 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReIDMamba: Learning Discriminative Features with Visual State Space Model for Person Re-Identification
Nov 11, 2025Extracting robust discriminative features is a critical challenge in person re-identification (ReID). While Transformer-based methods have successfully addressed some limitations of convolutional neural networks (CNNs), such as their local processing nature and information loss resulting from convolution and downsampling operations, they still face the scalability issue due to the quadratic increase in memory and computational requirements with the length of the input sequence. To overcome this, we propose a pure Mamba-based person ReID framework named ReIDMamba. Specifically, we have designed a Mamba-based strong baseline that effectively leverages fine-grained, discriminative global features by introducing multiple class tokens. To further enhance robust features learning within Mamba, we have carefully designed two novel techniques. First, the multi-granularity feature extractor (MGFE) module, designed with a multi-branch architecture and class token fusion, effectively forms multi-granularity features, enhancing both discrimination ability and fine-grained coverage. Second, the ranking-aware triplet regularization (RATR) is introduced to reduce redundancy in features from multiple branches, enhancing the diversity of multi-granularity features by incorporating both intra-class and inter-class diversity constraints, thus ensuring the robustness of person features. To our knowledge, this is the pioneering work that integrates a purely Mamba-driven approach into ReID research. Our proposed ReIDMamba model boasts only one-third the parameters of TransReID, along with lower GPU memory usage and faster inference throughput. Experimental results demonstrate ReIDMamba's superior and promising performance, achieving state-of-the-art performance on five person ReID benchmarks. Code is available at https://github.com/GuHY777/ReIDMamba.
Human-aligned Safe Reinforcement Learning for Highway On-Ramp Merging in Dense Traffic
Mar 04, 2025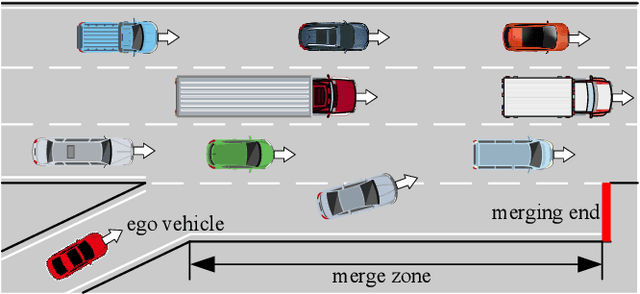
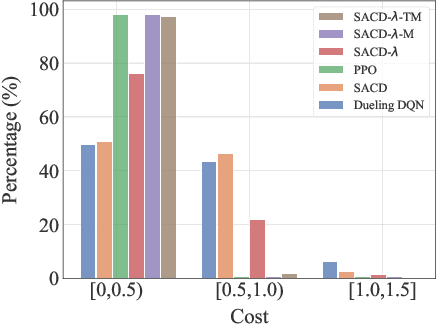
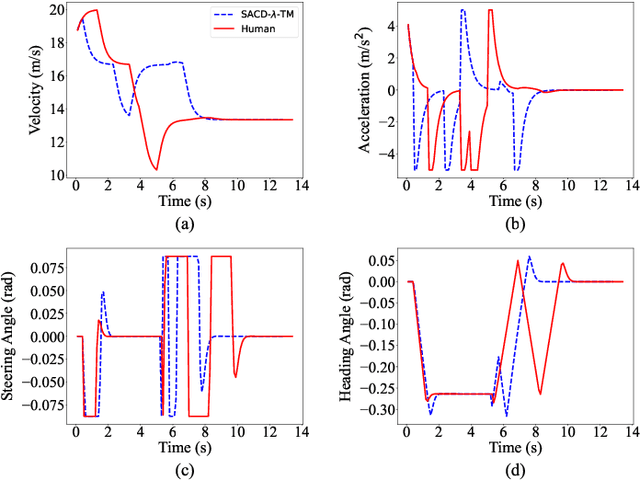
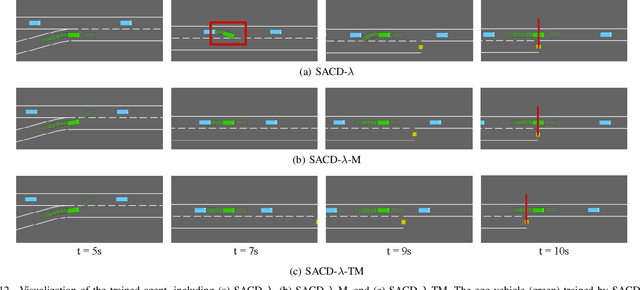
Most reinforcement learning (RL) approaches for the decision-making of autonomous driving consider safety as a reward instead of a cost, which makes it hard to balance the tradeoff between safety and other objectives. Human risk preference has also rarely been incorporated, and the trained policy might be either conservative or aggressive for users. To this end, this study proposes a human-aligned safe RL approach for autonomous merging, in which the high-level decision problem is formulated as a constrained Markov decision process (CMDP) that incorporates users' risk preference into the safety constraints, followed by a model predictive control (MPC)-based low-level control. The safety level of RL policy can be adjusted by computing cost limits of CMDP's constraints based on risk preferences and traffic density using a fuzzy control method. To filter out unsafe or invalid actions, we design an action shielding mechanism that pre-executes RL actions using an MPC method and performs collision checks with surrounding agents. We also provide theoretical proof to validate the effectiveness of the shielding mechanism in enhancing RL's safety and sample efficiency. Simulation experiments in multiple levels of traffic densities show that our method can significantly reduce safety violations without sacrificing traffic efficiency. Furthermore, due to the use of risk preference-aware constraints in CMDP and action shielding, we can not only adjust the safety level of the final policy but also reduce safety violations during the training stage, proving a promising solution for online learning in real-world environments.
Analyzing Generalization in Policy Networks: A Case Study with the Double-Integrator System
Dec 31, 2023



Extensive utilization of deep reinforcement learning (DRL) policy networks in diverse continuous control tasks has raised questions regarding performance degradation in expansive state spaces where the input state norm is larger than that in the training environment. This paper aims to uncover the underlying factors contributing to such performance deterioration when dealing with expanded state spaces, using a novel analysis technique known as state division. In contrast to prior approaches that employ state division merely as a post-hoc explanatory tool, our methodology delves into the intrinsic characteristics of DRL policy networks. Specifically, we demonstrate that the expansion of state space induces the activation function $\tanh$ to exhibit saturability, resulting in the transformation of the state division boundary from nonlinear to linear. Our analysis centers on the paradigm of the double-integrator system, revealing that this gradual shift towards linearity imparts a control behavior reminiscent of bang-bang control. However, the inherent linearity of the division boundary prevents the attainment of an ideal bang-bang control, thereby introducing unavoidable overshooting. Our experimental investigations, employing diverse RL algorithms, establish that this performance phenomenon stems from inherent attributes of the DRL policy network, remaining consistent across various optimization algorithms.
Reinforcement Learning by Guided Safe Exploration
Jul 26, 2023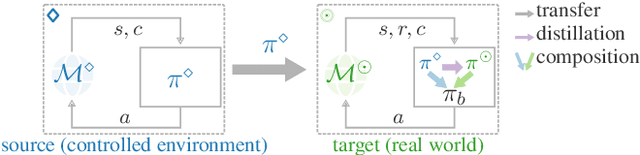
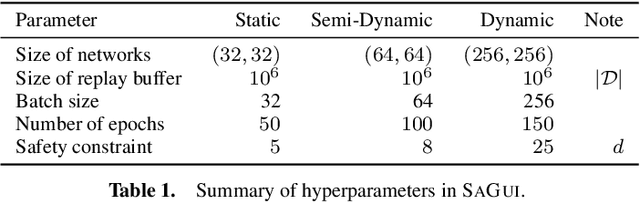
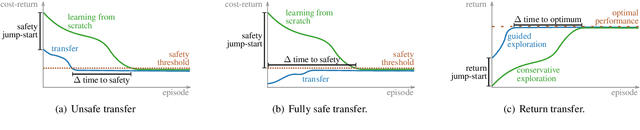
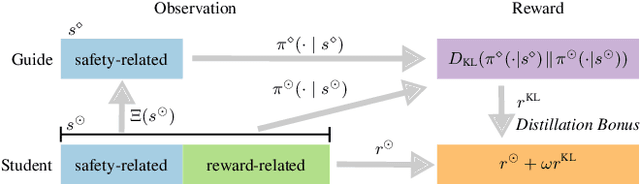
Safety is critical to broadening the application of reinforcement learning (RL). Often, we train RL agents in a controlled environment, such as a laboratory, before deploying them in the real world. However, the real-world target task might be unknown prior to deployment. Reward-free RL trains an agent without the reward to adapt quickly once the reward is revealed. We consider the constrained reward-free setting, where an agent (the guide) learns to explore safely without the reward signal. This agent is trained in a controlled environment, which allows unsafe interactions and still provides the safety signal. After the target task is revealed, safety violations are not allowed anymore. Thus, the guide is leveraged to compose a safe behaviour policy. Drawing from transfer learning, we also regularize a target policy (the student) towards the guide while the student is unreliable and gradually eliminate the influence of the guide as training progresses. The empirical analysis shows that this method can achieve safe transfer learning and helps the student solve the target task faster.