 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$L^*LM$: Learning Automata from Examples using Natural Language Oracles
Feb 10, 2024Expert demonstrations have proven an easy way to indirectly specify complex tasks. Recent algorithms even support extracting unambiguous formal specifications, e.g. deterministic finite automata (DFA), from demonstrations. Unfortunately, these techniques are generally not sample efficient. In this work, we introduce $L^*LM$, an algorithm for learning DFAs from both demonstrations and natural language. Due to the expressivity of natural language, we observe a significant improvement in the data efficiency of learning DFAs from expert demonstrations. Technically, $L^*LM$ leverages large language models to answer membership queries about the underlying task. This is then combined with recent techniques for transforming learning from demonstrations into a sequence of labeled example learning problems. In our experiments, we observe the two modalities complement each other, yielding a powerful few-shot learner.
Experience Filter: Using Past Experiences on Unseen Tasks or Environments
May 29, 2023
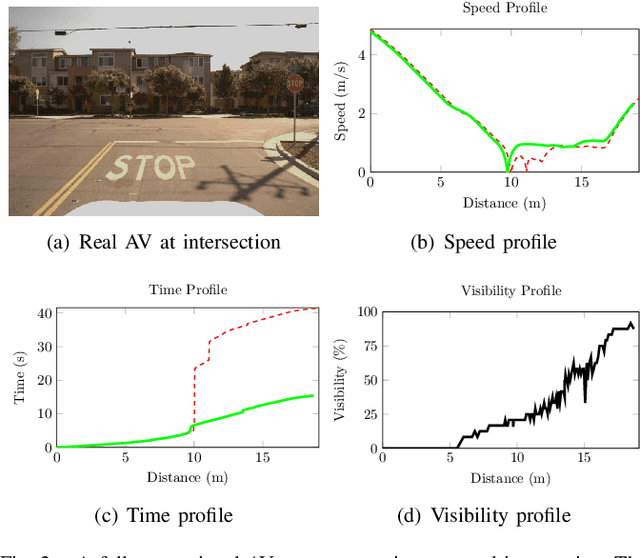


One of the bottlenecks of training autonomous vehicle (AV) agents is the variability of training environments. Since learning optimal policies for unseen environments is often very costly and requires substantial data collection, it becomes computationally intractable to train the agent on every possible environment or task the AV may encounter. This paper introduces a zero-shot filtering approach to interpolate learned policies of past experiences to generalize to unseen ones. We use an experience kernel to correlate environments. These correlations are then exploited to produce policies for new tasks or environments from learned policies. We demonstrate our methods on an autonomous vehicle driving through T-intersections with different characteristics, where its behavior is modeled as a partially observable Markov decision process (POMDP). We first construct compact representations of learned policies for POMDPs with unknown transition functions given a dataset of sequential actions and observations. Then, we filter parameterized policies of previously visited environments to generate policies to new, unseen environments. We demonstrate our approaches on both an actual AV and a high-fidelity simulator. Results indicate that our experience filter offers a fast, low-effort, and near-optimal solution to create policies for tasks or environments never seen before. Furthermore, the generated new policies outperform the policy learned using the entire data collected from past environments, suggesting that the correlation among different environments can be exploited and irrelevant ones can be filtered out.
Improving Competence for Reliable Autonomy
Jul 23, 2020
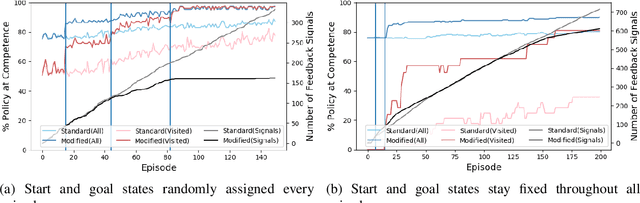
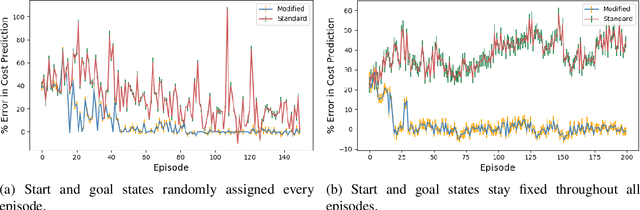
Given the complexity of real-world, unstructured domains, it is often impossible or impractical to design models that include every feature needed to handle all possible scenarios that an autonomous system may encounter. For an autonomous system to be reliable in such domains, it should have the ability to improve its competence online. In this paper, we propose a method for improving the competence of a system over the course of its deployment. We specifically focus on a class of semi-autonomous systems known as competence-aware systems that model their own competence -- the optimal extent of autonomy to use in any given situation -- and learn this competence over time from feedback received through interactions with a human authority. Our method exploits such feedback to identify important state features missing from the system's initial model, and incorporates them into its state representation. The result is an agent that better predicts human involvement, leading to improvements in its competence and reliability, and as a result, its overall performance.
* In Proceedings AREA 2020, arXiv:2007.11260