 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting and Mitigating Disruptions in Public Bus Transit Services
Mar 06, 2024



Public transportation systems often suffer from unexpected fluctuations in demand and disruptions, such as mechanical failures and medical emergencies. These fluctuations and disruptions lead to delays and overcrowding, which are detrimental to the passengers' experience and to the overall performance of the transit service. To proactively mitigate such events, many transit agencies station substitute (reserve) vehicles throughout their service areas, which they can dispatch to augment or replace vehicles on routes that suffer overcrowding or disruption. However, determining the optimal locations where substitute vehicles should be stationed is a challenging problem due to the inherent randomness of disruptions and due to the combinatorial nature of selecting locations across a city. In collaboration with the transit agency of Nashville, TN, we address this problem by introducing data-driven statistical and machine-learning models for forecasting disruptions and an effective randomized local-search algorithm for selecting locations where substitute vehicles are to be stationed. Our research demonstrates promising results in proactive disruption management, offering a practical and easily implementable solution for transit agencies to enhance the reliability of their services. Our results resonate beyond mere operational efficiency: by advancing proactive strategies, our approach fosters more resilient and accessible public transportation, contributing to equitable urban mobility and ultimately benefiting the communities that rely on public transportation the most.
On Designing Day Ahead and Same Day Ridership Level Prediction Models for City-Scale Transit Networks Using Noisy APC Data
Oct 10, 2022

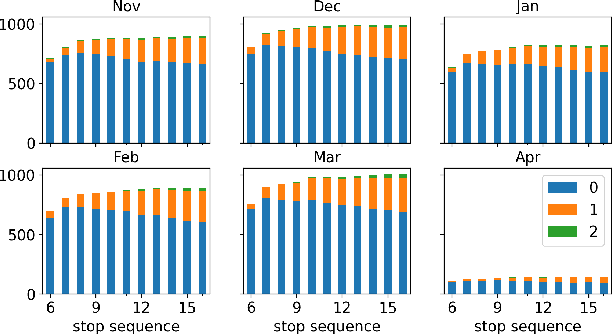

The ability to accurately predict public transit ridership demand benefits passengers and transit agencies. Agencies will be able to reallocate buses to handle under or over-utilized bus routes, improving resource utilization, and passengers will be able to adjust and plan their schedules to avoid overcrowded buses and maintain a certain level of comfort. However, accurately predicting occupancy is a non-trivial task. Various reasons such as heterogeneity, evolving ridership patterns, exogenous events like weather, and other stochastic variables, make the task much more challenging. With the progress of big data, transit authorities now have access to real-time passenger occupancy information for their vehicles. The amount of data generated is staggering. While there is no shortage in data, it must still be cleaned, processed, augmented, and merged before any useful information can be generated. In this paper, we propose the use and fusion of data from multiple sources, cleaned, processed, and merged together, for use in training machine learning models to predict transit ridership. We use data that spans a 2-year period (2020-2022) incorporating transit, weather, traffic, and calendar data. The resulting data, which equates to 17 million observations, is used to train separate models for the trip and stop level prediction. We evaluate our approach on real-world transit data provided by the public transit agency of Nashville, TN. We demonstrate that the trip level model based on Xgboost and the stop level model based on LSTM outperform the baseline statistical model across the entire transit service day.