 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Guarantees in Multi-agent Learning via Trapping Regions
Feb 27, 2023One of the main challenges of multi-agent learning lies in establishing convergence of the algorithms, as, in general, a collection of individual, self-serving agents is not guaranteed to converge with their joint policy, when learning concurrently. This is in stark contrast to most single-agent environments, and sets a prohibitive barrier for deployment in practical applications, as it induces uncertainty in long term behavior of the system. In this work, we propose to apply the concept of trapping regions, known from qualitative theory of dynamical systems, to create safety sets in the joint strategy space for decentralized learning. Upon verification of the direction of learning dynamics, the resulting trajectories are guaranteed not to escape such sets, during the learning process. As a result, it is ensured, that despite the uncertainty over convergence of the applied algorithms, learning will never form hazardous joint strategy combinations. We introduce a binary partitioning algorithm for verification of trapping regions in systems with known learning dynamics, and a heuristic sampling algorithm for scenarios where learning dynamics are not known. In addition, via a fixed point argument, we show the existence of a learning equilibrium within a trapping region. We demonstrate the applications to a regularized version of Dirac Generative Adversarial Network, a four-intersection traffic control scenario run in a state of the art open-source microscopic traffic simulator SUMO, and a mathematical model of economic competition.
RangL: A Reinforcement Learning Competition Platform
Jul 28, 2022

The RangL project hosted by The Alan Turing Institute aims to encourage the wider uptake of reinforcement learning by supporting competitions relating to real-world dynamic decision problems. This article describes the reusable code repository developed by the RangL team and deployed for the 2022 Pathways to Net Zero Challenge, supported by the UK Net Zero Technology Centre. The winning solutions to this particular Challenge seek to optimize the UK's energy transition policy to net zero carbon emissions by 2050. The RangL repository includes an OpenAI Gym reinforcement learning environment and code that supports both submission to, and evaluation in, a remote instance of the open source EvalAI platform as well as all winning learning agent strategies. The repository is an illustrative example of RangL's capability to provide a reusable structure for future challenges.
Decentralized MCTS via Learned Teammate Models
Mar 19, 2020


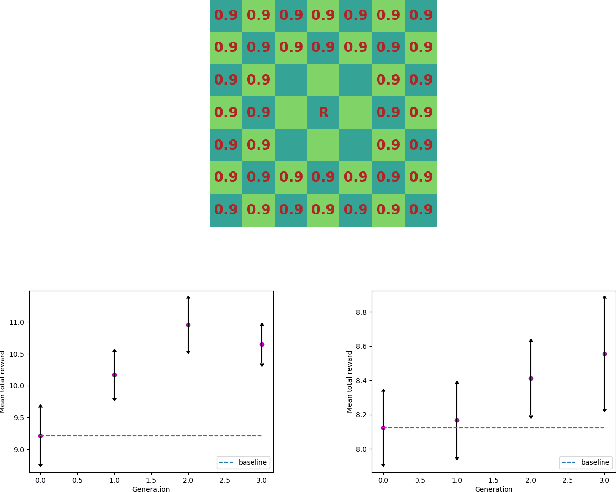
A key difficulty of cooperative decentralized planning lies in making accurate predictions about the decisions of other agents. In this paper we present a policy improvement operator for learning to plan in iterated cooperative multi-agent scenarios. At each application of our method, a selected agent learns an approximation of policies of its teammates from data from past simulations. Under the assumption of ideal function approximation, successive iterations of our algorithm are guaranteed to improve the policies, and eventually lead to convergence to a Nash equilibrium in a coordinate ascent manner. We combine the policy improvement operator with the decentralized Monte Carlo Tree Search planning method and demonstrate the application of the algorithm on several scenarios in the spatial task allocation problem introduced in (Claes et al., 2015). We show that deep learning and convolutional neural networks can be efficiently employed to produce policy approximators which exploit the spatial features of the problem, and that the proposed algorithm improves over the baseline planning performance for particularly challenging domain configurations.
Influence-aware Memory for Deep Reinforcement Learning
Nov 21, 2019
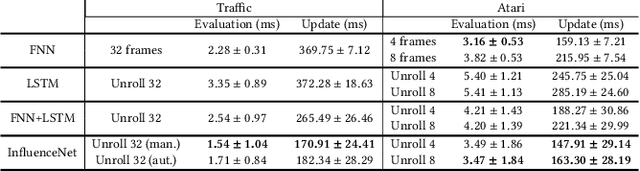


Making the right decisions when some of the state variables are hidden, involves reasoning about all the possible states of the environment. An agent receiving only partial observations needs to infer the true values of these hidden variables based on the history of experiences. Recent deep reinforcement learning methods use recurrent models to keep track of past information. However, these models are sometimes expensive to train and have convergence difficulties, especially when dealing with high dimensional input spaces. Taking inspiration from influence-based abstraction, we show that effective policies can be learned in the presence of uncertainty by only memorizing a small subset of input variables. We also incorporate a mechanism in our network that learns to automatically choose the important pieces of information that need to be remembered. The results indicate that, by forcing the agent's internal memory to focus on the selected regions while treating the rest of the observable variables as Markovian, we can outperform ordinary recurrent architectures in situations where the amount of information that the agent needs to retain represents a small fraction of the entire observation input. The method also reduces training time and obtains better scores than methods that stack multiple observations to remove partial observability in domains where long-term memory is required.