Manipulation for Assembly Towards Industrial Automation
Mar 16, 2026Embodied Artificial Intelligence (EAI) is rapidly developing, gradually subverting previous autonomous systems' paradigms from isolated perception to integrated, continuous action. This transition is highly significant for industrial robotic manipulation, promising to free human workers from repetitive, dangerous daily labor. To benchmark and advance this capability, we introduce the Robotic Collaborative Assembly Assistance (RoCo) Challenge with a dataset towards simulation and real-world assembly manipulation. Set against the backdrop of human-centered manufacturing, this challenge focuses on a high-precision planetary gearbox assembly task, a demanding yet highly representative operation in modern industry. Built upon a self-developed data collection, training, and evaluation system in Isaac Sim, and utilizing a dual-arm robot for real-world deployment, the challenge operates in two phases. The Simulation Round defines fine-grained task phases for step-wise scoring to handle the long-horizon nature of the assembly. The Real-World Round mirrors this evaluation with physical gearbox components and high-quality teleoperated datasets. The core tasks require assembling an epicyclic gearbox from scratch, including mounting three planet gears, a sun gear, and a ring gear. Attracting over 60 teams and 170+ participants from more than 10 countries, the challenge yielded highly effective solutions, most notably ARC-VLA and RoboCola. Results demonstrate that a dual-model framework for long-horizon multi-task learning is highly effective, and the strategic utilization of recovery-from-failure curriculum data is a critical insight for successful deployment. This report outlines the competition setup, evaluation approach, key findings, and future directions for industrial EAI. Our dataset, CAD files, code, and evaluation results can be found at: https://rocochallenge.github.io/RoCo2026/.
Unleashing Low-Bit Inference on Ascend NPUs: A Comprehensive Evaluation of HiFloat Formats
Feb 13, 2026As LLMs scale, low-bit floating-point formats like MXFP and NVFP4 offer new opportunities for precision and efficiency. In this work, we evaluate HiFloat (HiF8 and HiF4), a family of formats tailored for Ascend NPUs. Through rigorous comparison across weight-activation and KV-cache tasks, we provide three key insights: (1) INT8 suits narrow-range data, while floating-point formats excel with high-variance data; (2) in 4-bit regimes, HiF4's hierarchical scaling prevents the accuracy collapse seen in integer formats; and (3) HiFloat is fully compatible with state-of-the-art post-training quantization frameworks. Overall, HiFloat provides a solution for high-efficiency LLM inference on NPUs.
Towards Efficient Agents: A Co-Design of Inference Architecture and System
Dec 20, 2025The rapid development of large language model (LLM)-based agents has unlocked new possibilities for autonomous multi-turn reasoning and tool-augmented decision-making. However, their real-world deployment is hindered by severe inefficiencies that arise not from isolated model inference, but from the systemic latency accumulated across reasoning loops, context growth, and heterogeneous tool interactions. This paper presents AgentInfer, a unified framework for end-to-end agent acceleration that bridges inference optimization and architectural design. We decompose the problem into four synergistic components: AgentCollab, a hierarchical dual-model reasoning framework that balances large- and small-model usage through dynamic role assignment; AgentSched, a cache-aware hybrid scheduler that minimizes latency under heterogeneous request patterns; AgentSAM, a suffix-automaton-based speculative decoding method that reuses multi-session semantic memory to achieve low-overhead inference acceleration; and AgentCompress, a semantic compression mechanism that asynchronously distills and reorganizes agent memory without disrupting ongoing reasoning. Together, these modules form a Self-Evolution Engine capable of sustaining efficiency and cognitive stability throughout long-horizon reasoning tasks. Experiments on the BrowseComp-zh and DeepDiver benchmarks demonstrate that through the synergistic collaboration of these methods, AgentInfer reduces ineffective token consumption by over 50%, achieving an overall 1.8-2.5 times speedup with preserved accuracy. These results underscore that optimizing for agentic task completion-rather than merely per-token throughput-is the key to building scalable, efficient, and self-improving intelligent systems.
TrimR: Verifier-based Training-Free Thinking Compression for Efficient Test-Time Scaling
May 22, 2025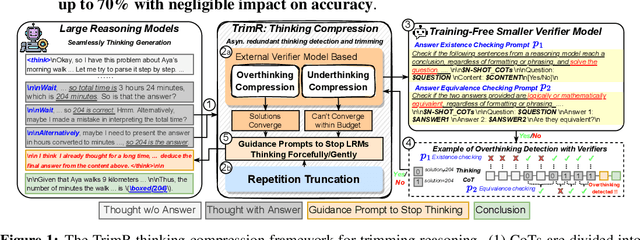
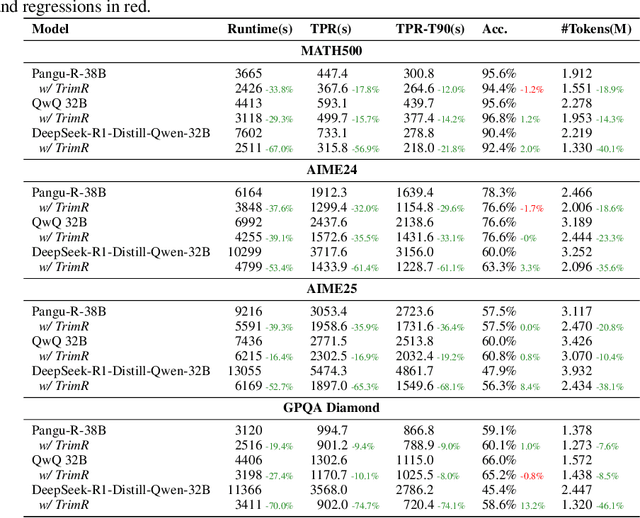
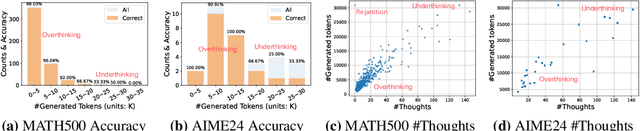
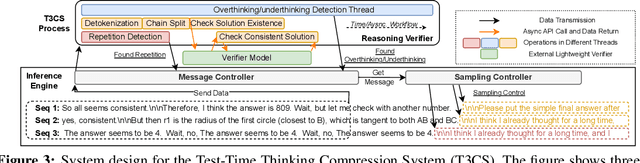
Large Reasoning Models (LRMs) demonstrate exceptional capability in tackling complex mathematical, logical, and coding tasks by leveraging extended Chain-of-Thought (CoT) reasoning. Test-time scaling methods, such as prolonging CoT with explicit token-level exploration, can push LRMs' accuracy boundaries, but they incur significant decoding overhead. A key inefficiency source is LRMs often generate redundant thinking CoTs, which demonstrate clear structured overthinking and underthinking patterns. Inspired by human cognitive reasoning processes and numerical optimization theories, we propose TrimR, a verifier-based, training-free, efficient framework for dynamic CoT compression to trim reasoning and enhance test-time scaling, explicitly tailored for production-level deployment. Our method employs a lightweight, pretrained, instruction-tuned verifier to detect and truncate redundant intermediate thoughts of LRMs without any LRM or verifier fine-tuning. We present both the core algorithm and asynchronous online system engineered for high-throughput industrial applications. Empirical evaluations on Ascend NPUs and vLLM show that our framework delivers substantial gains in inference efficiency under large-batch workloads. In particular, on the four MATH500, AIME24, AIME25, and GPQA benchmarks, the reasoning runtime of Pangu-R-38B, QwQ-32B, and DeepSeek-R1-Distill-Qwen-32B is improved by up to 70% with negligible impact on accuracy.
A Microgravity Simulation Experimental Platform For Small Space Robots In Orbit
Apr 26, 2025This study describes the development and validation of a novel microgravity experimental platform that is mainly applied to small robots such as modular self-reconfigurable robots. This platform mainly consists of an air supply system, a microporous platform and glass. By supplying air to the microporous platform to form an air film, the influence of the weight of the air foot and the ventilation hose of traditional air-float platforms on microgravity experiments is solved. The contribution of this work is to provide a platform with less external interference for microgravity simulation experiments on small robots.
Human-aligned Safe Reinforcement Learning for Highway On-Ramp Merging in Dense Traffic
Mar 04, 2025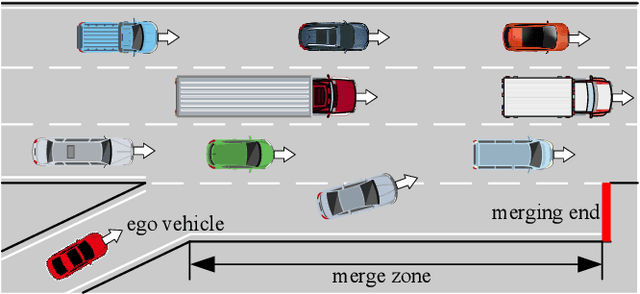
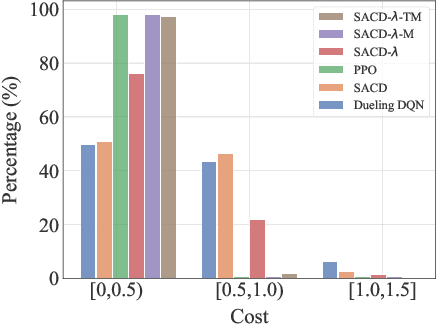
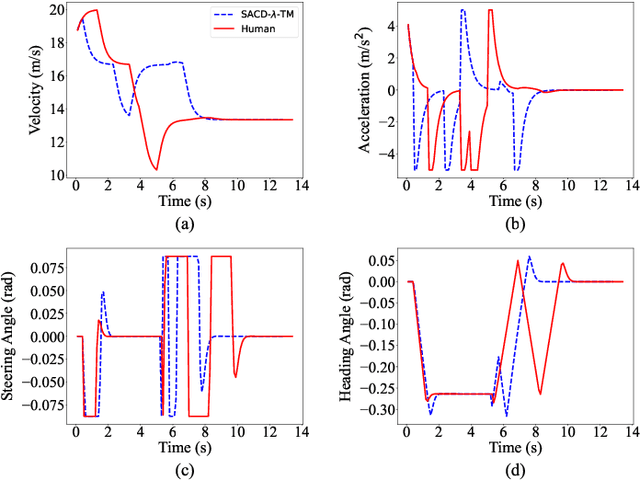
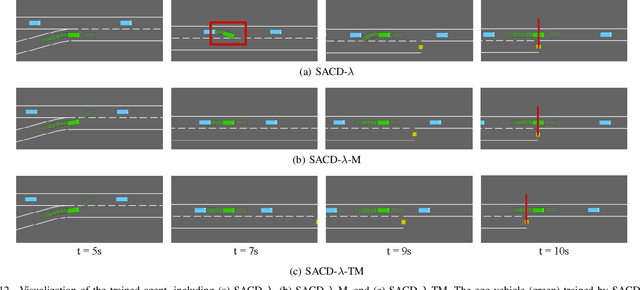
Most reinforcement learning (RL) approaches for the decision-making of autonomous driving consider safety as a reward instead of a cost, which makes it hard to balance the tradeoff between safety and other objectives. Human risk preference has also rarely been incorporated, and the trained policy might be either conservative or aggressive for users. To this end, this study proposes a human-aligned safe RL approach for autonomous merging, in which the high-level decision problem is formulated as a constrained Markov decision process (CMDP) that incorporates users' risk preference into the safety constraints, followed by a model predictive control (MPC)-based low-level control. The safety level of RL policy can be adjusted by computing cost limits of CMDP's constraints based on risk preferences and traffic density using a fuzzy control method. To filter out unsafe or invalid actions, we design an action shielding mechanism that pre-executes RL actions using an MPC method and performs collision checks with surrounding agents. We also provide theoretical proof to validate the effectiveness of the shielding mechanism in enhancing RL's safety and sample efficiency. Simulation experiments in multiple levels of traffic densities show that our method can significantly reduce safety violations without sacrificing traffic efficiency. Furthermore, due to the use of risk preference-aware constraints in CMDP and action shielding, we can not only adjust the safety level of the final policy but also reduce safety violations during the training stage, proving a promising solution for online learning in real-world environments.
LAION-SG: An Enhanced Large-Scale Dataset for Training Complex Image-Text Models with Structural Annotations
Dec 11, 2024



Recent advances in text-to-image (T2I) generation have shown remarkable success in producing high-quality images from text. However, existing T2I models show decayed performance in compositional image generation involving multiple objects and intricate relationships. We attribute this problem to limitations in existing datasets of image-text pairs, which lack precise inter-object relationship annotations with prompts only. To address this problem, we construct LAION-SG, a large-scale dataset with high-quality structural annotations of scene graphs (SG), which precisely describe attributes and relationships of multiple objects, effectively representing the semantic structure in complex scenes. Based on LAION-SG, we train a new foundation model SDXL-SG to incorporate structural annotation information into the generation process. Extensive experiments show advanced models trained on our LAION-SG boast significant performance improvements in complex scene generation over models on existing datasets. We also introduce CompSG-Bench, a benchmark that evaluates models on compositional image generation, establishing a new standard for this domain.
Distribution Backtracking Builds A Faster Convergence Trajectory for One-step Diffusion Distillation
Aug 28, 2024



Accelerating the sampling speed of diffusion models remains a significant challenge. Recent score distillation methods distill a heavy teacher model into an one-step student generator, which is optimized by calculating the difference between the two score functions on the samples generated by the student model. However, there is a score mismatch issue in the early stage of the distillation process, because existing methods mainly focus on using the endpoint of pre-trained diffusion models as teacher models, overlooking the importance of the convergence trajectory between the student generator and the teacher model. To address this issue, we extend the score distillation process by introducing the entire convergence trajectory of teacher models and propose Distribution Backtracking Distillation (DisBack) for distilling student generators. DisBask is composed of two stages: Degradation Recording and Distribution Backtracking. Degradation Recording is designed to obtain the convergence trajectory of teacher models, which records the degradation path from the trained teacher model to the untrained initial student generator. The degradation path implicitly represents the intermediate distributions of teacher models. Then Distribution Backtracking trains a student generator to backtrack the intermediate distributions for approximating the convergence trajectory of teacher models. Extensive experiments show that DisBack achieves faster and better convergence than the existing distillation method and accomplishes comparable generation performance. Notably, DisBack is easy to implement and can be generalized to existing distillation methods to boost performance. Our code is publicly available on https://github.com/SYZhang0805/DisBack.
ETSCL: An Evidence Theory-Based Supervised Contrastive Learning Framework for Multi-modal Glaucoma Grading
Jul 19, 2024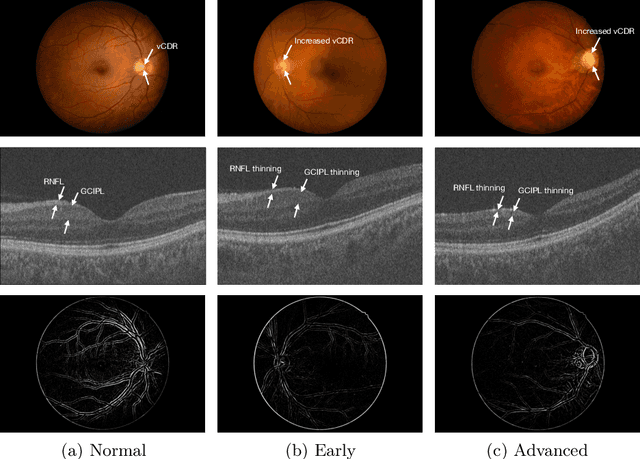

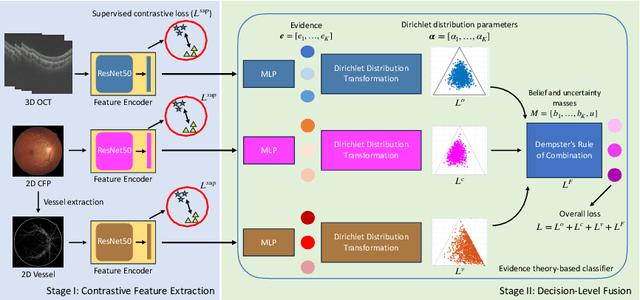
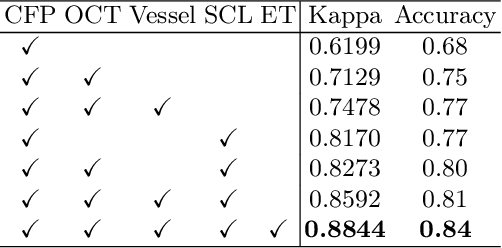
Glaucoma is one of the leading causes of vision impairment. Digital imaging techniques, such as color fundus photography (CFP) and optical coherence tomography (OCT), provide quantitative and noninvasive methods for glaucoma diagnosis. Recently, in the field of computer-aided glaucoma diagnosis, multi-modality methods that integrate the CFP and OCT modalities have achieved greater diagnostic accuracy compared to single-modality methods. However, it remains challenging to extract reliable features due to the high similarity of medical images and the unbalanced multi-modal data distribution. Moreover, existing methods overlook the uncertainty estimation of different modalities, leading to unreliable predictions. To address these challenges, we propose a novel framework, namely ETSCL, which consists of a contrastive feature extraction stage and a decision-level fusion stage. Specifically, the supervised contrastive loss is employed to enhance the discriminative power in the feature extraction process, resulting in more effective features. In addition, we utilize the Frangi vesselness algorithm as a preprocessing step to incorporate vessel information to assist in the prediction. In the decision-level fusion stage, an evidence theory-based multi-modality classifier is employed to combine multi-source information with uncertainty estimation. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The code is available at \url{https://github.com/master-Shix/ETSCL}.
Edge-guided and Cross-scale Feature Fusion Network for Efficient Multi-contrast MRI Super-Resolution
Jul 07, 2024



In recent years, MRI super-resolution techniques have achieved great success, especially multi-contrast methods that extract texture information from reference images to guide the super-resolution reconstruction. However, current methods primarily focus on texture similarities at the same scale, neglecting cross-scale similarities that provide comprehensive information. Moreover, the misalignment between features of different scales impedes effective aggregation of information flow. To address the limitations, we propose a novel edge-guided and cross-scale feature fusion network, namely ECFNet. Specifically, we develop a pipeline consisting of the deformable convolution and the cross-attention transformer to align features of different scales. The cross-scale fusion strategy fully integrates the texture information from different scales, significantly enhancing the super-resolution. In addition, a novel structure information collaboration module is developed to guide the super-resolution reconstruction with implicit structure priors. The structure information enables the network to focus on high-frequency components of the image, resulting in sharper details. Extensive experiments on the IXI and BraTS2020 datasets demonstrate that our method achieves state-of-the-art performance compared to other multi-contrast MRI super-resolution methods, and our method is robust in terms of different super-resolution scales. We would like to release our code and pre-trained model after the paper is accepted.