 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColumn Generation for the Micro-Transit Zoning Problem
Mar 08, 2026Along with the rapid development of new urban mobility options like ride-sharing over the past decade, on-demand micro-transit services stand out as a middle ground, bridging the gap between fixed-line mass transit and single-request ride-hailing, balancing ridership maximization and travel time minimization. Micro-transit adoption can have significant social impact. It improves urban sustainability, through lower energy consumption and reduced emissions, while enhancing equitable mobility access for disadvantaged communities, thanks to its lower vehicle miles per passenger, flexible schedules, and affordable pricing. However, effective operation of micro-transit services requires planning geo-fenced zones in advance, which involves solving a challenging combinatorial optimization problem. Existing approaches enumerate candidate zones first and selects a fixed number of optimal zones in the second step. In this paper, we generalize the Micro-Transit Zoning Problem (MZP) to allow a global budget rather than imposing a size limit for candidate zones. We also design a Column Generation (CG) framework to solve the problem and several pricing heuristics to accelerate computation. Extensive numerical experiments across major U.S. cities demonstrate that our approach produces higher-quality solutions more efficiently and scales better in the generalized setting.
Grid-Aware Charging and Operational Optimization for Mixed-Fleet Public Transit
Jan 13, 2026The rapid growth of urban populations and the increasing need for sustainable transportation solutions have prompted a shift towards electric buses in public transit systems. However, the effective management of mixed fleets consisting of both electric and diesel buses poses significant operational challenges. One major challenge is coping with dynamic electricity pricing, where charging costs vary throughout the day. Transit agencies must optimize charging assignments in response to such dynamism while accounting for secondary considerations such as seating constraints. This paper presents a comprehensive mixed-integer linear programming (MILP) model to address these challenges by jointly optimizing charging schedules and trip assignments for mixed (electric and diesel bus) fleets while considering factors such as dynamic electricity pricing, vehicle capacity, and route constraints. We address the potential computational intractability of the MILP formulation, which can arise even with relatively small fleets, by employing a hierarchical approach tailored to the fleet composition. By using real-world data from the city of Chattanooga, Tennessee, USA, we show that our approach can result in significant savings in the operating costs of the mixed transit fleets.
* 7 pages, 7 figures, 4 algorithms. Published in the Proceedings of the 2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC)
Scalable Decision-Making in Stochastic Environments through Learned Temporal Abstraction
Feb 28, 2025Sequential decision-making in high-dimensional continuous action spaces, particularly in stochastic environments, faces significant computational challenges. We explore this challenge in the traditional offline RL setting, where an agent must learn how to make decisions based on data collected through a stochastic behavior policy. We present \textit{Latent Macro Action Planner} (L-MAP), which addresses this challenge by learning a set of temporally extended macro-actions through a state-conditional Vector Quantized Variational Autoencoder (VQ-VAE), effectively reducing action dimensionality. L-MAP employs a (separate) learned prior model that acts as a latent transition model and allows efficient sampling of plausible actions. During planning, our approach accounts for stochasticity in both the environment and the behavior policy by using Monte Carlo tree search (MCTS). In offline RL settings, including stochastic continuous control tasks, L-MAP efficiently searches over discrete latent actions to yield high expected returns. Empirical results demonstrate that L-MAP maintains low decision latency despite increased action dimensionality. Notably, across tasks ranging from continuous control with inherently stochastic dynamics to high-dimensional robotic hand manipulation, L-MAP significantly outperforms existing model-based methods and performs on-par with strong model-free actor-critic baselines, highlighting the effectiveness of the proposed approach in planning in complex and stochastic environments with high-dimensional action spaces.
NS-Gym: Open-Source Simulation Environments and Benchmarks for Non-Stationary Markov Decision Processes
Jan 16, 2025



In many real-world applications, agents must make sequential decisions in environments where conditions are subject to change due to various exogenous factors. These non-stationary environments pose significant challenges to traditional decision-making models, which typically assume stationary dynamics. Non-stationary Markov decision processes (NS-MDPs) offer a framework to model and solve decision problems under such changing conditions. However, the lack of standardized benchmarks and simulation tools has hindered systematic evaluation and advance in this field. We present NS-Gym, the first simulation toolkit designed explicitly for NS-MDPs, integrated within the popular Gymnasium framework. In NS-Gym, we segregate the evolution of the environmental parameters that characterize non-stationarity from the agent's decision-making module, allowing for modular and flexible adaptations to dynamic environments. We review prior work in this domain and present a toolkit encapsulating key problem characteristics and types in NS-MDPs. This toolkit is the first effort to develop a set of standardized interfaces and benchmark problems to enable consistent and reproducible evaluation of algorithms under non-stationary conditions. We also benchmark six algorithmic approaches from prior work on NS-MDPs using NS-Gym. Our vision is that NS-Gym will enable researchers to assess the adaptability and robustness of their decision-making algorithms to non-stationary conditions.
Forecasting and Mitigating Disruptions in Public Bus Transit Services
Mar 06, 2024



Public transportation systems often suffer from unexpected fluctuations in demand and disruptions, such as mechanical failures and medical emergencies. These fluctuations and disruptions lead to delays and overcrowding, which are detrimental to the passengers' experience and to the overall performance of the transit service. To proactively mitigate such events, many transit agencies station substitute (reserve) vehicles throughout their service areas, which they can dispatch to augment or replace vehicles on routes that suffer overcrowding or disruption. However, determining the optimal locations where substitute vehicles should be stationed is a challenging problem due to the inherent randomness of disruptions and due to the combinatorial nature of selecting locations across a city. In collaboration with the transit agency of Nashville, TN, we address this problem by introducing data-driven statistical and machine-learning models for forecasting disruptions and an effective randomized local-search algorithm for selecting locations where substitute vehicles are to be stationed. Our research demonstrates promising results in proactive disruption management, offering a practical and easily implementable solution for transit agencies to enhance the reliability of their services. Our results resonate beyond mere operational efficiency: by advancing proactive strategies, our approach fosters more resilient and accessible public transportation, contributing to equitable urban mobility and ultimately benefiting the communities that rely on public transportation the most.
Decision Making in Non-Stationary Environments with Policy-Augmented Search
Jan 06, 2024



Sequential decision-making under uncertainty is present in many important problems. Two popular approaches for tackling such problems are reinforcement learning and online search (e.g., Monte Carlo tree search). While the former learns a policy by interacting with the environment (typically done before execution), the latter uses a generative model of the environment to sample promising action trajectories at decision time. Decision-making is particularly challenging in non-stationary environments, where the environment in which an agent operates can change over time. Both approaches have shortcomings in such settings -- on the one hand, policies learned before execution become stale when the environment changes and relearning takes both time and computational effort. Online search, on the other hand, can return sub-optimal actions when there are limitations on allowed runtime. In this paper, we introduce \textit{Policy-Augmented Monte Carlo tree search} (PA-MCTS), which combines action-value estimates from an out-of-date policy with an online search using an up-to-date model of the environment. We prove theoretical results showing conditions under which PA-MCTS selects the one-step optimal action and also bound the error accrued while following PA-MCTS as a policy. We compare and contrast our approach with AlphaZero, another hybrid planning approach, and Deep Q Learning on several OpenAI Gym environments. Through extensive experiments, we show that under non-stationary settings with limited time constraints, PA-MCTS outperforms these baselines.
Hierarchical Multi-Agent Reinforcement Learning for Assessing False-Data Injection Attacks on Transportation Networks
Dec 22, 2023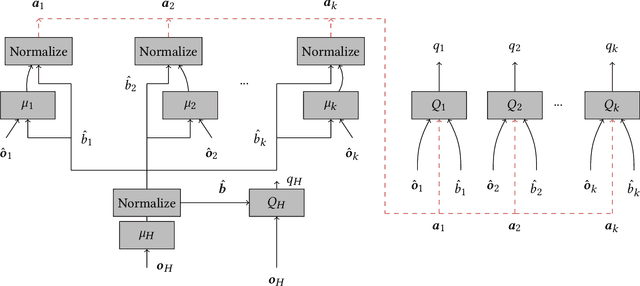
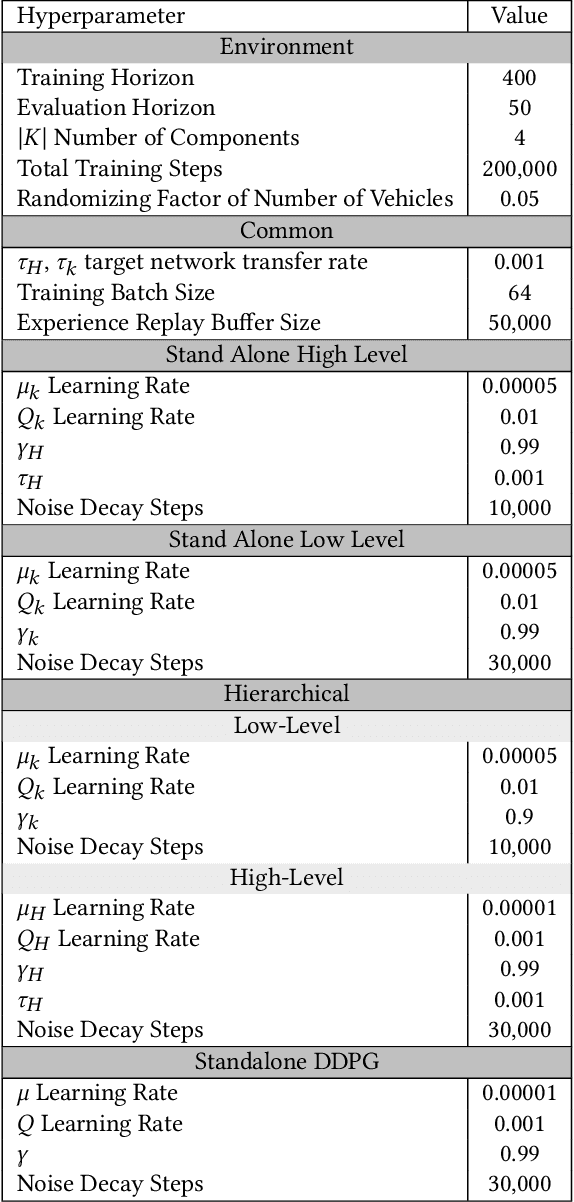
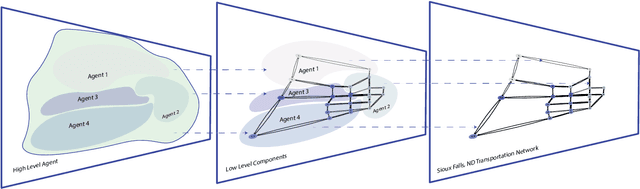
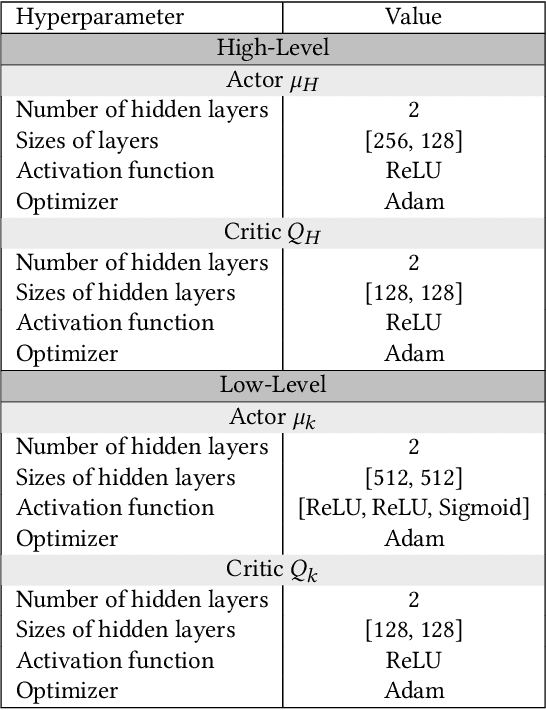
The increasing reliance of drivers on navigation applications has made transportation networks more susceptible to data-manipulation attacks by malicious actors. Adversaries may exploit vulnerabilities in the data collection or processing of navigation services to inject false information, and to thus interfere with the drivers' route selection. Such attacks can significantly increase traffic congestions, resulting in substantial waste of time and resources, and may even disrupt essential services that rely on road networks. To assess the threat posed by such attacks, we introduce a computational framework to find worst-case data-injection attacks against transportation networks. First, we devise an adversarial model with a threat actor who can manipulate drivers by increasing the travel times that they perceive on certain roads. Then, we employ hierarchical multi-agent reinforcement learning to find an approximate optimal adversarial strategy for data manipulation. We demonstrate the applicability of our approach through simulating attacks on the Sioux Falls, ND network topology.
Task Grouping for Automated Multi-Task Machine Learning via Task Affinity Prediction
Oct 24, 2023



When a number of similar tasks have to be learned simultaneously, multi-task learning (MTL) models can attain significantly higher accuracy than single-task learning (STL) models. However, the advantage of MTL depends on various factors, such as the similarity of the tasks, the sizes of the datasets, and so on; in fact, some tasks might not benefit from MTL and may even incur a loss of accuracy compared to STL. Hence, the question arises: which tasks should be learned together? Domain experts can attempt to group tasks together following intuition, experience, and best practices, but manual grouping can be labor-intensive and far from optimal. In this paper, we propose a novel automated approach for task grouping. First, we study the affinity of tasks for MTL using four benchmark datasets that have been used extensively in the MTL literature, focusing on neural network-based MTL models. We identify inherent task features and STL characteristics that can help us to predict whether a group of tasks should be learned together using MTL or if they should be learned independently using STL. Building on this predictor, we introduce a randomized search algorithm, which employs the predictor to minimize the number of MTL trainings performed during the search for task groups. We demonstrate on the four benchmark datasets that our predictor-driven search approach can find better task groupings than existing baseline approaches.
Artificial Intelligence for Smart Transportation
Aug 14, 2023


There are more than 7,000 public transit agencies in the U.S. (and many more private agencies), and together, they are responsible for serving 60 billion passenger miles each year. A well-functioning transit system fosters the growth and expansion of businesses, distributes social and economic benefits, and links the capabilities of community members, thereby enhancing what they can accomplish as a society. Since affordable public transit services are the backbones of many communities, this work investigates ways in which Artificial Intelligence (AI) can improve efficiency and increase utilization from the perspective of transit agencies. This book chapter discusses the primary requirements, objectives, and challenges related to the design of AI-driven smart transportation systems. We focus on three major topics. First, we discuss data sources and data. Second, we provide an overview of how AI can aid decision-making with a focus on transportation. Lastly, we discuss computational problems in the transportation domain and AI approaches to these problems.
Rolling Horizon based Temporal Decomposition for the Offline Pickup and Delivery Problem with Time Windows
Mar 06, 2023



The offline pickup and delivery problem with time windows (PDPTW) is a classical combinatorial optimization problem in the transportation community, which has proven to be very challenging computationally. Due to the complexity of the problem, practical problem instances can be solved only via heuristics, which trade-off solution quality for computational tractability. Among the various heuristics, a common strategy is problem decomposition, that is, the reduction of a large-scale problem into a collection of smaller sub-problems, with spatial and temporal decompositions being two natural approaches. While spatial decomposition has been successful in certain settings, effective temporal decomposition has been challenging due to the difficulty of stitching together the sub-problem solutions across the decomposition boundaries. In this work, we introduce a novel temporal decomposition scheme for solving a class of PDPTWs that have narrow time windows, for which it is able to provide both fast and high-quality solutions. We utilize techniques that have been popularized recently in the context of online dial-a-ride problems along with the general idea of rolling horizon optimization. To the best of our knowledge, this is the first attempt to solve offline PDPTWs using such an approach. To show the performance and scalability of our framework, we use the optimization of paratransit services as a motivating example. We compare our results with an offline heuristic algorithm using Google OR-Tools. In smaller problem instances, the baseline approach is as competitive as our framework. However, in larger problem instances, our framework is more scalable and can provide good solutions to problem instances of varying degrees of difficulty, while the baseline algorithm often fails to find a feasible solution within comparable compute times.