 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelizing Tree Search with Twice Sequential Monte Carlo
Nov 18, 2025Model-based reinforcement learning (RL) methods that leverage search are responsible for many milestone breakthroughs in RL. Sequential Monte Carlo (SMC) recently emerged as an alternative to the Monte Carlo Tree Search (MCTS) algorithm which drove these breakthroughs. SMC is easier to parallelize and more suitable to GPU acceleration. However, it also suffers from large variance and path degeneracy which prevent it from scaling well with increased search depth, i.e., increased sequential compute. To address these problems, we introduce Twice Sequential Monte Carlo Tree Search (TSMCTS). Across discrete and continuous environments TSMCTS outperforms the SMC baseline as well as a popular modern version of MCTS. Through variance reduction and mitigation of path degeneracy, TSMCTS scales favorably with sequential compute while retaining the properties that make SMC natural to parallelize.
Universal Value-Function Uncertainties
May 27, 2025


Estimating epistemic uncertainty in value functions is a crucial challenge for many aspects of reinforcement learning (RL), including efficient exploration, safe decision-making, and offline RL. While deep ensembles provide a robust method for quantifying value uncertainty, they come with significant computational overhead. Single-model methods, while computationally favorable, often rely on heuristics and typically require additional propagation mechanisms for myopic uncertainty estimates. In this work we introduce universal value-function uncertainties (UVU), which, similar in spirit to random network distillation (RND), quantify uncertainty as squared prediction errors between an online learner and a fixed, randomly initialized target network. Unlike RND, UVU errors reflect policy-conditional value uncertainty, incorporating the future uncertainties any given policy may encounter. This is due to the training procedure employed in UVU: the online network is trained using temporal difference learning with a synthetic reward derived from the fixed, randomly initialized target network. We provide an extensive theoretical analysis of our approach using neural tangent kernel (NTK) theory and show that in the limit of infinite network width, UVU errors are exactly equivalent to the variance of an ensemble of independent universal value functions. Empirically, we show that UVU achieves equal performance to large ensembles on challenging multi-task offline RL settings, while offering simplicity and substantial computational savings.
Bayesian Meta-Reinforcement Learning with Laplace Variational Recurrent Networks
May 24, 2025Meta-reinforcement learning trains a single reinforcement learning agent on a distribution of tasks to quickly generalize to new tasks outside of the training set at test time. From a Bayesian perspective, one can interpret this as performing amortized variational inference on the posterior distribution over training tasks. Among the various meta-reinforcement learning approaches, a common method is to represent this distribution with a point-estimate using a recurrent neural network. We show how one can augment this point estimate to give full distributions through the Laplace approximation, either at the start of, during, or after learning, without modifying the base model architecture. With our approximation, we are able to estimate distribution statistics (e.g., the entropy) of non-Bayesian agents and observe that point-estimate based methods produce overconfident estimators while not satisfying consistency. Furthermore, when comparing our approach to full-distribution based learning of the task posterior, our method performs on par with variational baselines while having much fewer parameters.
How Ensembles of Distilled Policies Improve Generalisation in Reinforcement Learning
May 22, 2025In the zero-shot policy transfer setting in reinforcement learning, the goal is to train an agent on a fixed set of training environments so that it can generalise to similar, but unseen, testing environments. Previous work has shown that policy distillation after training can sometimes produce a policy that outperforms the original in the testing environments. However, it is not yet entirely clear why that is, or what data should be used to distil the policy. In this paper, we prove, under certain assumptions, a generalisation bound for policy distillation after training. The theory provides two practical insights: for improved generalisation, you should 1) train an ensemble of distilled policies, and 2) distil it on as much data from the training environments as possible. We empirically verify that these insights hold in more general settings, when the assumptions required for the theory no longer hold. Finally, we demonstrate that an ensemble of policies distilled on a diverse dataset can generalise significantly better than the original agent.
VeRecycle: Reclaiming Guarantees from Probabilistic Certificates for Stochastic Dynamical Systems after Change
May 20, 2025Autonomous systems operating in the real world encounter a range of uncertainties. Probabilistic neural Lyapunov certification is a powerful approach to proving safety of nonlinear stochastic dynamical systems. When faced with changes beyond the modeled uncertainties, e.g., unidentified obstacles, probabilistic certificates must be transferred to the new system dynamics. However, even when the changes are localized in a known part of the state space, state-of-the-art requires complete re-certification, which is particularly costly for neural certificates. We introduce VeRecycle, the first framework to formally reclaim guarantees for discrete-time stochastic dynamical systems. VeRecycle efficiently reuses probabilistic certificates when the system dynamics deviate only in a given subset of states. We present a general theoretical justification and algorithmic implementation. Our experimental evaluation shows scenarios where VeRecycle both saves significant computational effort and achieves competitive probabilistic guarantees in compositional neural control.
Trust-Region Twisted Policy Improvement
Apr 08, 2025Monte-Carlo tree search (MCTS) has driven many recent breakthroughs in deep reinforcement learning (RL). However, scaling MCTS to parallel compute has proven challenging in practice which has motivated alternative planners like sequential Monte-Carlo (SMC). Many of these SMC methods adopt particle filters for smoothing through a reformulation of RL as a policy inference problem. Yet, persisting design choices of these particle filters often conflict with the aim of online planning in RL, which is to obtain a policy improvement at the start of planning. Drawing inspiration from MCTS, we tailor SMC planners specifically for RL by improving data generation within the planner through constrained action sampling and explicit terminal state handling, as well as improving policy and value target estimation. This leads to our Trust-Region Twisted SMC (TRT-SMC), which shows improved runtime and sample-efficiency over baseline MCTS and SMC methods in both discrete and continuous domains.
Contextual Similarity Distillation: Ensemble Uncertainties with a Single Model
Mar 14, 2025Uncertainty quantification is a critical aspect of reinforcement learning and deep learning, with numerous applications ranging from efficient exploration and stable offline reinforcement learning to outlier detection in medical diagnostics. The scale of modern neural networks, however, complicates the use of many theoretically well-motivated approaches such as full Bayesian inference. Approximate methods like deep ensembles can provide reliable uncertainty estimates but still remain computationally expensive. In this work, we propose contextual similarity distillation, a novel approach that explicitly estimates the variance of an ensemble of deep neural networks with a single model, without ever learning or evaluating such an ensemble in the first place. Our method builds on the predictable learning dynamics of wide neural networks, governed by the neural tangent kernel, to derive an efficient approximation of the predictive variance of an infinite ensemble. Specifically, we reinterpret the computation of ensemble variance as a supervised regression problem with kernel similarities as regression targets. The resulting model can estimate predictive variance at inference time with a single forward pass, and can make use of unlabeled target-domain data or data augmentations to refine its uncertainty estimates. We empirically validate our method across a variety of out-of-distribution detection benchmarks and sparse-reward reinforcement learning environments. We find that our single-model method performs competitively and sometimes superior to ensemble-based baselines and serves as a reliable signal for efficient exploration. These results, we believe, position contextual similarity distillation as a principled and scalable alternative for uncertainty quantification in reinforcement learning and general deep learning.
Positive Experience Reflection for Agents in Interactive Text Environments
Nov 04, 2024Intelligent agents designed for interactive environments face significant challenges in text-based games, a domain that demands complex reasoning and adaptability. While agents based on large language models (LLMs) using self-reflection have shown promise, they struggle when initially successful and exhibit reduced effectiveness when using smaller LLMs. We introduce Sweet&Sour, a novel approach that addresses these limitations in existing reflection methods by incorporating positive experiences and managed memory to enrich the context available to the agent at decision time. Our comprehensive analysis spans both closed- and open-source LLMs and demonstrates the effectiveness of Sweet&Sour in improving agent performance, particularly in scenarios where previous approaches fall short.
Training on more Reachable Tasks for Generalisation in Reinforcement Learning
Oct 04, 2024



In multi-task reinforcement learning, agents train on a fixed set of tasks and have to generalise to new ones. Recent work has shown that increased exploration improves this generalisation, but it remains unclear why exactly that is. In this paper, we introduce the concept of reachability in multi-task reinforcement learning and show that an initial exploration phase increases the number of reachable tasks the agent is trained on. This, and not the increased exploration, is responsible for the improved generalisation, even to unreachable tasks. Inspired by this, we propose a novel method Explore-Go that implements such an exploration phase at the beginning of each episode. Explore-Go only modifies the way experience is collected and can be used with most existing on-policy or off-policy reinforcement learning algorithms. We demonstrate the effectiveness of our method when combined with some popular algorithms and show an increase in generalisation performance across several environments.
Pessimistic Iterative Planning for Robust POMDPs
Aug 16, 2024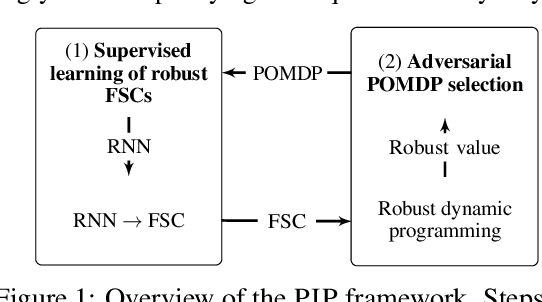
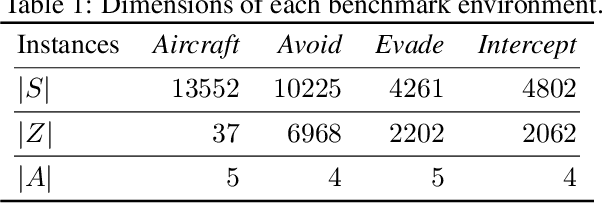
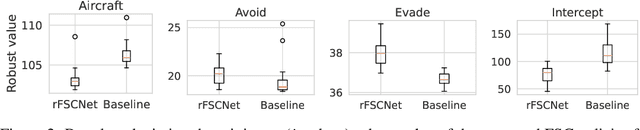
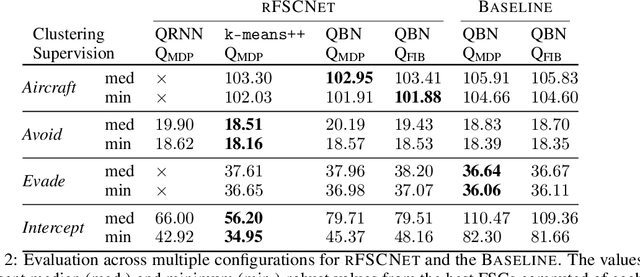
Robust partially observable Markov decision processes (robust POMDPs) extend classical POMDPs to handle additional uncertainty on the transition and observation probabilities via so-called uncertainty sets. Policies for robust POMDPs must not only be memory-based to account for partial observability but also robust against model uncertainty to account for the worst-case instances from the uncertainty sets. We propose the pessimistic iterative planning (PIP) framework, which finds robust memory-based policies for robust POMDPs. PIP alternates between two main steps: (1) selecting an adversarial (non-robust) POMDP via worst-case probability instances from the uncertainty sets; and (2) computing a finite-state controller (FSC) for this adversarial POMDP. We evaluate the performance of this FSC on the original robust POMDP and use this evaluation in step (1) to select the next adversarial POMDP. Within PIP, we propose the rFSCNet algorithm. In each iteration, rFSCNet finds an FSC through a recurrent neural network trained using supervision policies optimized for the adversarial POMDP. The empirical evaluation in four benchmark environments showcases improved robustness against a baseline method in an ablation study and competitive performance compared to a state-of-the-art robust POMDP solver.