 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Robot Coordination for Planning under Context Uncertainty
Mar 14, 2026Real-world robots often operate in settings where objective priorities depend on the underlying context of operation. When the underlying context is unknown apriori, multiple robots may have to coordinate to gather informative observations to infer the context, since acting based on an incorrect context can lead to misaligned and unsafe behavior. Once the underlying true context is inferred, the robots optimize their task-specific objectives in the preference order induced by the context. We formalize this problem as a Multi-Robot Context-Uncertain Stochastic Shortest Path (MR-CUSSP), which captures context-relevant information at landmark states through joint observations. Our two-stage solution approach is composed of: (1) CIMOP (Coordinated Inference for Multi-Objective Planning) to compute plans that guide robots toward informative landmarks to efficiently infer the true context, and (2) LCBS (Lexicographic Conflict-Based Search) for collision-free multi-robot path planning with lexicographic objective preferences, induced by the context. We evaluate the algorithms using three simulated domains and demonstrate its practical applicability using five mobile robots in the salp domain setup.
Multi-Objective Multi-Agent Path Finding with Lexicographic Cost Preferences
Oct 08, 2025Many real-world scenarios require multiple agents to coordinate in shared environments, while balancing trade-offs between multiple, potentially competing objectives. Current multi-objective multi-agent path finding (MO-MAPF) algorithms typically produce conflict-free plans by computing Pareto frontiers. They do not explicitly optimize for user-defined preferences, even when the preferences are available, and scale poorly with the number of objectives. We propose a lexicographic framework for modeling MO-MAPF, along with an algorithm \textit{Lexicographic Conflict-Based Search} (LCBS) that directly computes a single solution aligned with a lexicographic preference over objectives. LCBS integrates a priority-aware low-level $A^*$ search with conflict-based search, avoiding Pareto frontier construction and enabling efficient planning guided by preference over objectives. We provide insights into optimality and scalability, and empirically demonstrate that LCBS computes optimal solutions while scaling to instances with up to ten objectives -- far beyond the limits of existing MO-MAPF methods. Evaluations on standard and randomized MAPF benchmarks show consistently higher success rates against state-of-the-art baselines, especially with increasing number of objectives.
NS-Gym: Open-Source Simulation Environments and Benchmarks for Non-Stationary Markov Decision Processes
Jan 16, 2025



In many real-world applications, agents must make sequential decisions in environments where conditions are subject to change due to various exogenous factors. These non-stationary environments pose significant challenges to traditional decision-making models, which typically assume stationary dynamics. Non-stationary Markov decision processes (NS-MDPs) offer a framework to model and solve decision problems under such changing conditions. However, the lack of standardized benchmarks and simulation tools has hindered systematic evaluation and advance in this field. We present NS-Gym, the first simulation toolkit designed explicitly for NS-MDPs, integrated within the popular Gymnasium framework. In NS-Gym, we segregate the evolution of the environmental parameters that characterize non-stationarity from the agent's decision-making module, allowing for modular and flexible adaptations to dynamic environments. We review prior work in this domain and present a toolkit encapsulating key problem characteristics and types in NS-MDPs. This toolkit is the first effort to develop a set of standardized interfaces and benchmark problems to enable consistent and reproducible evaluation of algorithms under non-stationary conditions. We also benchmark six algorithmic approaches from prior work on NS-MDPs using NS-Gym. Our vision is that NS-Gym will enable researchers to assess the adaptability and robustness of their decision-making algorithms to non-stationary conditions.
Multi-Objective Policy Gradients with Topological Constraints
Sep 15, 2022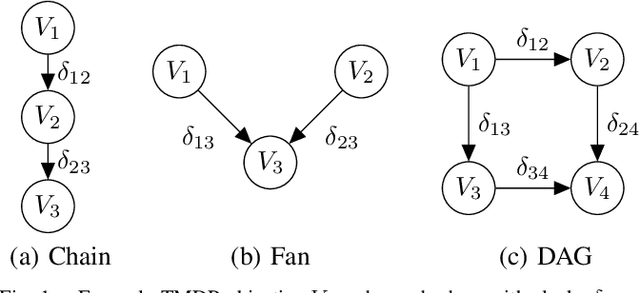


Multi-objective optimization models that encode ordered sequential constraints provide a solution to model various challenging problems including encoding preferences, modeling a curriculum, and enforcing measures of safety. A recently developed theory of topological Markov decision processes (TMDPs) captures this range of problems for the case of discrete states and actions. In this work, we extend TMDPs towards continuous spaces and unknown transition dynamics by formulating, proving, and implementing the policy gradient theorem for TMDPs. This theoretical result enables the creation of TMDP learning algorithms that use function approximators, and can generalize existing deep reinforcement learning (DRL) approaches. Specifically, we present a new algorithm for a policy gradient in TMDPs by a simple extension of the proximal policy optimization (PPO) algorithm. We demonstrate this on a real-world multiple-objective navigation problem with an arbitrary ordering of objectives both in simulation and on a real robot.
Competence-Aware Path Planning via Introspective Perception
Sep 28, 2021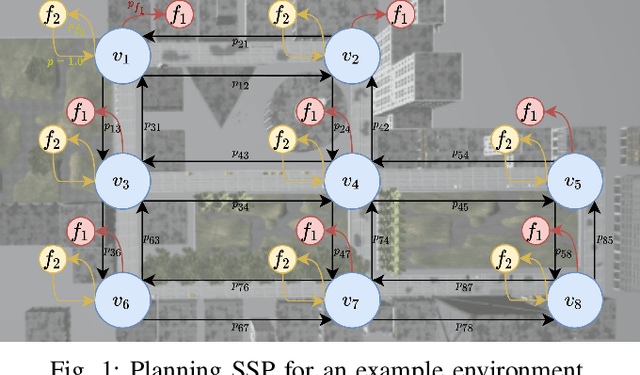
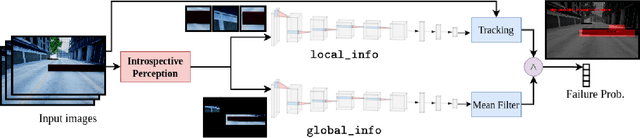

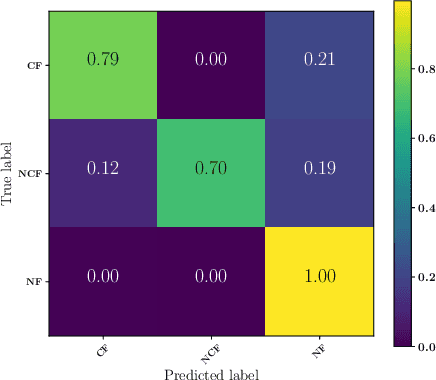
Robots deployed in the real world over extended periods of time need to reason about unexpected failures, learn to predict them, and to proactively take actions to avoid future failures. Existing approaches for competence-aware planning are either model-based, requiring explicit enumeration of known failure modes, or purely statistical, using state- and location-specific failure statistics to infer competence. We instead propose a structured model-free approach to competence-aware planning by reasoning about plan execution failures due to errors in perception, without requiring a-priori enumeration of failure modes or requiring location-specific failure statistics. We introduce competence-aware path planning via introspective perception (CPIP), a Bayesian framework to iteratively learn and exploit task-level competence in novel deployment environments. CPIP factorizes the competence-aware planning problem into two components. First, perception errors are learned in a model-free and location-agnostic setting via introspective perception prior to deployment in novel environments. Second, during actual deployments, the prediction of task-level failures is learned in a context-aware setting. Experiments in a simulation show that the proposed CPIP approach outperforms the frequentist baseline in multiple mobile robot tasks, and is further validated via real robot experiments in an environment with perceptually challenging obstacles and terrain.
Improving Competence for Reliable Autonomy
Jul 23, 2020
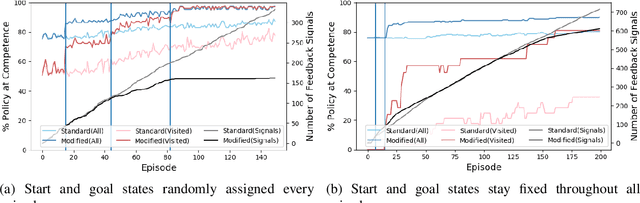
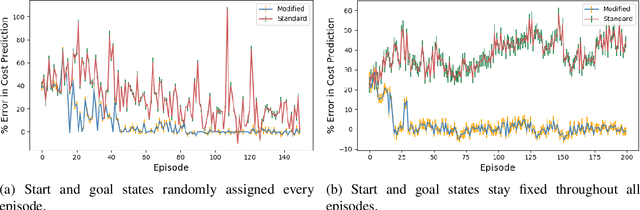
Given the complexity of real-world, unstructured domains, it is often impossible or impractical to design models that include every feature needed to handle all possible scenarios that an autonomous system may encounter. For an autonomous system to be reliable in such domains, it should have the ability to improve its competence online. In this paper, we propose a method for improving the competence of a system over the course of its deployment. We specifically focus on a class of semi-autonomous systems known as competence-aware systems that model their own competence -- the optimal extent of autonomy to use in any given situation -- and learn this competence over time from feedback received through interactions with a human authority. Our method exploits such feedback to identify important state features missing from the system's initial model, and incorporates them into its state representation. The result is an agent that better predicts human involvement, leading to improvements in its competence and reliability, and as a result, its overall performance.
* In Proceedings AREA 2020, arXiv:2007.11260
Learning to Optimize Autonomy in Competence-Aware Systems
Mar 17, 2020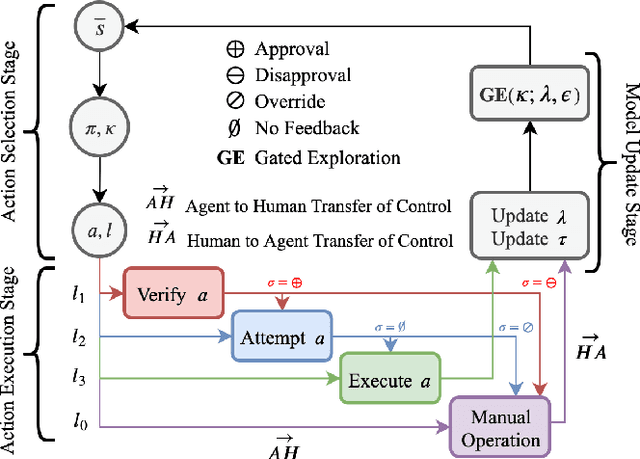
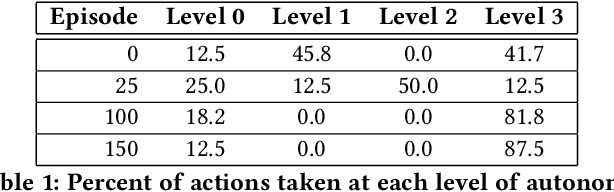
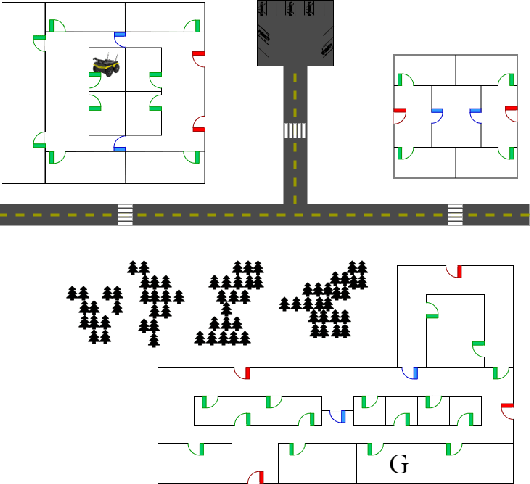
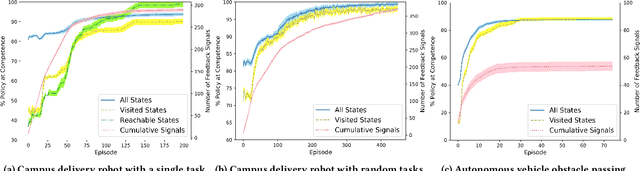
Interest in semi-autonomous systems (SAS) is growing rapidly as a paradigm to deploy autonomous systems in domains that require occasional reliance on humans. This paradigm allows service robots or autonomous vehicles to operate at varying levels of autonomy and offer safety in situations that require human judgment. We propose an introspective model of autonomy that is learned and updated online through experience and dictates the extent to which the agent can act autonomously in any given situation. We define a competence-aware system (CAS) that explicitly models its own proficiency at different levels of autonomy and the available human feedback. A CAS learns to adjust its level of autonomy based on experience to maximize overall efficiency, factoring in the cost of human assistance. We analyze the convergence properties of CAS and provide experimental results for robot delivery and autonomous driving domains that demonstrate the benefits of the approach.
Planning in Stochastic Environments with Goal Uncertainty
Oct 18, 2018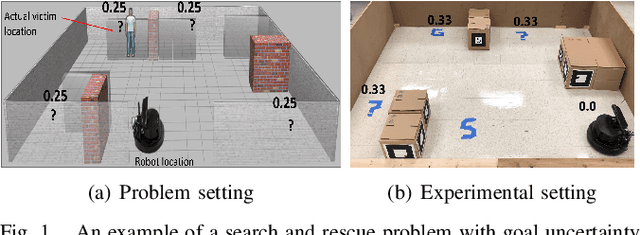

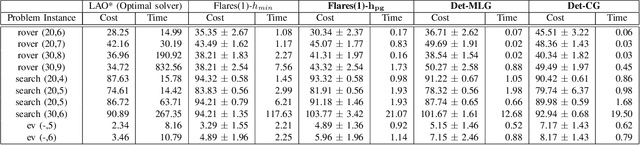
We present the Goal Uncertain Stochastic Shortest Path (GUSSP) problem --- a general framework to model stochastic environments with goal uncertainty. The model is an extension of the stochastic shortest path (SSP) framework to dynamic environments in which it is impossible to determine the exact goal states ahead of plan execution. GUSSPs introduce flexibility in goal specification by allowing a belief over possible goal configurations. The partial observability is restricted to goals, facilitating the reduction to an SSP. We formally define a GUSSP and discuss its theoretical properties. We then propose an admissible heuristic that reduces the planning time of FLARES --- a start-of-the-art probabilistic planner. We also propose a determinization approach for solving this class of problems. Finally, we present empirical results using a mobile robot and three other problem domains.