 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Focus: Prioritizing Informative Histories with Structured Attention Mechanisms in Partially Observable Reinforcement Learning
Nov 10, 2025Transformers have shown strong ability to model long-term dependencies and are increasingly adopted as world models in model-based reinforcement learning (RL) under partial observability. However, unlike natural language corpora, RL trajectories are sparse and reward-driven, making standard self-attention inefficient because it distributes weight uniformly across all past tokens rather than emphasizing the few transitions critical for control. To address this, we introduce structured inductive priors into the self-attention mechanism of the dynamics head: (i) per-head memory-length priors that constrain attention to task-specific windows, and (ii) distributional priors that learn smooth Gaussian weightings over past state-action pairs. We integrate these mechanisms into UniZero, a model-based RL agent with a Transformer-based world model that supports planning under partial observability. Experiments on the Atari 100k benchmark show that most efficiency gains arise from the Gaussian prior, which smoothly allocates attention to informative transitions, while memory-length priors often truncate useful signals with overly restrictive cut-offs. In particular, Gaussian Attention achieves a 77% relative improvement in mean human-normalized scores over UniZero. These findings suggest that in partially observable RL domains with non-stationary temporal dependencies, discrete memory windows are difficult to learn reliably, whereas smooth distributional priors flexibly adapt across horizons and yield more robust data efficiency. Overall, our results demonstrate that encoding structured temporal priors directly into self-attention improves the prioritization of informative histories for dynamics modeling under partial observability.
Bayesian Meta-Reinforcement Learning with Laplace Variational Recurrent Networks
May 24, 2025



Meta-reinforcement learning trains a single reinforcement learning agent on a distribution of tasks to quickly generalize to new tasks outside of the training set at test time. From a Bayesian perspective, one can interpret this as performing amortized variational inference on the posterior distribution over training tasks. Among the various meta-reinforcement learning approaches, a common method is to represent this distribution with a point-estimate using a recurrent neural network. We show how one can augment this point estimate to give full distributions through the Laplace approximation, either at the start of, during, or after learning, without modifying the base model architecture. With our approximation, we are able to estimate distribution statistics (e.g., the entropy) of non-Bayesian agents and observe that point-estimate based methods produce overconfident estimators while not satisfying consistency. Furthermore, when comparing our approach to full-distribution based learning of the task posterior, our method performs on par with variational baselines while having much fewer parameters.
Trust-Region Twisted Policy Improvement
Apr 08, 2025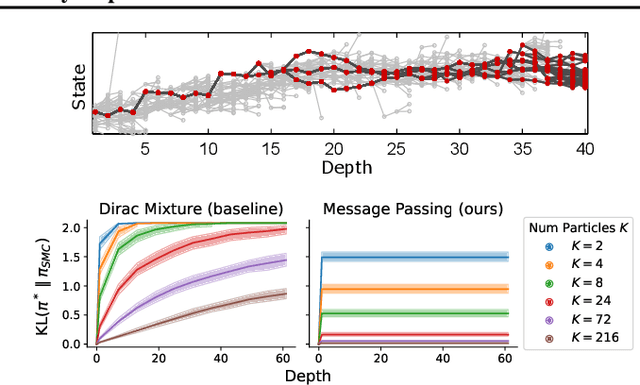
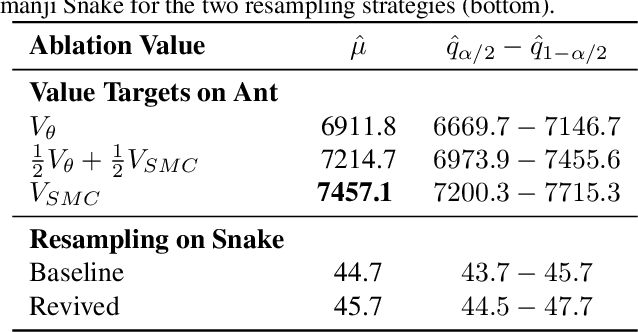
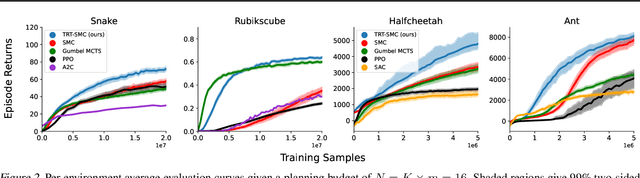
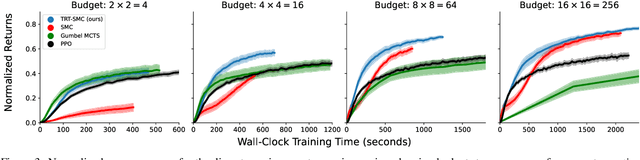
Monte-Carlo tree search (MCTS) has driven many recent breakthroughs in deep reinforcement learning (RL). However, scaling MCTS to parallel compute has proven challenging in practice which has motivated alternative planners like sequential Monte-Carlo (SMC). Many of these SMC methods adopt particle filters for smoothing through a reformulation of RL as a policy inference problem. Yet, persisting design choices of these particle filters often conflict with the aim of online planning in RL, which is to obtain a policy improvement at the start of planning. Drawing inspiration from MCTS, we tailor SMC planners specifically for RL by improving data generation within the planner through constrained action sampling and explicit terminal state handling, as well as improving policy and value target estimation. This leads to our Trust-Region Twisted SMC (TRT-SMC), which shows improved runtime and sample-efficiency over baseline MCTS and SMC methods in both discrete and continuous domains.
Timing the Match: A Deep Reinforcement Learning Approach for Ride-Hailing and Ride-Pooling Services
Mar 17, 2025Efficient timing in ride-matching is crucial for improving the performance of ride-hailing and ride-pooling services, as it determines the number of drivers and passengers considered in each matching process. Traditional batched matching methods often use fixed time intervals to accumulate ride requests before assigning matches. While this approach increases the number of available drivers and passengers for matching, it fails to adapt to real-time supply-demand fluctuations, often leading to longer passenger wait times and driver idle periods. To address this limitation, we propose an adaptive ride-matching strategy using deep reinforcement learning (RL) to dynamically determine when to perform matches based on real-time system conditions. Unlike fixed-interval approaches, our method continuously evaluates system states and executes matching at moments that minimize total passenger wait time. Additionally, we incorporate a potential-based reward shaping (PBRS) mechanism to mitigate sparse rewards, accelerating RL training and improving decision quality. Extensive empirical evaluations using a realistic simulator trained on real-world data demonstrate that our approach outperforms fixed-interval matching strategies, significantly reducing passenger waiting times and detour delays, thereby enhancing the overall efficiency of ride-hailing and ride-pooling systems.
Benchmarking Robustness and Generalization in Multi-Agent Systems: A Case Study on Neural MMO
Aug 30, 2023

We present the results of the second Neural MMO challenge, hosted at IJCAI 2022, which received 1600+ submissions. This competition targets robustness and generalization in multi-agent systems: participants train teams of agents to complete a multi-task objective against opponents not seen during training. The competition combines relatively complex environment design with large numbers of agents in the environment. The top submissions demonstrate strong success on this task using mostly standard reinforcement learning (RL) methods combined with domain-specific engineering. We summarize the competition design and results and suggest that, as an academic community, competitions may be a powerful approach to solving hard problems and establishing a solid benchmark for algorithms. We will open-source our benchmark including the environment wrapper, baselines, a visualization tool, and selected policies for further research.
What model does MuZero learn?
Jun 01, 2023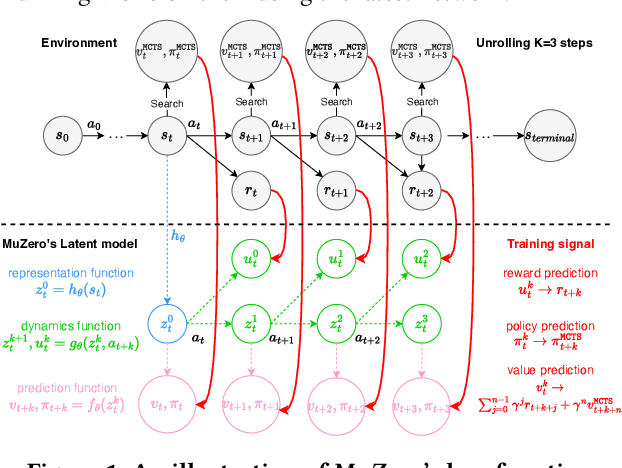
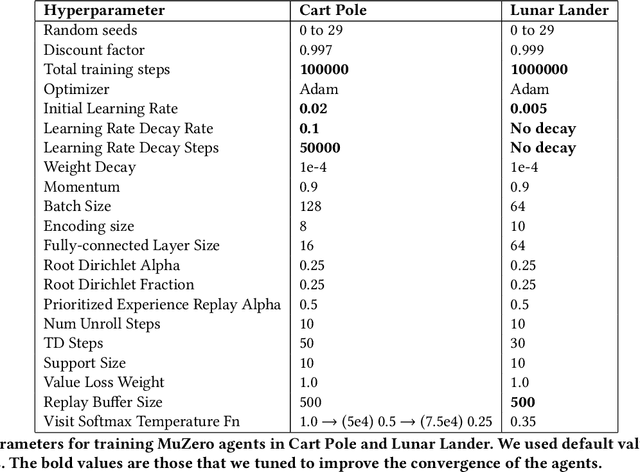
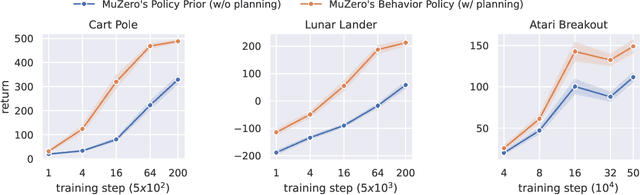
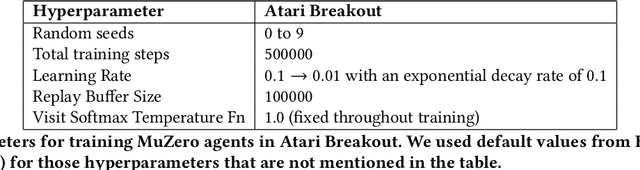
Model-based reinforcement learning has drawn considerable interest in recent years, given its promise to improve sample efficiency. Moreover, when using deep-learned models, it is potentially possible to learn compact models from complex sensor data. However, the effectiveness of these learned models, particularly their capacity to plan, i.e., to improve the current policy, remains unclear. In this work, we study MuZero, a well-known deep model-based reinforcement learning algorithm, and explore how far it achieves its learning objective of a value-equivalent model and how useful the learned models are for policy improvement. Amongst various other insights, we conclude that the model learned by MuZero cannot effectively generalize to evaluate unseen policies, which limits the extent to which we can additionally improve the current policy by planning with the model.
RangL: A Reinforcement Learning Competition Platform
Jul 28, 2022
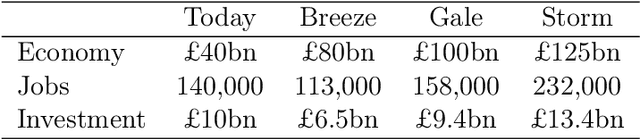

The RangL project hosted by The Alan Turing Institute aims to encourage the wider uptake of reinforcement learning by supporting competitions relating to real-world dynamic decision problems. This article describes the reusable code repository developed by the RangL team and deployed for the 2022 Pathways to Net Zero Challenge, supported by the UK Net Zero Technology Centre. The winning solutions to this particular Challenge seek to optimize the UK's energy transition policy to net zero carbon emissions by 2050. The RangL repository includes an OpenAI Gym reinforcement learning environment and code that supports both submission to, and evaluation in, a remote instance of the open source EvalAI platform as well as all winning learning agent strategies. The repository is an illustrative example of RangL's capability to provide a reusable structure for future challenges.
Distributed Influence-Augmented Local Simulators for Parallel MARL in Large Networked Systems
Jul 01, 2022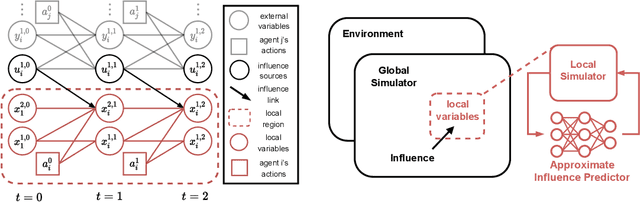
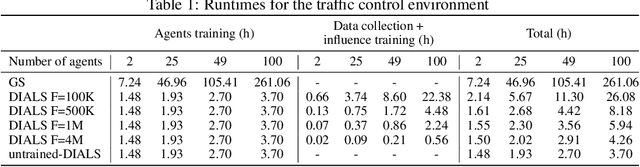
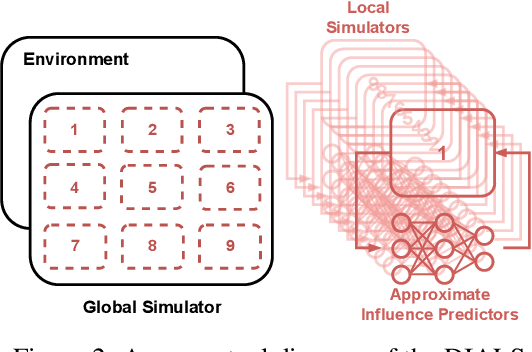
Due to its high sample complexity, simulation is, as of today, critical for the successful application of reinforcement learning. Many real-world problems, however, exhibit overly complex dynamics, which makes their full-scale simulation computationally slow. In this paper, we show how to decompose large networked systems of many agents into multiple local components such that we can build separate simulators that run independently and in parallel. To monitor the influence that the different local components exert on one another, each of these simulators is equipped with a learned model that is periodically trained on real trajectories. Our empirical results reveal that distributing the simulation among different processes not only makes it possible to train large multi-agent systems in just a few hours but also helps mitigate the negative effects of simultaneous learning.
Influence-Augmented Local Simulators: A Scalable Solution for Fast Deep RL in Large Networked Systems
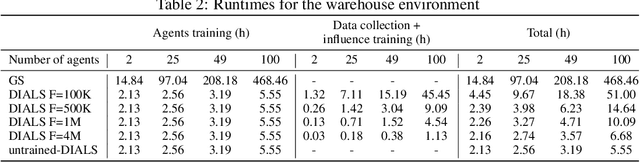
Feb 03, 2022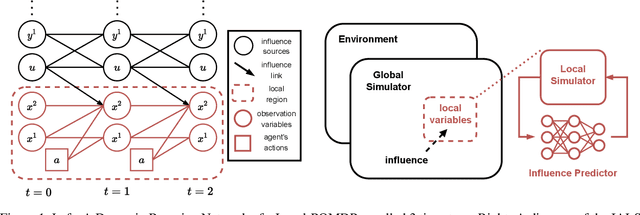
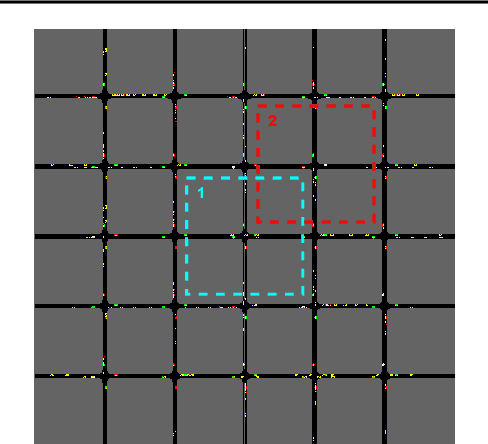
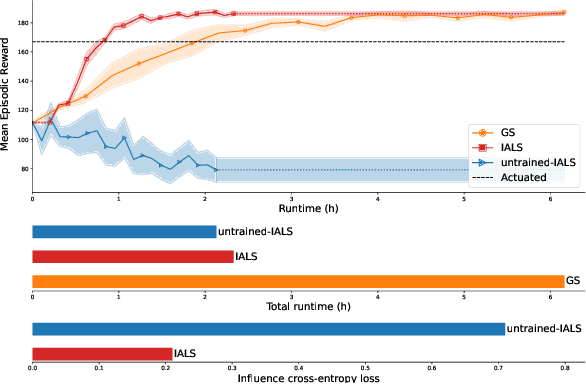

Learning effective policies for real-world problems is still an open challenge for the field of reinforcement learning (RL). The main limitation being the amount of data needed and the pace at which that data can be obtained. In this paper, we study how to build lightweight simulators of complicated systems that can run sufficiently fast for deep RL to be applicable. We focus on domains where agents interact with a reduced portion of a larger environment while still being affected by the global dynamics. Our method combines the use of local simulators with learned models that mimic the influence of the global system. The experiments reveal that incorporating this idea into the deep RL workflow can considerably accelerate the training process and presents several opportunities for the future.
Online Planning in POMDPs with Self-Improving Simulators
Jan 27, 2022

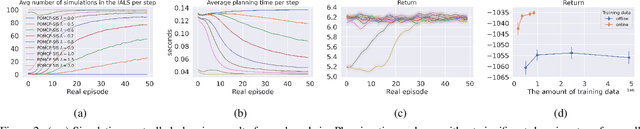

How can we plan efficiently in a large and complex environment when the time budget is limited? Given the original simulator of the environment, which may be computationally very demanding, we propose to learn online an approximate but much faster simulator that improves over time. To plan reliably and efficiently while the approximate simulator is learning, we develop a method that adaptively decides which simulator to use for every simulation, based on a statistic that measures the accuracy of the approximate simulator. This allows us to use the approximate simulator to replace the original simulator for faster simulations when it is accurate enough under the current context, thus trading off simulation speed and accuracy. Experimental results in two large domains show that when integrated with POMCP, our approach allows to plan with improving efficiency over time.