 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLMC-based Resource Adequacy Assessment with Active Learning Trained Surrogate Models
May 27, 2025



Multilevel Monte Carlo (MLMC) is a flexible and effective variance reduction technique for accelerating reliability assessments of complex power system. Recently, data-driven surrogate models have been proposed as lower-level models in the MLMC framework due to their high correlation and negligible execution time once trained. However, in resource adequacy assessments, pre-labeled datasets are typically unavailable. For large-scale systems, the efficiency gains from surrogate models are often offset by the substantial time required for labeling training data. Therefore, this paper introduces a speed metric that accounts for training time in evaluating MLMC efficiency. Considering the total time budget is limited, a vote-by-committee active learning approach is proposed to reduce the required labeling calls. A case study demonstrates that, within practical variance thresholds, active learning enables significantly improved MLMC efficiency with reduced training effort, compared to regular surrogate modelling approaches.
Stable Training of Probabilistic Models Using the Leave-One-Out Maximum Log-Likelihood Objective
Oct 05, 2023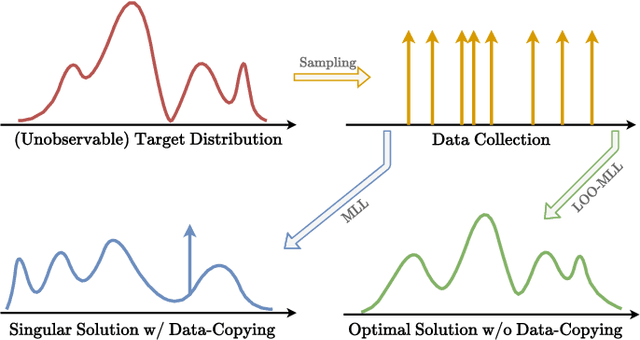
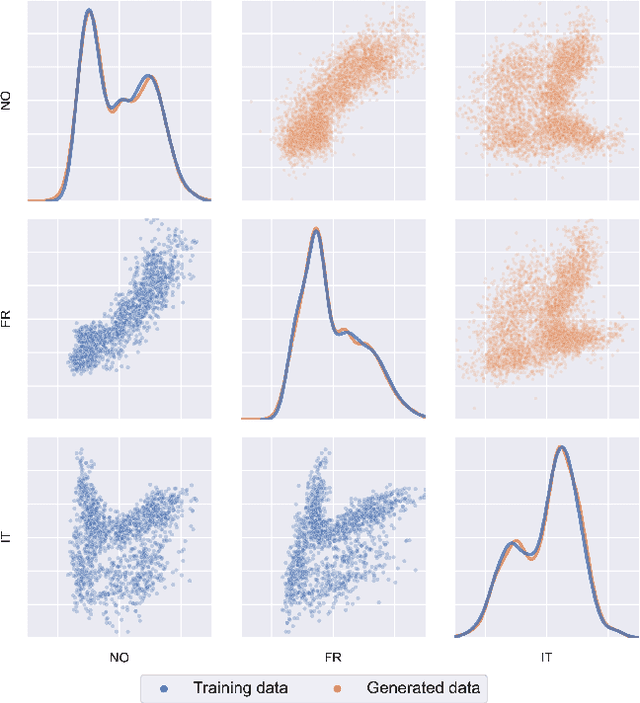
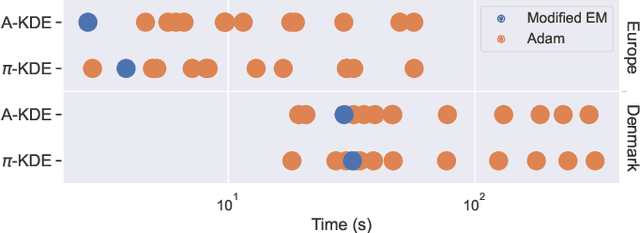
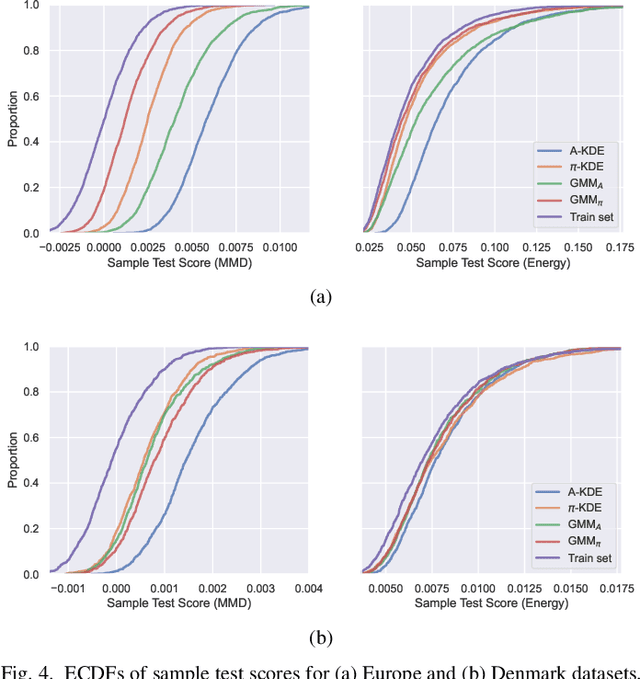
Probabilistic modelling of power systems operation and planning processes depends on data-driven methods, which require sufficiently large datasets. When historical data lacks this, it is desired to model the underlying data generation mechanism as a probability distribution to assess the data quality and generate more data, if needed. Kernel density estimation (KDE) based models are popular choices for this task, but they fail to adapt to data regions with varying densities. In this paper, an adaptive KDE model is employed to circumvent this, where each kernel in the model has an individual bandwidth. The leave-one-out maximum log-likelihood (LOO-MLL) criterion is proposed to prevent the singular solutions that the regular MLL criterion gives rise to, and it is proven that LOO-MLL prevents these. Relying on this guaranteed robustness, the model is extended by assigning learnable weights to the kernels. In addition, a modified expectation-maximization algorithm is employed to accelerate the optimization speed reliably. The performance of the proposed method and models are exhibited on two power systems datasets using different statistical tests and by comparison with Gaussian mixture models. Results show that the proposed models have promising performance, in addition to their singularity prevention guarantees.
Reinforcement Learning by Guided Safe Exploration
Jul 26, 2023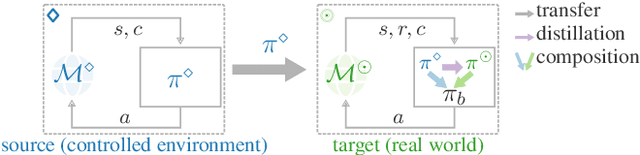
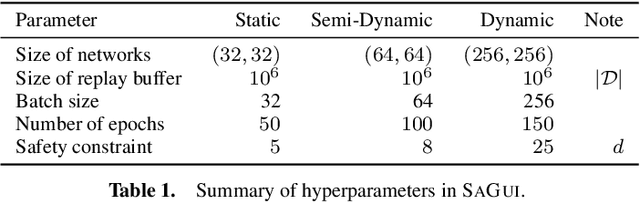
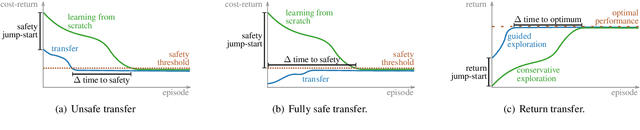
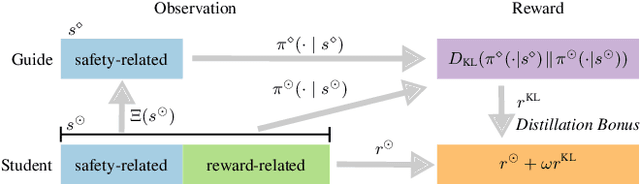
Safety is critical to broadening the application of reinforcement learning (RL). Often, we train RL agents in a controlled environment, such as a laboratory, before deploying them in the real world. However, the real-world target task might be unknown prior to deployment. Reward-free RL trains an agent without the reward to adapt quickly once the reward is revealed. We consider the constrained reward-free setting, where an agent (the guide) learns to explore safely without the reward signal. This agent is trained in a controlled environment, which allows unsafe interactions and still provides the safety signal. After the target task is revealed, safety violations are not allowed anymore. Thus, the guide is leveraged to compose a safe behaviour policy. Drawing from transfer learning, we also regularize a target policy (the student) towards the guide while the student is unreliable and gradually eliminate the influence of the guide as training progresses. The empirical analysis shows that this method can achieve safe transfer learning and helps the student solve the target task faster.
Targeted Analysis of High-Risk States Using an Oriented Variational Autoencoder
Mar 20, 2023Variational autoencoder (VAE) neural networks can be trained to generate power system states that capture both marginal distribution and multivariate dependencies of historical data. The coordinates of the latent space codes of VAEs have been shown to correlate with conceptual features of the data, which can be leveraged to synthesize targeted data with desired features. However, the locations of the VAEs' latent space codes that correspond to specific properties are not constrained. Additionally, the generation of data with specific characteristics may require data with corresponding hard-to-get labels fed into the generative model for training. In this paper, to make data generation more controllable and efficient, an oriented variation autoencoder (OVAE) is proposed to constrain the link between latent space code and generated data in the form of a Spearman correlation, which provides increased control over the data synthesis process. On this basis, an importance sampling process is used to sample data in the latent space. Two cases are considered for testing the performance of the OVAE model: the data set is fully labeled with approximate information and the data set is incompletely labeled but with more accurate information. The experimental results show that, in both cases, the OVAE model correlates latent space codes with the generated data, and the efficiency of generating targeted samples is significantly improved.
Generating Contextual Load Profiles Using a Conditional Variational Autoencoder
Sep 08, 2022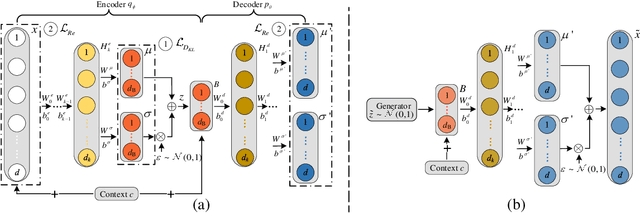
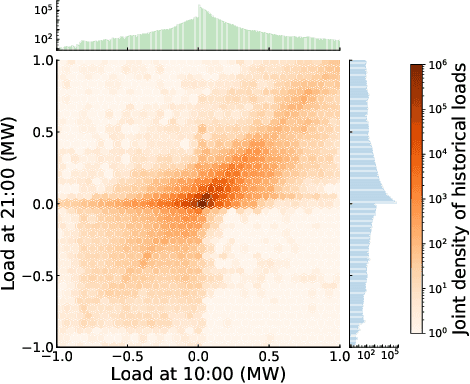
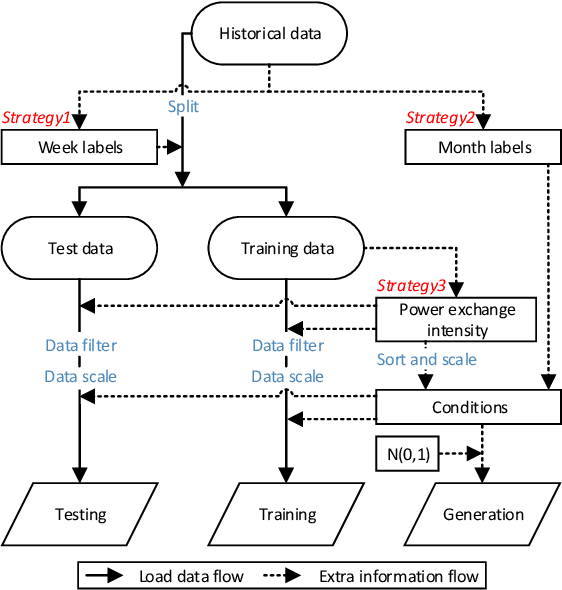
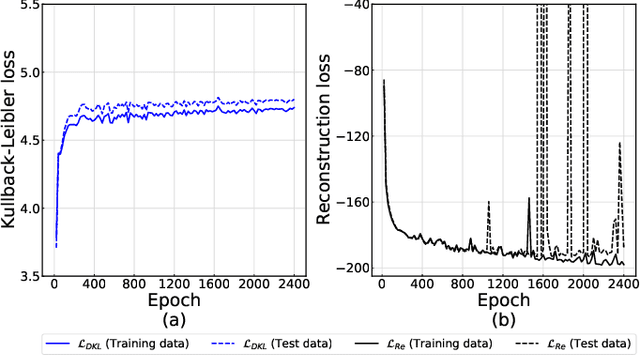
Generating power system states that have similar distribution and dependency to the historical ones is essential for the tasks of system planning and security assessment, especially when the historical data is insufficient. In this paper, we described a generative model for load profiles of industrial and commercial customers, based on the conditional variational autoencoder (CVAE) neural network architecture, which is challenging due to the highly variable nature of such profiles. Generated contextual load profiles were conditioned on the month of the year and typical power exchange with the grid. Moreover, the quality of generations was both visually and statistically evaluated. The experimental results demonstrate our proposed CVAE model can capture temporal features of historical load profiles and generate `realistic' data with satisfying univariate distributions and multivariate dependencies.
Generating Multivariate Load States Using a Conditional Variational Autoencoder
Oct 21, 2021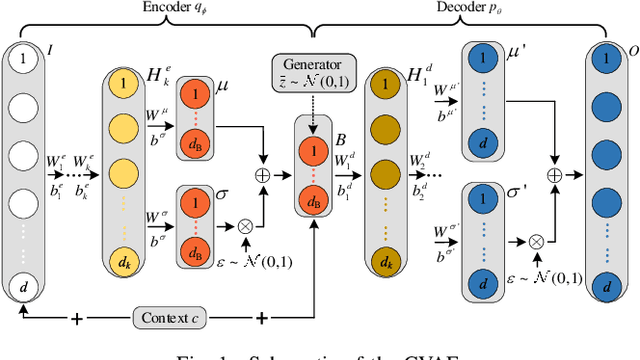
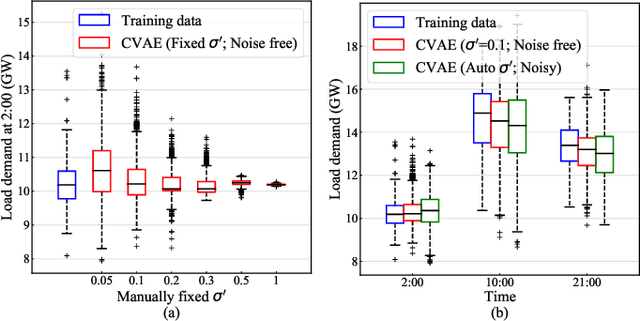
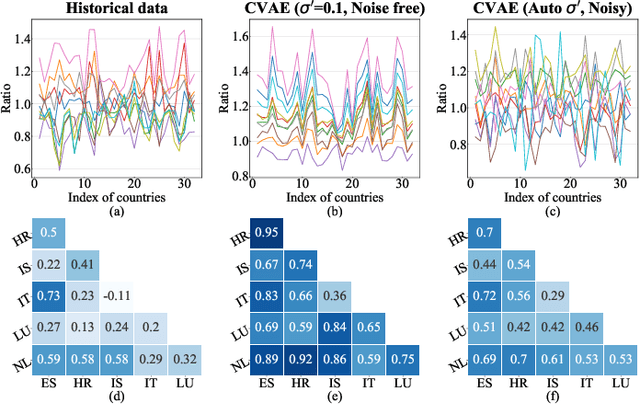
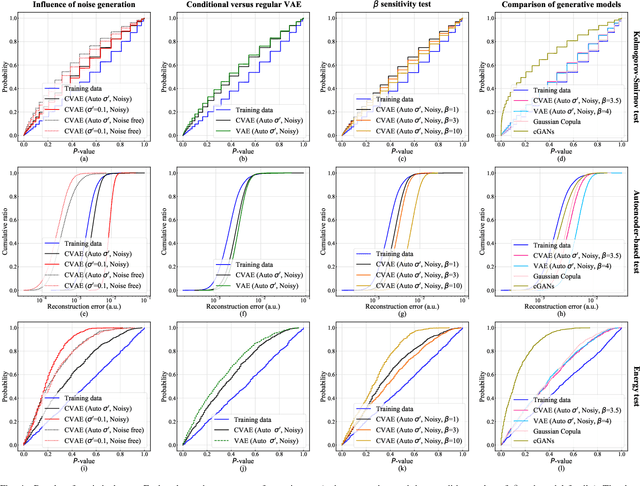
For planning of power systems and for the calibration of operational tools, it is essential to analyse system performance in a large range of representative scenarios. When the available historical data is limited, generative models are a promising solution, but modelling high-dimensional dependencies is challenging. In this paper, a multivariate load state generating model on the basis of a conditional variational autoencoder (CVAE) neural network is proposed. Going beyond common CVAE implementations, the model includes stochastic variation of output samples under given latent vectors and co-optimizes the parameters for this output variability. It is shown that this improves statistical properties of the generated data. The quality of generated multivariate loads is evaluated using univariate and multivariate performance metrics. A generation adequacy case study on the European network is used to illustrate model's ability to generate realistic tail distributions. The experiments demonstrate that the proposed generator outperforms other data generating mechanisms.
Sample-Derived Disjunctive Rules for Secure Power System Operation
Apr 09, 2018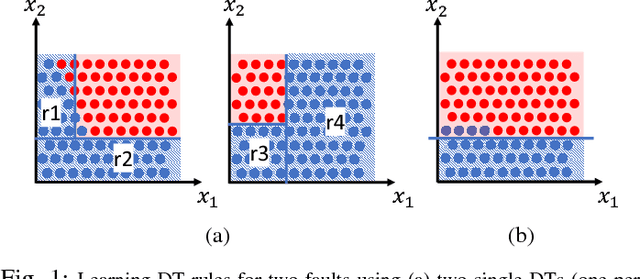
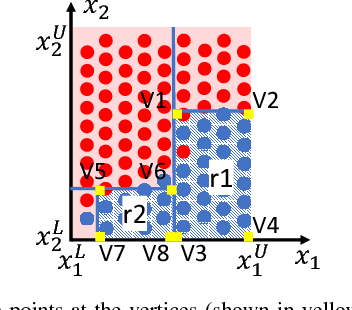
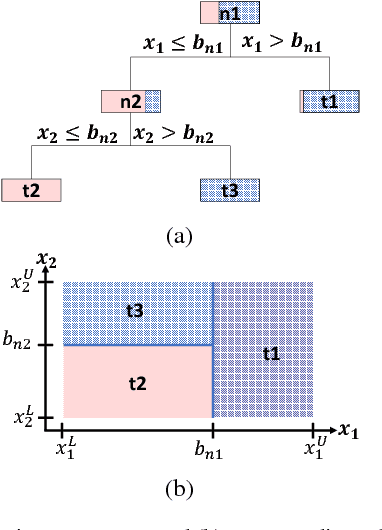
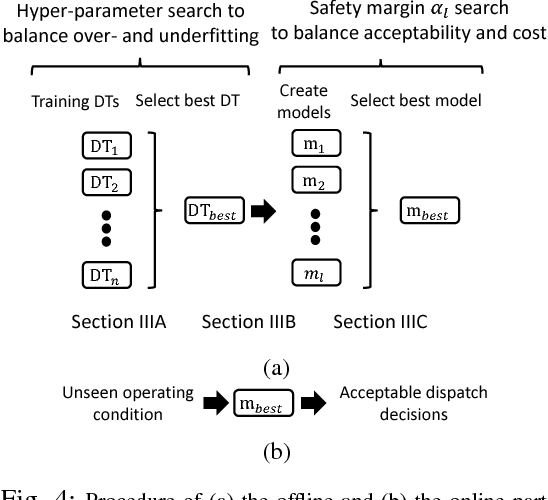
Machine learning techniques have been used in the past using Monte Carlo samples to construct predictors of the dynamic stability of power systems. In this paper we move beyond the task of prediction and propose a comprehensive approach to use predictors, such as Decision Trees (DT), within a standard optimization framework for pre- and post-fault control purposes. In particular, we present a generalizable method for embedding rules derived from DTs in an operation decision-making model. We begin by pointing out the specific challenges entailed when moving from a prediction to a control framework. We proceed with introducing the solution strategy based on generalized disjunctive programming (GDP) as well as a two-step search method for identifying optimal hyper-parameters for balancing cost and control accuracy. We showcase how the proposed approach constructs security proxies that cover multiple contingencies while facing high-dimensional uncertainty with respect to operating conditions with the use of a case study on the IEEE 39-bus system. The method is shown to achieve efficient system control at a marginal increase in system price compared to an oracle model.