 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallelizing Tree Search with Twice Sequential Monte Carlo
Nov 18, 2025Model-based reinforcement learning (RL) methods that leverage search are responsible for many milestone breakthroughs in RL. Sequential Monte Carlo (SMC) recently emerged as an alternative to the Monte Carlo Tree Search (MCTS) algorithm which drove these breakthroughs. SMC is easier to parallelize and more suitable to GPU acceleration. However, it also suffers from large variance and path degeneracy which prevent it from scaling well with increased search depth, i.e., increased sequential compute. To address these problems, we introduce Twice Sequential Monte Carlo Tree Search (TSMCTS). Across discrete and continuous environments TSMCTS outperforms the SMC baseline as well as a popular modern version of MCTS. Through variance reduction and mitigation of path degeneracy, TSMCTS scales favorably with sequential compute while retaining the properties that make SMC natural to parallelize.
Bayesian Meta-Reinforcement Learning with Laplace Variational Recurrent Networks
May 24, 2025Meta-reinforcement learning trains a single reinforcement learning agent on a distribution of tasks to quickly generalize to new tasks outside of the training set at test time. From a Bayesian perspective, one can interpret this as performing amortized variational inference on the posterior distribution over training tasks. Among the various meta-reinforcement learning approaches, a common method is to represent this distribution with a point-estimate using a recurrent neural network. We show how one can augment this point estimate to give full distributions through the Laplace approximation, either at the start of, during, or after learning, without modifying the base model architecture. With our approximation, we are able to estimate distribution statistics (e.g., the entropy) of non-Bayesian agents and observe that point-estimate based methods produce overconfident estimators while not satisfying consistency. Furthermore, when comparing our approach to full-distribution based learning of the task posterior, our method performs on par with variational baselines while having much fewer parameters.
Trust-Region Twisted Policy Improvement
Apr 08, 2025Monte-Carlo tree search (MCTS) has driven many recent breakthroughs in deep reinforcement learning (RL). However, scaling MCTS to parallel compute has proven challenging in practice which has motivated alternative planners like sequential Monte-Carlo (SMC). Many of these SMC methods adopt particle filters for smoothing through a reformulation of RL as a policy inference problem. Yet, persisting design choices of these particle filters often conflict with the aim of online planning in RL, which is to obtain a policy improvement at the start of planning. Drawing inspiration from MCTS, we tailor SMC planners specifically for RL by improving data generation within the planner through constrained action sampling and explicit terminal state handling, as well as improving policy and value target estimation. This leads to our Trust-Region Twisted SMC (TRT-SMC), which shows improved runtime and sample-efficiency over baseline MCTS and SMC methods in both discrete and continuous domains.
On Credit Assignment in Hierarchical Reinforcement Learning
Mar 07, 2022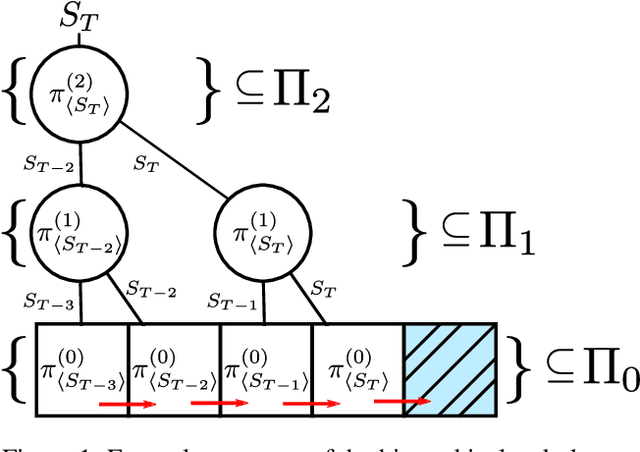



Hierarchical Reinforcement Learning (HRL) has held longstanding promise to advance reinforcement learning. Yet, it has remained a considerable challenge to develop practical algorithms that exhibit some of these promises. To improve our fundamental understanding of HRL, we investigate hierarchical credit assignment from the perspective of conventional multistep reinforcement learning. We show how e.g., a 1-step `hierarchical backup' can be seen as a conventional multistep backup with $n$ skip connections over time connecting each subsequent state to the first independent of actions inbetween. Furthermore, we find that generalizing hierarchy to multistep return estimation methods requires us to consider how to partition the environment trace, in order to construct backup paths. We leverage these insight to develop a new hierarchical algorithm Hier$Q_k(\lambda)$, for which we demonstrate that hierarchical credit assignment alone can already boost agent performance (i.e., when eliminating generalization or exploration). Altogether, our work yields fundamental insight into the nature of hierarchical backups and distinguishes this as an additional basis for reinforcement learning research.
Visualizing MuZero Models
Mar 03, 2021
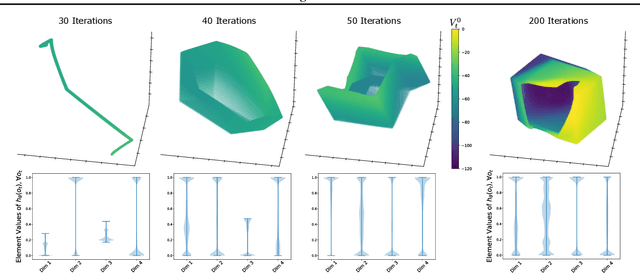
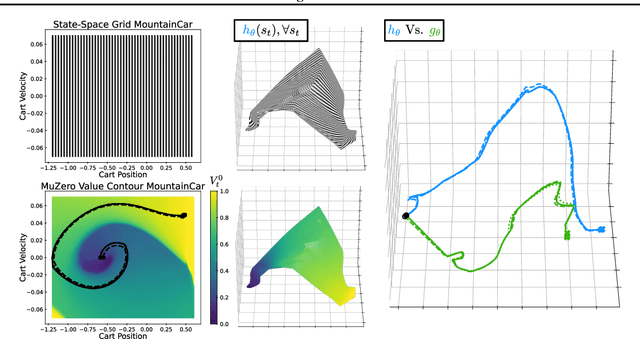
MuZero, a model-based reinforcement learning algorithm that uses a value equivalent dynamics model, achieved state-of-the-art performance in Chess, Shogi and the game of Go. In contrast to standard forward dynamics models that predict a full next state, value equivalent models are trained to predict a future value, thereby emphasizing value relevant information in the representations. While value equivalent models have shown strong empirical success, there is no research yet that visualizes and investigates what types of representations these models actually learn. Therefore, in this paper we visualize the latent representation of MuZero agents. We find that action trajectories may diverge between observation embeddings and internal state transition dynamics, which could lead to instability during planning. Based on this insight, we propose two regularization techniques to stabilize MuZero's performance. Additionally, we provide an open-source implementation of MuZero along with an interactive visualizer of learned representations, which may aid further investigation of value equivalent algorithms.