 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience Filter: Using Past Experiences on Unseen Tasks or Environments
May 29, 2023
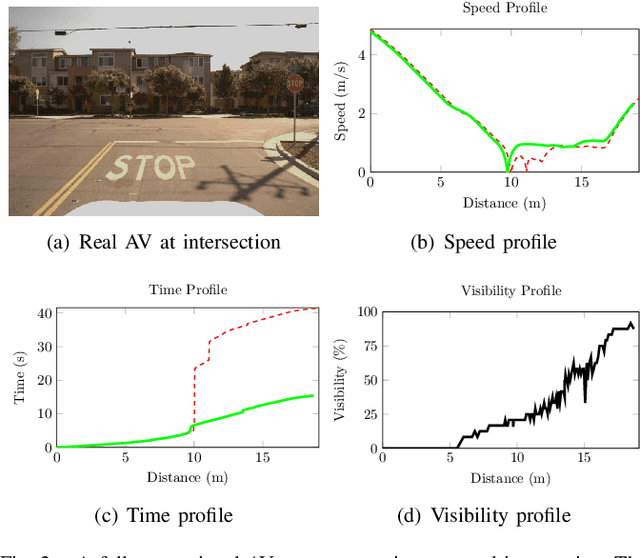


One of the bottlenecks of training autonomous vehicle (AV) agents is the variability of training environments. Since learning optimal policies for unseen environments is often very costly and requires substantial data collection, it becomes computationally intractable to train the agent on every possible environment or task the AV may encounter. This paper introduces a zero-shot filtering approach to interpolate learned policies of past experiences to generalize to unseen ones. We use an experience kernel to correlate environments. These correlations are then exploited to produce policies for new tasks or environments from learned policies. We demonstrate our methods on an autonomous vehicle driving through T-intersections with different characteristics, where its behavior is modeled as a partially observable Markov decision process (POMDP). We first construct compact representations of learned policies for POMDPs with unknown transition functions given a dataset of sequential actions and observations. Then, we filter parameterized policies of previously visited environments to generate policies to new, unseen environments. We demonstrate our approaches on both an actual AV and a high-fidelity simulator. Results indicate that our experience filter offers a fast, low-effort, and near-optimal solution to create policies for tasks or environments never seen before. Furthermore, the generated new policies outperform the policy learned using the entire data collected from past environments, suggesting that the correlation among different environments can be exploited and irrelevant ones can be filtered out.
Interpretable Local Tree Surrogate Policies
Sep 16, 2021
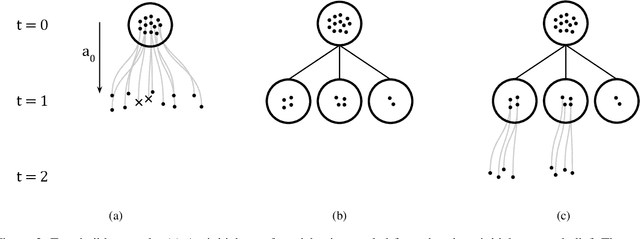
High-dimensional policies, such as those represented by neural networks, cannot be reasonably interpreted by humans. This lack of interpretability reduces the trust users have in policy behavior, limiting their use to low-impact tasks such as video games. Unfortunately, many methods rely on neural network representations for effective learning. In this work, we propose a method to build predictable policy trees as surrogates for policies such as neural networks. The policy trees are easily human interpretable and provide quantitative predictions of future behavior. We demonstrate the performance of this approach on several simulated tasks.
Improved POMDP Tree Search Planning with Prioritized Action Branching
Oct 07, 2020
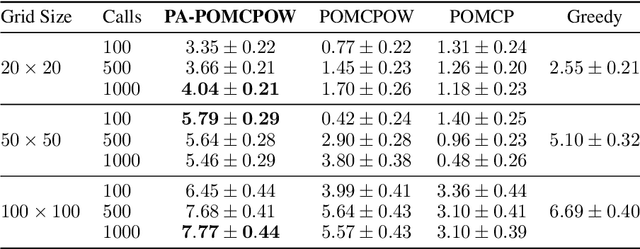
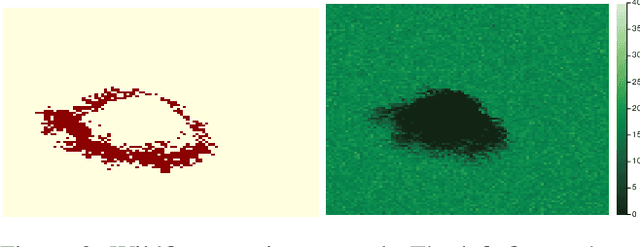
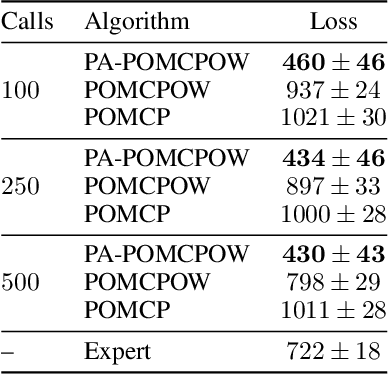
Online solvers for partially observable Markov decision processes have difficulty scaling to problems with large action spaces. This paper proposes a method called PA-POMCPOW to sample a subset of the action space that provides varying mixtures of exploitation and exploration for inclusion in a search tree. The proposed method first evaluates the action space according to a score function that is a linear combination of expected reward and expected information gain. The actions with the highest score are then added to the search tree during tree expansion. Experiments show that PA-POMCPOW is able to outperform existing state-of-the-art solvers on problems with large discrete action spaces.
Bayesian Optimized Monte Carlo Planning
Oct 07, 2020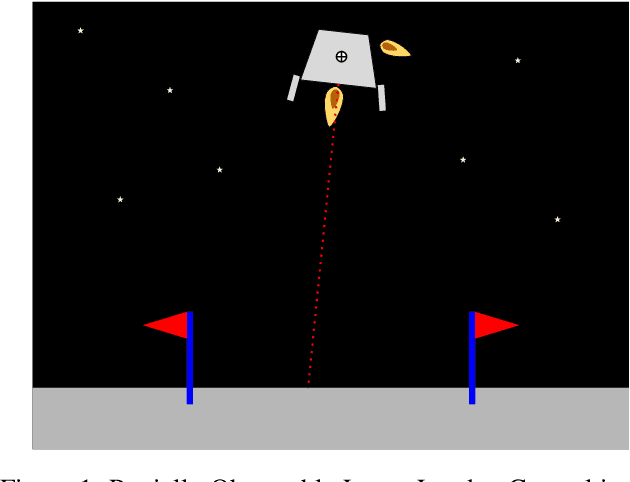
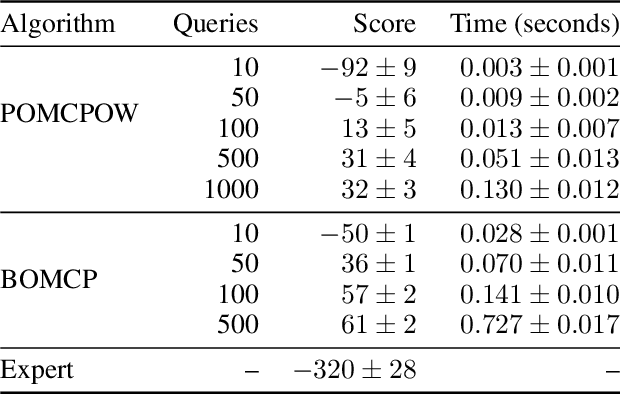
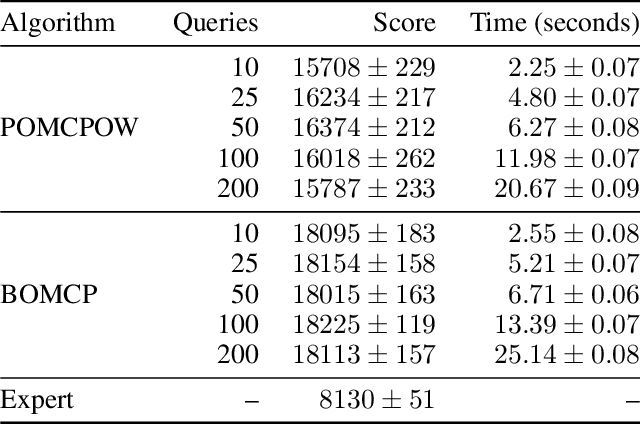
Online solvers for partially observable Markov decision processes have difficulty scaling to problems with large action spaces. Monte Carlo tree search with progressive widening attempts to improve scaling by sampling from the action space to construct a policy search tree. The performance of progressive widening search is dependent upon the action sampling policy, often requiring problem-specific samplers. In this work, we present a general method for efficient action sampling based on Bayesian optimization. The proposed method uses a Gaussian process to model a belief over the action-value function and selects the action that will maximize the expected improvement in the optimal action value. We implement the proposed approach in a new online tree search algorithm called Bayesian Optimized Monte Carlo Planning (BOMCP). Several experiments show that BOMCP is better able to scale to large action space POMDPs than existing state-of-the-art tree search solvers.