 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning, Scheduling, and Behavior in EV Charging Systems: A Critical Survey and Trilemma Framework
May 20, 2026The rapid growth of electric vehicles is shifting the main constraint on transport electrification from vehicle adoption to the deployment and operation of charging infrastructure. Charging-network design requires decisions across three interdependent layers: Planning, which determines where and how much infrastructure to build; Scheduling, which governs charging dispatch, pricing, and grid interaction; and Behavior, which captures how users choose stations, charging times, and charging durations. Existing studies have advanced each layer substantially, but the literature remains fragmented, and cross-layer interactions are often treated through simplifying assumptions. This survey develops a three-layer Planning-Scheduling-Behavior (PSB) framework to organize EV charging research according to decision horizon, actor objective, and coupling structure. We further identify a fidelity-tractability tradeoff, termed the PSB trilemma: each layer is computationally difficult in isolation, and realistic integration across layers generally requires reducing the fidelity of at least one layer. Reviewing the three pairwise-coupling literatures - Planning-Scheduling, Scheduling-Behavior, and Planning-Behavior - we show that the omitted third layer is typically fixed exogenously or represented by a static aggregate surrogate. These simplifications enable tractability but impose distinct costs: they can obscure long-term investment feedback, temporal grid and emissions dynamics, or heterogeneous user response and equity outcomes. Building on this diagnosis, we identify open challenges in emerging charging technologies, behavioral incentives, equity metrics, and city-scale learning-based methods that balance fidelity, interpretability, and policy relevance.
Grid-Aware Charging and Operational Optimization for Mixed-Fleet Public Transit
Jan 13, 2026The rapid growth of urban populations and the increasing need for sustainable transportation solutions have prompted a shift towards electric buses in public transit systems. However, the effective management of mixed fleets consisting of both electric and diesel buses poses significant operational challenges. One major challenge is coping with dynamic electricity pricing, where charging costs vary throughout the day. Transit agencies must optimize charging assignments in response to such dynamism while accounting for secondary considerations such as seating constraints. This paper presents a comprehensive mixed-integer linear programming (MILP) model to address these challenges by jointly optimizing charging schedules and trip assignments for mixed (electric and diesel bus) fleets while considering factors such as dynamic electricity pricing, vehicle capacity, and route constraints. We address the potential computational intractability of the MILP formulation, which can arise even with relatively small fleets, by employing a hierarchical approach tailored to the fleet composition. By using real-world data from the city of Chattanooga, Tennessee, USA, we show that our approach can result in significant savings in the operating costs of the mixed transit fleets.
* 7 pages, 7 figures, 4 algorithms. Published in the Proceedings of the 2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC)
Online Decision-Making Under Uncertainty for Vehicle-to-Building Systems
Jan 07, 2026Vehicle-to-building (V2B) systems integrate physical infrastructures, such as smart buildings and electric vehicles (EVs) connected to chargers at the building, with digital control mechanisms to manage energy use. By utilizing EVs as flexible energy reservoirs, buildings can dynamically charge and discharge them to optimize energy use and cut costs under time-variable pricing and demand charge policies. This setup leads to the V2B optimization problem, where buildings coordinate EV charging and discharging to minimize total electricity costs while meeting users' charging requirements. However, the V2B optimization problem is challenging because of: (1) fluctuating electricity pricing, which includes both energy charges ($/kWh) and demand charges ($/kW); (2) long planning horizons (typically over 30 days); (3) heterogeneous chargers with varying charging rates, controllability, and directionality (i.e., unidirectional or bidirectional); and (4) user-specific battery levels at departure to ensure user requirements are met. In contrast to existing approaches that often model this setting as a single-shot combinatorial optimization problem, we highlight critical limitations in prior work and instead model the V2B optimization problem as a Markov decision process (MDP), i.e., a stochastic control process. Solving the resulting MDP is challenging due to the large state and action spaces. To address the challenges of the large state space, we leverage online search, and we counter the action space by using domain-specific heuristics to prune unpromising actions. We validate our approach in collaboration with Nissan Advanced Technology Center - Silicon Valley. Using data from their EV testbed, we show that the proposed framework significantly outperforms state-of-the-art methods.
* 17 pages, 2 figures, 10 tables. Published in the Proceedings of the 16th ACM/IEEE International Conference on Cyber-Physical Systems (ICCPS '25), May 06--09, 2025, Irvine, CA, USA
CONSENT: A Negotiation Framework for Leveraging User Flexibility in Vehicle-to-Building Charging under Uncertainty
Jan 04, 2026The growth of Electric Vehicles (EVs) creates a conflict in vehicle-to-building (V2B) settings between building operators, who face high energy costs from uncoordinated charging, and drivers, who prioritize convenience and a full charge. To resolve this, we propose a negotiation-based framework that, by design, guarantees voluntary participation, strategy-proofness, and budget feasibility. It transforms EV charging into a strategic resource by offering drivers a range of incentive-backed options for modest flexibility in their departure time or requested state of charge (SoC). Our framework is calibrated with user survey data and validated using real operational data from a commercial building and an EV manufacturer. Simulations show that our negotiation protocol creates a mutually beneficial outcome: lowering the building operator's costs by over 3.5\% compared to an optimized, non-negotiating smart charging policy, while simultaneously reducing user charging expenses by 22\% below the utility's retail energy rate. By aligning operator and EV user objectives, our framework provides a strategic bridge between energy and mobility systems, transforming EV charging from a source of operational friction into a platform for collaboration and shared savings.
Combining LLMs with Logic-Based Framework to Explain MCTS
May 01, 2025

In response to the lack of trust in Artificial Intelligence (AI) for sequential planning, we design a Computational Tree Logic-guided large language model (LLM)-based natural language explanation framework designed for the Monte Carlo Tree Search (MCTS) algorithm. MCTS is often considered challenging to interpret due to the complexity of its search trees, but our framework is flexible enough to handle a wide range of free-form post-hoc queries and knowledge-based inquiries centered around MCTS and the Markov Decision Process (MDP) of the application domain. By transforming user queries into logic and variable statements, our framework ensures that the evidence obtained from the search tree remains factually consistent with the underlying environmental dynamics and any constraints in the actual stochastic control process. We evaluate the framework rigorously through quantitative assessments, where it demonstrates strong performance in terms of accuracy and factual consistency.
Observation Adaptation via Annealed Importance Resampling for Partially Observable Markov Decision Processes
Mar 25, 2025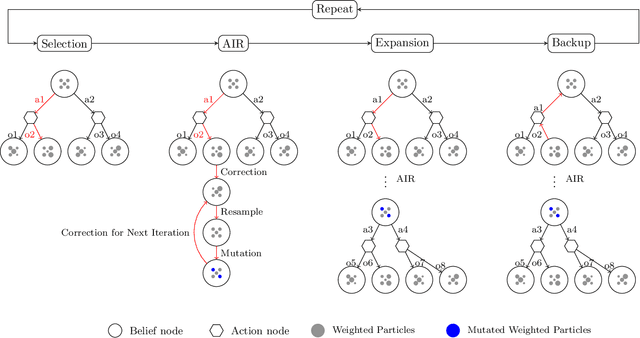
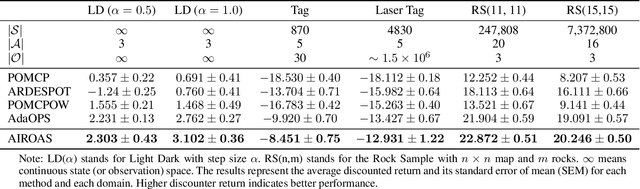
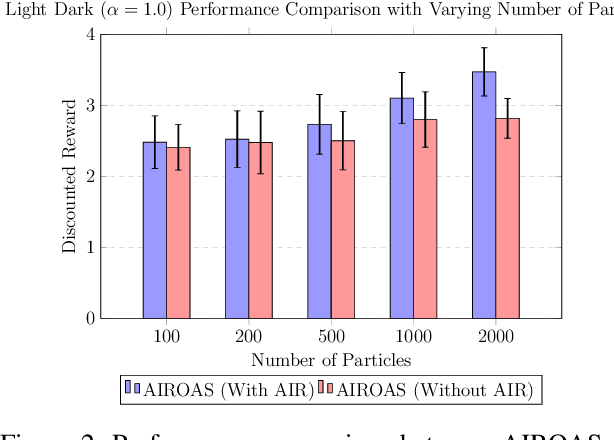
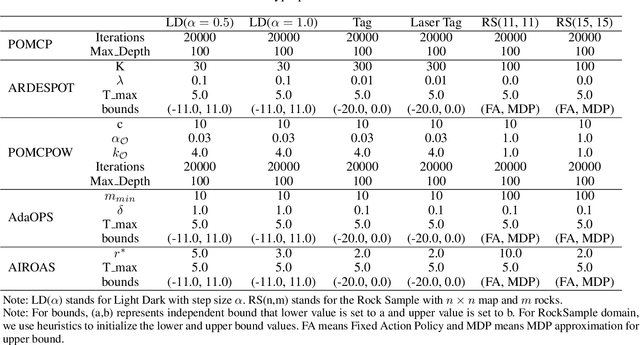
Partially observable Markov decision processes (POMDPs) are a general mathematical model for sequential decision-making in stochastic environments under state uncertainty. POMDPs are often solved \textit{online}, which enables the algorithm to adapt to new information in real time. Online solvers typically use bootstrap particle filters based on importance resampling for updating the belief distribution. Since directly sampling from the ideal state distribution given the latest observation and previous state is infeasible, particle filters approximate the posterior belief distribution by propagating states and adjusting weights through prediction and resampling steps. However, in practice, the importance resampling technique often leads to particle degeneracy and sample impoverishment when the state transition model poorly aligns with the posterior belief distribution, especially when the received observation is highly informative. We propose an approach that constructs a sequence of bridge distributions between the state-transition and optimal distributions through iterative Monte Carlo steps, better accommodating noisy observations in online POMDP solvers. Our algorithm demonstrates significantly superior performance compared to state-of-the-art methods when evaluated across multiple challenging POMDP domains.
Scalable Decision-Making in Stochastic Environments through Learned Temporal Abstraction
Feb 28, 2025Sequential decision-making in high-dimensional continuous action spaces, particularly in stochastic environments, faces significant computational challenges. We explore this challenge in the traditional offline RL setting, where an agent must learn how to make decisions based on data collected through a stochastic behavior policy. We present \textit{Latent Macro Action Planner} (L-MAP), which addresses this challenge by learning a set of temporally extended macro-actions through a state-conditional Vector Quantized Variational Autoencoder (VQ-VAE), effectively reducing action dimensionality. L-MAP employs a (separate) learned prior model that acts as a latent transition model and allows efficient sampling of plausible actions. During planning, our approach accounts for stochasticity in both the environment and the behavior policy by using Monte Carlo tree search (MCTS). In offline RL settings, including stochastic continuous control tasks, L-MAP efficiently searches over discrete latent actions to yield high expected returns. Empirical results demonstrate that L-MAP maintains low decision latency despite increased action dimensionality. Notably, across tasks ranging from continuous control with inherently stochastic dynamics to high-dimensional robotic hand manipulation, L-MAP significantly outperforms existing model-based methods and performs on-par with strong model-free actor-critic baselines, highlighting the effectiveness of the proposed approach in planning in complex and stochastic environments with high-dimensional action spaces.
Reinforcement Learning-based Approach for Vehicle-to-Building Charging with Heterogeneous Agents and Long Term Rewards
Feb 24, 2025Strategic aggregation of electric vehicle batteries as energy reservoirs can optimize power grid demand, benefiting smart and connected communities, especially large office buildings that offer workplace charging. This involves optimizing charging and discharging to reduce peak energy costs and net peak demand, monitored over extended periods (e.g., a month), which involves making sequential decisions under uncertainty and delayed and sparse rewards, a continuous action space, and the complexity of ensuring generalization across diverse conditions. Existing algorithmic approaches, e.g., heuristic-based strategies, fall short in addressing real-time decision-making under dynamic conditions, and traditional reinforcement learning (RL) models struggle with large state-action spaces, multi-agent settings, and the need for long-term reward optimization. To address these challenges, we introduce a novel RL framework that combines the Deep Deterministic Policy Gradient approach (DDPG) with action masking and efficient MILP-driven policy guidance. Our approach balances the exploration of continuous action spaces to meet user charging demands. Using real-world data from a major electric vehicle manufacturer, we show that our approach comprehensively outperforms many well-established baselines and several scalable heuristic approaches, achieving significant cost savings while meeting all charging requirements. Our results show that the proposed approach is one of the first scalable and general approaches to solving the V2B energy management challenge.
NS-Gym: Open-Source Simulation Environments and Benchmarks for Non-Stationary Markov Decision Processes
Jan 16, 2025



In many real-world applications, agents must make sequential decisions in environments where conditions are subject to change due to various exogenous factors. These non-stationary environments pose significant challenges to traditional decision-making models, which typically assume stationary dynamics. Non-stationary Markov decision processes (NS-MDPs) offer a framework to model and solve decision problems under such changing conditions. However, the lack of standardized benchmarks and simulation tools has hindered systematic evaluation and advance in this field. We present NS-Gym, the first simulation toolkit designed explicitly for NS-MDPs, integrated within the popular Gymnasium framework. In NS-Gym, we segregate the evolution of the environmental parameters that characterize non-stationarity from the agent's decision-making module, allowing for modular and flexible adaptations to dynamic environments. We review prior work in this domain and present a toolkit encapsulating key problem characteristics and types in NS-MDPs. This toolkit is the first effort to develop a set of standardized interfaces and benchmark problems to enable consistent and reproducible evaluation of algorithms under non-stationary conditions. We also benchmark six algorithmic approaches from prior work on NS-MDPs using NS-Gym. Our vision is that NS-Gym will enable researchers to assess the adaptability and robustness of their decision-making algorithms to non-stationary conditions.
Shrinking POMCP: A Framework for Real-Time UAV Search and Rescue
Nov 20, 2024



Efficient path optimization for drones in search and rescue operations faces challenges, including limited visibility, time constraints, and complex information gathering in urban environments. We present a comprehensive approach to optimize UAV-based search and rescue operations in neighborhood areas, utilizing both a 3D AirSim-ROS2 simulator and a 2D simulator. The path planning problem is formulated as a partially observable Markov decision process (POMDP), and we propose a novel ``Shrinking POMCP'' approach to address time constraints. In the AirSim environment, we integrate our approach with a probabilistic world model for belief maintenance and a neurosymbolic navigator for obstacle avoidance. The 2D simulator employs surrogate ROS2 nodes with equivalent functionality. We compare trajectories generated by different approaches in the 2D simulator and evaluate performance across various belief types in the 3D AirSim-ROS simulator. Experimental results from both simulators demonstrate that our proposed shrinking POMCP solution achieves significant improvements in search times compared to alternative methods, showcasing its potential for enhancing the efficiency of UAV-assisted search and rescue operations.