 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInnateCoder: Learning Programmatic Options with Foundation Models
May 18, 2025Outside of transfer learning settings, reinforcement learning agents start their learning process from a clean slate. As a result, such agents have to go through a slow process to learn even the most obvious skills required to solve a problem. In this paper, we present InnateCoder, a system that leverages human knowledge encoded in foundation models to provide programmatic policies that encode "innate skills" in the form of temporally extended actions, or options. In contrast to existing approaches to learning options, InnateCoder learns them from the general human knowledge encoded in foundation models in a zero-shot setting, and not from the knowledge the agent gains by interacting with the environment. Then, InnateCoder searches for a programmatic policy by combining the programs encoding these options into larger and more complex programs. We hypothesized that InnateCoder's way of learning and using options could improve the sampling efficiency of current methods for learning programmatic policies. Empirical results in MicroRTS and Karel the Robot support our hypothesis, since they show that InnateCoder is more sample efficient than versions of the system that do not use options or learn them from experience.
Combining LLMs with Logic-Based Framework to Explain MCTS
May 01, 2025

In response to the lack of trust in Artificial Intelligence (AI) for sequential planning, we design a Computational Tree Logic-guided large language model (LLM)-based natural language explanation framework designed for the Monte Carlo Tree Search (MCTS) algorithm. MCTS is often considered challenging to interpret due to the complexity of its search trees, but our framework is flexible enough to handle a wide range of free-form post-hoc queries and knowledge-based inquiries centered around MCTS and the Markov Decision Process (MDP) of the application domain. By transforming user queries into logic and variable statements, our framework ensures that the evidence obtained from the search tree remains factually consistent with the underlying environmental dynamics and any constraints in the actual stochastic control process. We evaluate the framework rigorously through quantitative assessments, where it demonstrates strong performance in terms of accuracy and factual consistency.
MOMAland: A Set of Benchmarks for Multi-Objective Multi-Agent Reinforcement Learning
Jul 23, 2024



Many challenging tasks such as managing traffic systems, electricity grids, or supply chains involve complex decision-making processes that must balance multiple conflicting objectives and coordinate the actions of various independent decision-makers (DMs). One perspective for formalising and addressing such tasks is multi-objective multi-agent reinforcement learning (MOMARL). MOMARL broadens reinforcement learning (RL) to problems with multiple agents each needing to consider multiple objectives in their learning process. In reinforcement learning research, benchmarks are crucial in facilitating progress, evaluation, and reproducibility. The significance of benchmarks is underscored by the existence of numerous benchmark frameworks developed for various RL paradigms, including single-agent RL (e.g., Gymnasium), multi-agent RL (e.g., PettingZoo), and single-agent multi-objective RL (e.g., MO-Gymnasium). To support the advancement of the MOMARL field, we introduce MOMAland, the first collection of standardised environments for multi-objective multi-agent reinforcement learning. MOMAland addresses the need for comprehensive benchmarking in this emerging field, offering over 10 diverse environments that vary in the number of agents, state representations, reward structures, and utility considerations. To provide strong baselines for future research, MOMAland also includes algorithms capable of learning policies in such settings.
Enabling MCTS Explainability for Sequential Planning Through Computation Tree Logic
Jul 15, 2024



Monte Carlo tree search (MCTS) is one of the most capable online search algorithms for sequential planning tasks, with significant applications in areas such as resource allocation and transit planning. Despite its strong performance in real-world deployment, the inherent complexity of MCTS makes it challenging to understand for users without technical background. This paper considers the use of MCTS in transportation routing services, where the algorithm is integrated to develop optimized route plans. These plans are required to meet a range of constraints and requirements simultaneously, further complicating the task of explaining the algorithm's operation in real-world contexts. To address this critical research gap, we introduce a novel computation tree logic-based explainer for MCTS. Our framework begins by taking user-defined requirements and translating them into rigorous logic specifications through the use of language templates. Then, our explainer incorporates a logic verification and quantitative evaluation module that validates the states and actions traversed by the MCTS algorithm. The outcomes of this analysis are then rendered into human-readable descriptive text using a second set of language templates. The user satisfaction of our approach was assessed through a survey with 82 participants. The results indicated that our explanatory approach significantly outperforms other baselines in user preference.
Decision Making in Non-Stationary Environments with Policy-Augmented Search
Jan 06, 2024



Sequential decision-making under uncertainty is present in many important problems. Two popular approaches for tackling such problems are reinforcement learning and online search (e.g., Monte Carlo tree search). While the former learns a policy by interacting with the environment (typically done before execution), the latter uses a generative model of the environment to sample promising action trajectories at decision time. Decision-making is particularly challenging in non-stationary environments, where the environment in which an agent operates can change over time. Both approaches have shortcomings in such settings -- on the one hand, policies learned before execution become stale when the environment changes and relearning takes both time and computational effort. Online search, on the other hand, can return sub-optimal actions when there are limitations on allowed runtime. In this paper, we introduce \textit{Policy-Augmented Monte Carlo tree search} (PA-MCTS), which combines action-value estimates from an out-of-date policy with an online search using an up-to-date model of the environment. We prove theoretical results showing conditions under which PA-MCTS selects the one-step optimal action and also bound the error accrued while following PA-MCTS as a policy. We compare and contrast our approach with AlphaZero, another hybrid planning approach, and Deep Q Learning on several OpenAI Gym environments. Through extensive experiments, we show that under non-stationary settings with limited time constraints, PA-MCTS outperforms these baselines.
BRExIt: On Opponent Modelling in Expert Iteration
May 31, 2022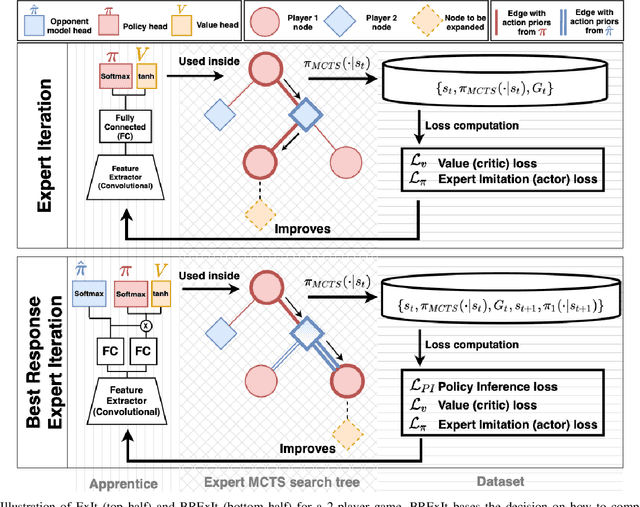
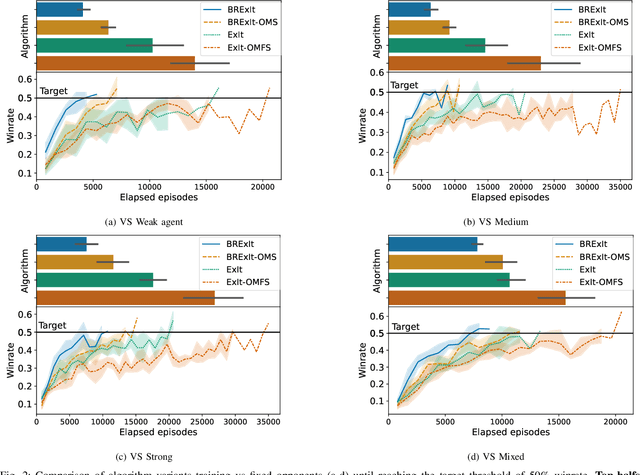
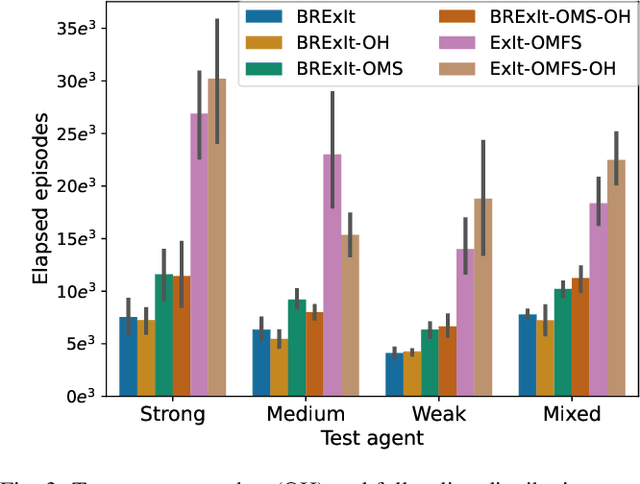
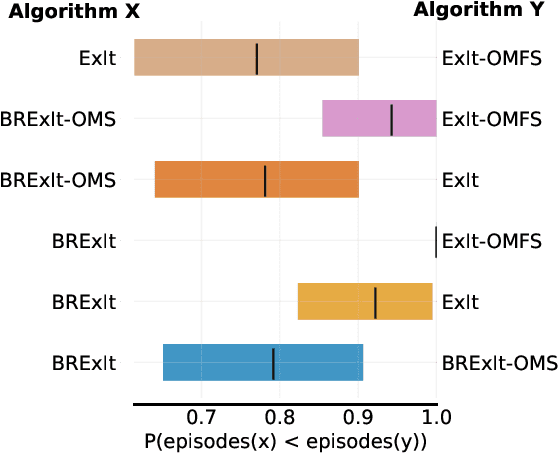
Finding a best response policy is a central objective in game theory and multi-agent learning, with modern population-based training approaches employing reinforcement learning algorithms as best-response oracles to improve play against candidate opponents (typically previously learnt policies). We propose Best Response Expert Iteration (BRExIt), which accelerates learning in games by incorporating opponent models into the state-of-the-art learning algorithm Expert Iteration (ExIt). BRExIt aims to (1) improve feature shaping in the apprentice, with a policy head predicting opponent policies as an auxiliary task, and (2) bias opponent moves in planning towards the given or learnt opponent model, to generate apprentice targets that better approximate a best response. In an empirical ablation on BRExIt's algorithmic variants in the game Connect4 against a set of fixed test agents, we provide statistical evidence that BRExIt learns well-performing policies with greater sample efficiency than ExIt.
Online Planning in POMDPs with Self-Improving Simulators
Jan 27, 2022

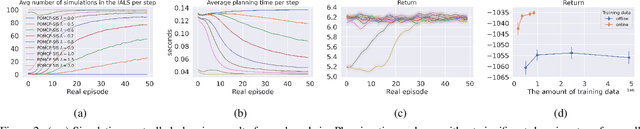

How can we plan efficiently in a large and complex environment when the time budget is limited? Given the original simulator of the environment, which may be computationally very demanding, we propose to learn online an approximate but much faster simulator that improves over time. To plan reliably and efficiently while the approximate simulator is learning, we develop a method that adaptively decides which simulator to use for every simulation, based on a statistic that measures the accuracy of the approximate simulator. This allows us to use the approximate simulator to replace the original simulator for faster simulations when it is accurate enough under the current context, thus trading off simulation speed and accuracy. Experimental results in two large domains show that when integrated with POMCP, our approach allows to plan with improving efficiency over time.
The Text-Based Adventure AI Competition
Oct 19, 2018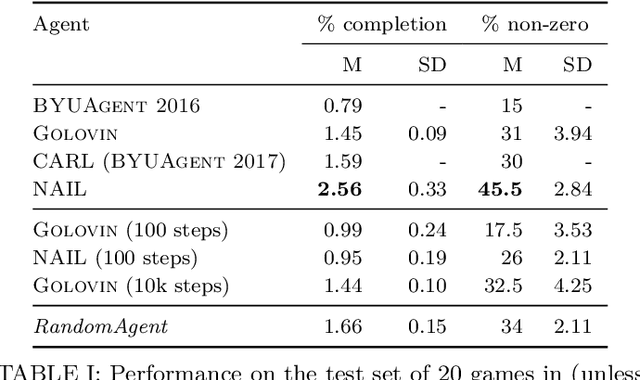
In 2016, 2017, and 2018 at the IEEE Conference on Computational Intelligence in Games, the authors of this paper ran a competition for agents that can play classic text-based adventure games. This competition fills a gap in existing game AI competitions that have typically focussed on traditional card/board games or modern video games with graphical interfaces. By providing a platform for evaluating agents in text-based adventures, the competition provides a novel benchmark for game AI with unique challenges for natural language understanding and generation. This paper summarises the three competitions ran in 2016, 2017, and 2018 (including details of open source implementations of both the competition framework and our competitors) and presents the results of an improved evaluation of these competitors across 20 games.