 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Semi-Decentralized Approach to Multiagent Control
Mar 12, 2026We introduce an expressive framework and algorithms for the semi-decentralized control of cooperative agents in environments with communication uncertainty. Whereas semi-Markov control admits a distribution over time for agent actions, semi-Markov communication, or what we refer to as semi-decentralization, gives a distribution over time for what actions and observations agents can store in their histories. We extend semi-decentralization to the partially observable Markov decision process (POMDP). The resulting SDec-POMDP unifies decentralized and multiagent POMDPs and several existing explicit communication mechanisms. We present recursive small-step semi-decentralized A* (RS-SDA*), an exact algorithm for generating optimal SDec-POMDP policies. RS-SDA* is evaluated on semi-decentralized versions of several standard benchmarks and a maritime medical evacuation scenario. This paper provides a well-defined theoretical foundation for exploring many classes of multiagent communication problems through the lens of semi-decentralization.
Aligning LLMs on a Budget: Inference-Time Alignment with Heuristic Reward Models
Aug 07, 2025



Aligning LLMs with user preferences is crucial for real-world use but often requires costly fine-tuning or expensive inference, forcing trade-offs between alignment quality and computational cost. Existing inference-time methods typically ignore this balance, focusing solely on the optimized policy's performance. We propose HIA (Heuristic-Guided Inference-time Alignment), a tuning-free, black-box-compatible approach that uses a lightweight prompt optimizer, heuristic reward models, and two-stage filtering to reduce inference calls while preserving alignment quality. On real-world prompt datasets, HelpSteer and ComPRed, HIA outperforms best-of-N sampling, beam search, and greedy search baselines in multi-objective, goal-conditioned tasks under the same inference budget. We also find that HIA is effective under low-inference budgets with as little as one or two response queries, offering a practical solution for scalable, personalized LLM deployment.
Semi-Markovian Planning to Coordinate Aerial and Maritime Medical Evacuation Platforms
Oct 06, 2024



The transfer of patients between two aircraft using an underway watercraft increases medical evacuation reach and flexibility in maritime environments. The selection of any one of multiple underway watercraft for patient exchange is complicated by participating aircraft utilization history and a participating watercraft position and velocity. The selection problem is modeled as a semi-Markov decision process with an action space including both fixed land and moving watercraft exchange points. Monte Carlo tree search with root parallelization is used to select optimal exchange points and determine aircraft dispatch times. Model parameters are varied in simulation to identify representative scenarios where watercraft exchange points reduce incident response times. We find that an optimal policy with watercraft exchange points outperforms an optimal policy without watercraft exchange points and a greedy policy by 35% and 40%, respectively. In partnership with the United States Army, we deploy for the first time the watercraft exchange point by executing a mock patient transfer with a manikin between two HH-60M medical evacuation helicopters and an underway Army Logistic Support Vessel south of the Hawaiian island of Oahu. Both helicopters were dispatched in accordance with our optimized decision strategy.
Rao-Blackwellized POMDP Planning
Sep 24, 2024



Partially Observable Markov Decision Processes (POMDPs) provide a structured framework for decision-making under uncertainty, but their application requires efficient belief updates. Sequential Importance Resampling Particle Filters (SIRPF), also known as Bootstrap Particle Filters, are commonly used as belief updaters in large approximate POMDP solvers, but they face challenges such as particle deprivation and high computational costs as the system's state dimension grows. To address these issues, this study introduces Rao-Blackwellized POMDP (RB-POMDP) approximate solvers and outlines generic methods to apply Rao-Blackwellization in both belief updates and online planning. We compare the performance of SIRPF and Rao-Blackwellized Particle Filters (RBPF) in a simulated localization problem where an agent navigates toward a target in a GPS-denied environment using POMCPOW and RB-POMCPOW planners. Our results not only confirm that RBPFs maintain accurate belief approximations over time with fewer particles, but, more surprisingly, RBPFs combined with quadrature-based integration improve planning quality significantly compared to SIRPF-based planning under the same computational limits.
Constrained Hierarchical Monte Carlo Belief-State Planning
Oct 30, 2023



Optimal plans in Constrained Partially Observable Markov Decision Processes (CPOMDPs) maximize reward objectives while satisfying hard cost constraints, generalizing safe planning under state and transition uncertainty. Unfortunately, online CPOMDP planning is extremely difficult in large or continuous problem domains. In many large robotic domains, hierarchical decomposition can simplify planning by using tools for low-level control given high-level action primitives (options). We introduce Constrained Options Belief Tree Search (COBeTS) to leverage this hierarchy and scale online search-based CPOMDP planning to large robotic problems. We show that if primitive option controllers are defined to satisfy assigned constraint budgets, then COBeTS will satisfy constraints anytime. Otherwise, COBeTS will guide the search towards a safe sequence of option primitives, and hierarchical monitoring can be used to achieve runtime safety. We demonstrate COBeTS in several safety-critical, constrained partially observable robotic domains, showing that it can plan successfully in continuous CPOMDPs while non-hierarchical baselines cannot.
Experience Filter: Using Past Experiences on Unseen Tasks or Environments
May 29, 2023
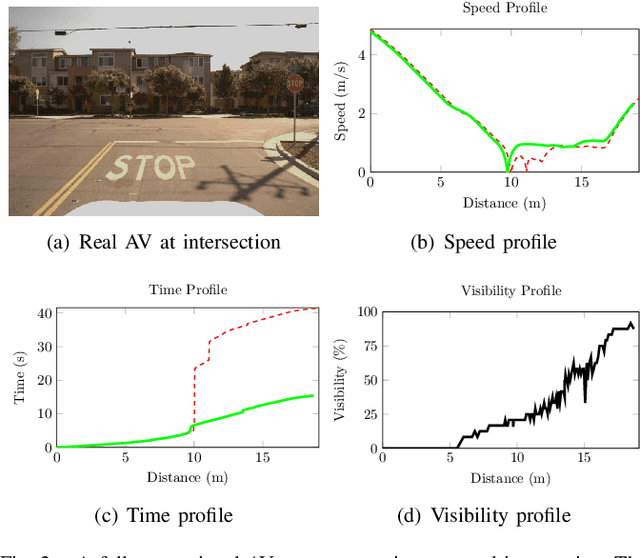


One of the bottlenecks of training autonomous vehicle (AV) agents is the variability of training environments. Since learning optimal policies for unseen environments is often very costly and requires substantial data collection, it becomes computationally intractable to train the agent on every possible environment or task the AV may encounter. This paper introduces a zero-shot filtering approach to interpolate learned policies of past experiences to generalize to unseen ones. We use an experience kernel to correlate environments. These correlations are then exploited to produce policies for new tasks or environments from learned policies. We demonstrate our methods on an autonomous vehicle driving through T-intersections with different characteristics, where its behavior is modeled as a partially observable Markov decision process (POMDP). We first construct compact representations of learned policies for POMDPs with unknown transition functions given a dataset of sequential actions and observations. Then, we filter parameterized policies of previously visited environments to generate policies to new, unseen environments. We demonstrate our approaches on both an actual AV and a high-fidelity simulator. Results indicate that our experience filter offers a fast, low-effort, and near-optimal solution to create policies for tasks or environments never seen before. Furthermore, the generated new policies outperform the policy learned using the entire data collected from past environments, suggesting that the correlation among different environments can be exploited and irrelevant ones can be filtered out.