 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Habits: On the Role of the Advantage Function in Learning Causal State Representations
Jun 13, 2025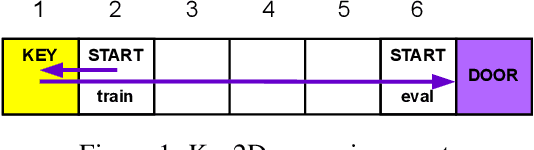
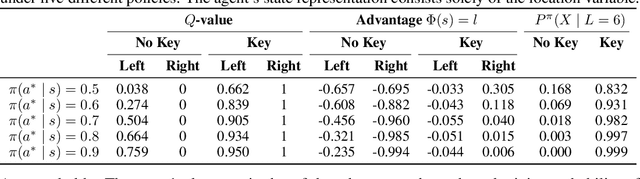
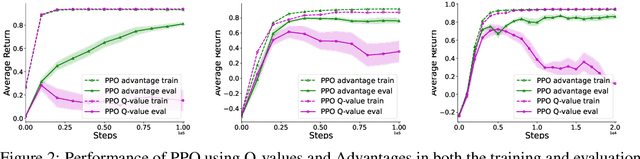

Recent work has shown that reinforcement learning agents can develop policies that exploit spurious correlations between rewards and observations. This phenomenon, known as policy confounding, arises because the agent's policy influences both past and future observation variables, creating a feedback loop that can hinder the agent's ability to generalize beyond its usual trajectories. In this paper, we show that the advantage function, commonly used in policy gradient methods, not only reduces the variance of gradient estimates but also mitigates the effects of policy confounding. By adjusting action values relative to the state representation, the advantage function downweights state-action pairs that are more likely under the current policy, breaking spurious correlations and encouraging the agent to focus on causal factors. We provide both analytical and empirical evidence demonstrating that training with the advantage function leads to improved out-of-trajectory performance.
Bad Habits: Policy Confounding and Out-of-Trajectory Generalization in RL
Jun 04, 2023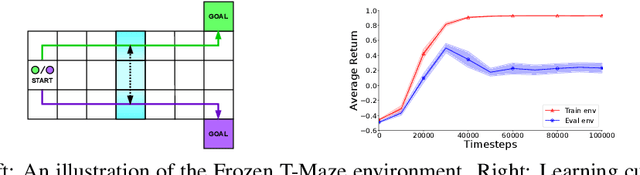


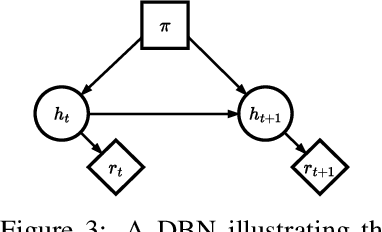
Reinforcement learning agents may sometimes develop habits that are effective only when specific policies are followed. After an initial exploration phase in which agents try out different actions, they eventually converge toward a particular policy. When this occurs, the distribution of state-action trajectories becomes narrower, and agents start experiencing the same transitions again and again. At this point, spurious correlations may arise. Agents may then pick up on these correlations and learn state representations that do not generalize beyond the agent's trajectory distribution. In this paper, we provide a mathematical characterization of this phenomenon, which we refer to as policy confounding, and show, through a series of examples, when and how it occurs in practice.
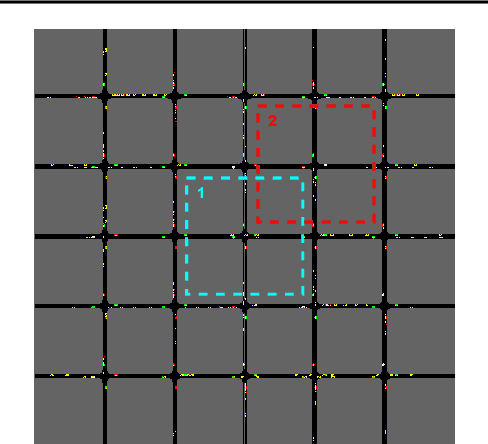
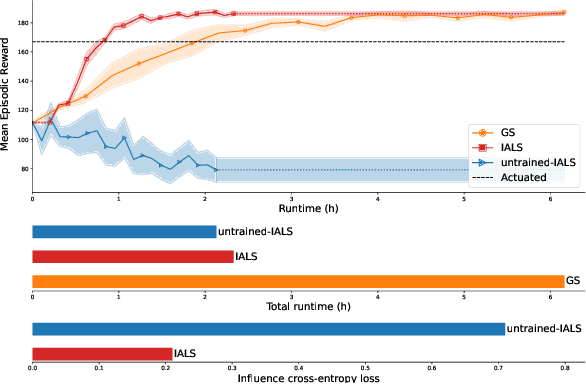
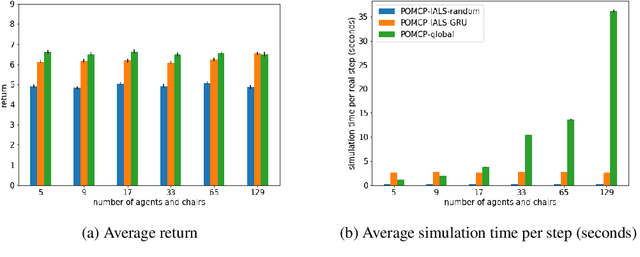
Distributed Influence-Augmented Local Simulators for Parallel MARL in Large Networked Systems
Jul 01, 2022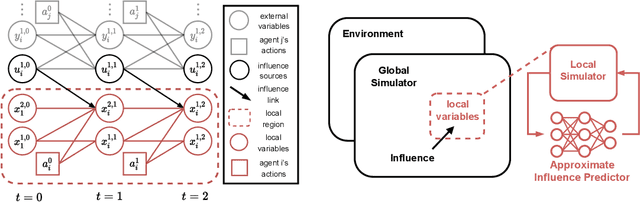
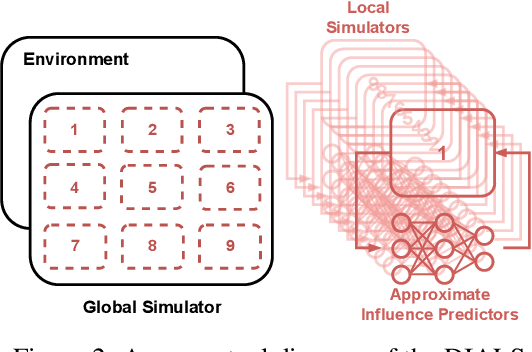
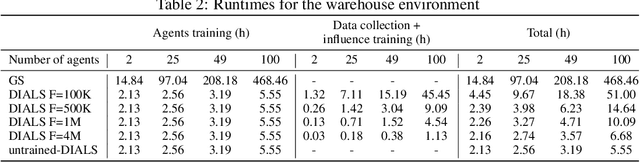
Due to its high sample complexity, simulation is, as of today, critical for the successful application of reinforcement learning. Many real-world problems, however, exhibit overly complex dynamics, which makes their full-scale simulation computationally slow. In this paper, we show how to decompose large networked systems of many agents into multiple local components such that we can build separate simulators that run independently and in parallel. To monitor the influence that the different local components exert on one another, each of these simulators is equipped with a learned model that is periodically trained on real trajectories. Our empirical results reveal that distributing the simulation among different processes not only makes it possible to train large multi-agent systems in just a few hours but also helps mitigate the negative effects of simultaneous learning.
Influence-Augmented Local Simulators: A Scalable Solution for Fast Deep RL in Large Networked Systems
Feb 03, 2022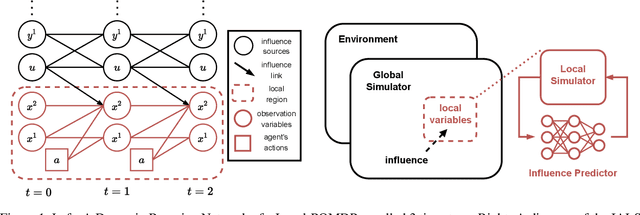

Learning effective policies for real-world problems is still an open challenge for the field of reinforcement learning (RL). The main limitation being the amount of data needed and the pace at which that data can be obtained. In this paper, we study how to build lightweight simulators of complicated systems that can run sufficiently fast for deep RL to be applicable. We focus on domains where agents interact with a reduced portion of a larger environment while still being affected by the global dynamics. Our method combines the use of local simulators with learned models that mimic the influence of the global system. The experiments reveal that incorporating this idea into the deep RL workflow can considerably accelerate the training process and presents several opportunities for the future.
Online Planning in POMDPs with Self-Improving Simulators
Jan 27, 2022

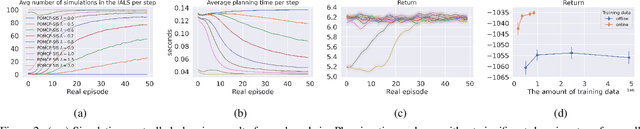

How can we plan efficiently in a large and complex environment when the time budget is limited? Given the original simulator of the environment, which may be computationally very demanding, we propose to learn online an approximate but much faster simulator that improves over time. To plan reliably and efficiently while the approximate simulator is learning, we develop a method that adaptively decides which simulator to use for every simulation, based on a statistic that measures the accuracy of the approximate simulator. This allows us to use the approximate simulator to replace the original simulator for faster simulations when it is accurate enough under the current context, thus trading off simulation speed and accuracy. Experimental results in two large domains show that when integrated with POMCP, our approach allows to plan with improving efficiency over time.
Offline Contextual Bandits for Wireless Network Optimization
Nov 11, 2021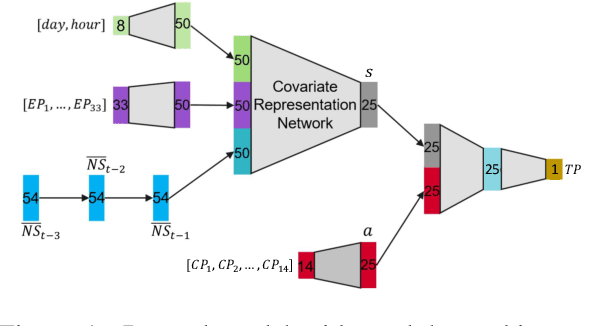
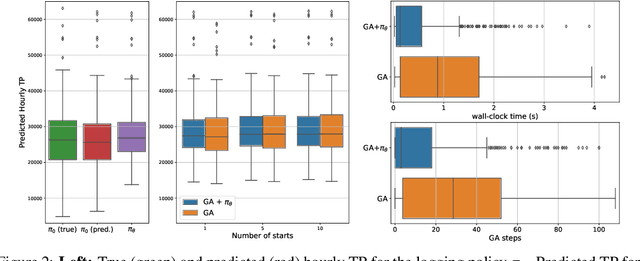
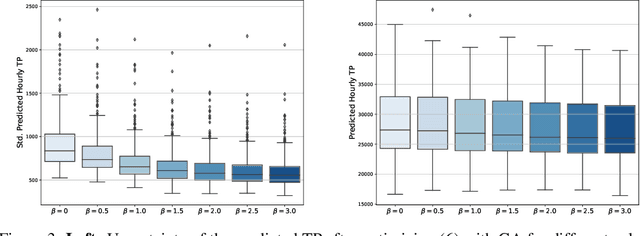
The explosion in mobile data traffic together with the ever-increasing expectations for higher quality of service call for the development of AI algorithms for wireless network optimization. In this paper, we investigate how to learn policies that can automatically adjust the configuration parameters of every cell in the network in response to the changes in the user demand. Our solution combines existent methods for offline learning and adapts them in a principled way to overcome crucial challenges arising in this context. Empirical results suggest that our proposed method will achieve important performance gains when deployed in the real network while satisfying practical constrains on computational efficiency.
Influence-Augmented Online Planning for Complex Environments
Oct 21, 2020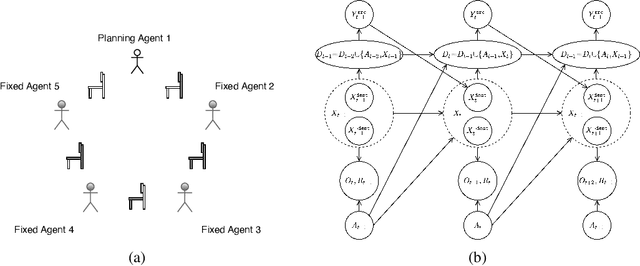


How can we plan efficiently in real time to control an agent in a complex environment that may involve many other agents? While existing sample-based planners have enjoyed empirical success in large POMDPs, their performance heavily relies on a fast simulator. However, real-world scenarios are complex in nature and their simulators are often computationally demanding, which severely limits the performance of online planners. In this work, we propose influence-augmented online planning, a principled method to transform a factored simulator of the entire environment into a local simulator that samples only the state variables that are most relevant to the observation and reward of the planning agent and captures the incoming influence from the rest of the environment using machine learning methods. Our main experimental results show that planning on this less accurate but much faster local simulator with POMCP leads to higher real-time planning performance than planning on the simulator that models the entire environment.
Influence-aware Memory for Deep Reinforcement Learning
Nov 21, 2019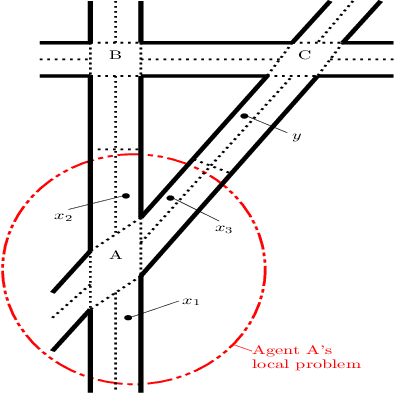
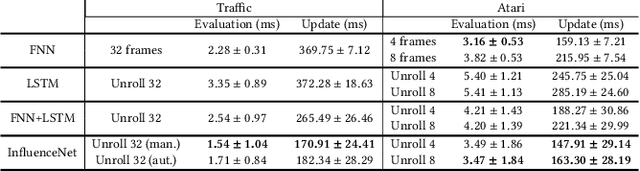


Making the right decisions when some of the state variables are hidden, involves reasoning about all the possible states of the environment. An agent receiving only partial observations needs to infer the true values of these hidden variables based on the history of experiences. Recent deep reinforcement learning methods use recurrent models to keep track of past information. However, these models are sometimes expensive to train and have convergence difficulties, especially when dealing with high dimensional input spaces. Taking inspiration from influence-based abstraction, we show that effective policies can be learned in the presence of uncertainty by only memorizing a small subset of input variables. We also incorporate a mechanism in our network that learns to automatically choose the important pieces of information that need to be remembered. The results indicate that, by forcing the agent's internal memory to focus on the selected regions while treating the rest of the observable variables as Markovian, we can outperform ordinary recurrent architectures in situations where the amount of information that the agent needs to retain represents a small fraction of the entire observation input. The method also reduces training time and obtains better scores than methods that stack multiple observations to remove partial observability in domains where long-term memory is required.