 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Deep Generative Models for Belief State Planning
May 16, 2025Partially observable Markov decision processes (POMDPs) are used to model a wide range of applications, including robotics, autonomous vehicles, and subsurface problems. However, accurately representing the belief is difficult for POMDPs with high-dimensional states. In this paper, we propose a novel approach that uses conditional deep generative models (cDGMs) to represent the belief. Unlike traditional belief representations, cDGMs are well-suited for high-dimensional states and large numbers of observations, and they can generate an arbitrary number of samples from the posterior belief. We train the cDGMs on data produced by random rollout trajectories and show their effectiveness in solving a mineral exploration POMDP with a large and continuous state space. The cDGMs outperform particle filter baselines in both task-agnostic measures of belief accuracy as well as in planning performance.
Managing Geological Uncertainty in Critical Mineral Supply Chains: A POMDP Approach with Application to U.S. Lithium Resources
Feb 08, 2025



The world is entering an unprecedented period of critical mineral demand, driven by the global transition to renewable energy technologies and electric vehicles. This transition presents unique challenges in mineral resource development, particularly due to geological uncertainty-a key characteristic that traditional supply chain optimization approaches do not adequately address. To tackle this challenge, we propose a novel application of Partially Observable Markov Decision Processes (POMDPs) that optimizes critical mineral sourcing decisions while explicitly accounting for the dynamic nature of geological uncertainty. Through a case study of the U.S. lithium supply chain, we demonstrate that POMDP-based policies achieve superior outcomes compared to traditional approaches, especially when initial reserve estimates are imperfect. Our framework provides quantitative insights for balancing domestic resource development with international supply diversification, offering policymakers a systematic approach to strategic decision-making in critical mineral supply chains.
Intelligent prospector v2.0: exploration drill planning under epistemic model uncertainty
Oct 14, 2024



Optimal Bayesian decision making on what geoscientific data to acquire requires stating a prior model of uncertainty. Data acquisition is then optimized by reducing uncertainty on some property of interest maximally, and on average. In the context of exploration, very few, sometimes no data at all, is available prior to data acquisition planning. The prior model therefore needs to include human interpretations on the nature of spatial variability, or on analogue data deemed relevant for the area being explored. In mineral exploration, for example, humans may rely on conceptual models on the genesis of the mineralization to define multiple hypotheses, each representing a specific spatial variability of mineralization. More often than not, after the data is acquired, all of the stated hypotheses may be proven incorrect, i.e. falsified, hence prior hypotheses need to be revised, or additional hypotheses generated. Planning data acquisition under wrong geological priors is likely to be inefficient since the estimated uncertainty on the target property is incorrect, hence uncertainty may not be reduced at all. In this paper, we develop an intelligent agent based on partially observable Markov decision processes that plans optimally in the case of multiple geological or geoscientific hypotheses on the nature of spatial variability. Additionally, the artificial intelligence is equipped with a method that allows detecting, early on, whether the human stated hypotheses are incorrect, thereby saving considerable expense in data acquisition. Our approach is tested on a sediment-hosted copper deposit, and the algorithm presented has aided in the characterization of an ultra high-grade deposit in Zambia in 2023.
Diffusion-Based Failure Sampling for Cyber-Physical Systems
Jun 20, 2024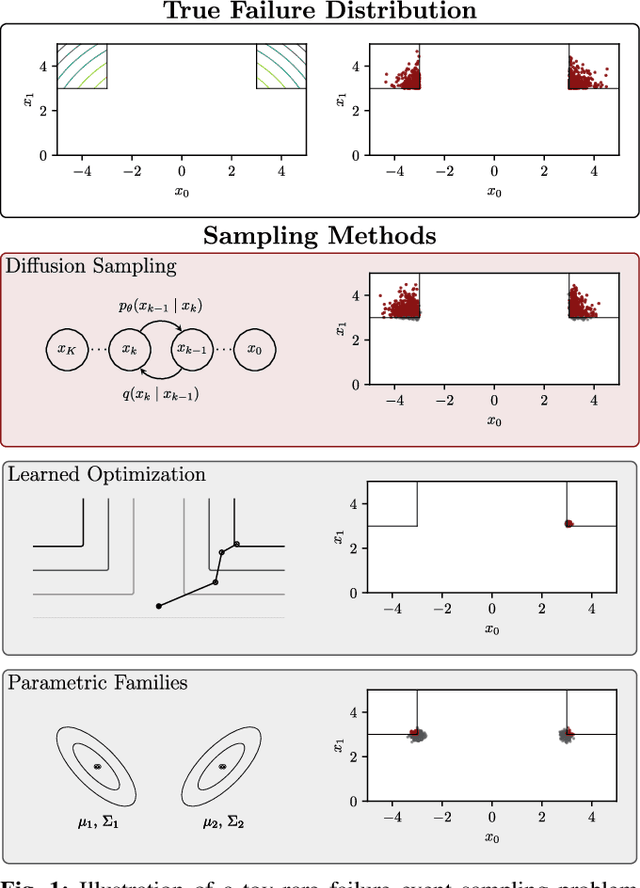
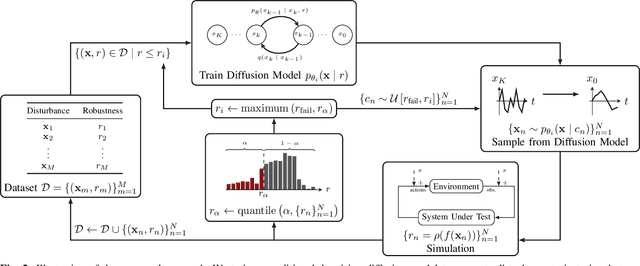
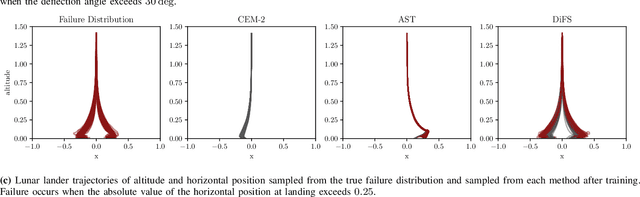
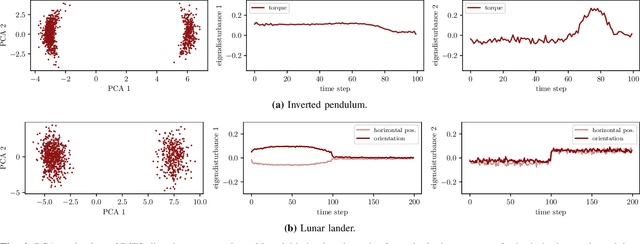
Validating safety-critical autonomous systems in high-dimensional domains such as robotics presents a significant challenge. Existing black-box approaches based on Markov chain Monte Carlo may require an enormous number of samples, while methods based on importance sampling often rely on simple parametric families that may struggle to represent the distribution over failures. We propose to sample the distribution over failures using a conditional denoising diffusion model, which has shown success in complex high-dimensional problems such as robotic task planning. We iteratively train a diffusion model to produce state trajectories closer to failure. We demonstrate the effectiveness of our approach on high-dimensional robotic validation tasks, improving sample efficiency and mode coverage compared to existing black-box techniques.
ConstrainedZero: Chance-Constrained POMDP Planning using Learned Probabilistic Failure Surrogates and Adaptive Safety Constraints
May 01, 2024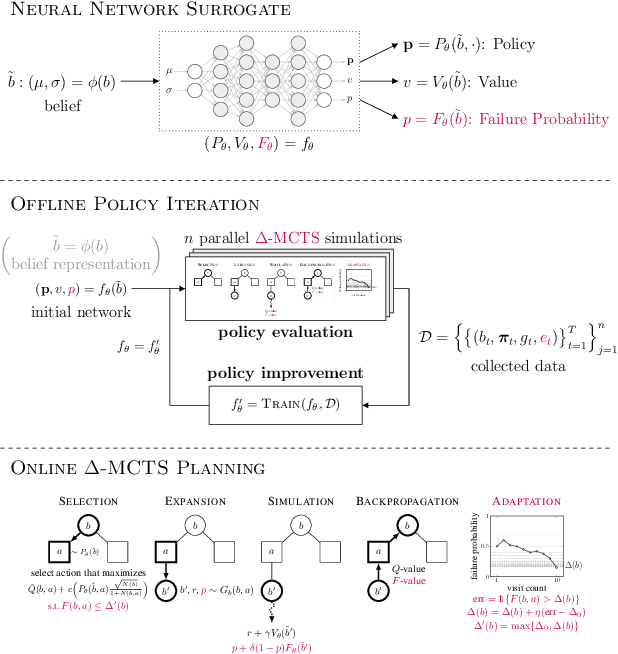
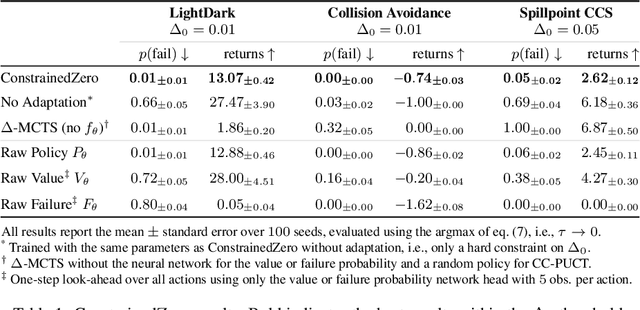
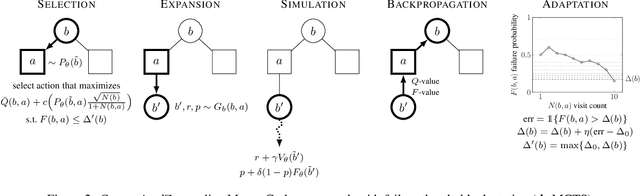

To plan safely in uncertain environments, agents must balance utility with safety constraints. Safe planning problems can be modeled as a chance-constrained partially observable Markov decision process (CC-POMDP) and solutions often use expensive rollouts or heuristics to estimate the optimal value and action-selection policy. This work introduces the ConstrainedZero policy iteration algorithm that solves CC-POMDPs in belief space by learning neural network approximations of the optimal value and policy with an additional network head that estimates the failure probability given a belief. This failure probability guides safe action selection during online Monte Carlo tree search (MCTS). To avoid overemphasizing search based on the failure estimates, we introduce $\Delta$-MCTS, which uses adaptive conformal inference to update the failure threshold during planning. The approach is tested on a safety-critical POMDP benchmark, an aircraft collision avoidance system, and the sustainability problem of safe CO$_2$ storage. Results show that by separating safety constraints from the objective we can achieve a target level of safety without optimizing the balance between rewards and costs.
Human vs. Machine: Language Models and Wargames
Mar 06, 2024



Wargames have a long history in the development of military strategy and the response of nations to threats or attacks. The advent of artificial intelligence (AI) promises better decision-making and increased military effectiveness. However, there is still debate about how AI systems, especially large language models (LLMs), behave as compared to humans. To this end, we use a wargame experiment with 107 national security expert human players designed to look at crisis escalation in a fictional US-China scenario and compare human players to LLM-simulated responses. We find considerable agreement in the LLM and human responses but also significant quantitative and qualitative differences between simulated and human players in the wargame, motivating caution to policymakers before handing over autonomy or following AI-based strategy recommendations.
Constrained Hierarchical Monte Carlo Belief-State Planning
Oct 30, 2023



Optimal plans in Constrained Partially Observable Markov Decision Processes (CPOMDPs) maximize reward objectives while satisfying hard cost constraints, generalizing safe planning under state and transition uncertainty. Unfortunately, online CPOMDP planning is extremely difficult in large or continuous problem domains. In many large robotic domains, hierarchical decomposition can simplify planning by using tools for low-level control given high-level action primitives (options). We introduce Constrained Options Belief Tree Search (COBeTS) to leverage this hierarchy and scale online search-based CPOMDP planning to large robotic problems. We show that if primitive option controllers are defined to satisfy assigned constraint budgets, then COBeTS will satisfy constraints anytime. Otherwise, COBeTS will guide the search towards a safe sequence of option primitives, and hierarchical monitoring can be used to achieve runtime safety. We demonstrate COBeTS in several safety-critical, constrained partially observable robotic domains, showing that it can plan successfully in continuous CPOMDPs while non-hierarchical baselines cannot.
Transcending the Attention Paradigm: Implicit Learning from Geospatial Social Media Data
Oct 09, 2023While transformers have pioneered attention-driven architectures as a cornerstone of research, their dependence on explicitly contextual information underscores limitations in their abilities to tacitly learn overarching textual themes. This study investigates social media data as a source of distributed patterns, challenging the heuristic paradigm of performance benchmarking. In stark contrast to networks that rely on capturing complex long-term dependencies, models of online data inherently lack structure and are forced to learn underlying patterns in the aggregate. To properly represent these abstract relationships, this research dissects empirical social media corpora into their elemental components and analyzes over two billion tweets across population-dense locations. Exploring the relationship between location and vernacular in Twitter data, we employ Bag-of-Words models specific to each city and evaluate their respective representation. This demonstrates that hidden insights can be uncovered without the crutch of advanced algorithms and demonstrates that even amidst noisy data, geographic location has a considerable influence on online communication. This evidence presents tangible insights regarding geospatial communication patterns and their implications in social science. It also challenges the notion that intricate models are prerequisites for pattern recognition in natural language, aligning with the evolving landscape that questions the embrace of absolute interpretability over abstract understanding. This study bridges the divide between sophisticated frameworks and intangible relationships, paving the way for systems that blend structured models with conjectural reasoning.
A Holistic Assessment of the Reliability of Machine Learning Systems
Jul 29, 2023As machine learning (ML) systems increasingly permeate high-stakes settings such as healthcare, transportation, military, and national security, concerns regarding their reliability have emerged. Despite notable progress, the performance of these systems can significantly diminish due to adversarial attacks or environmental changes, leading to overconfident predictions, failures to detect input faults, and an inability to generalize in unexpected scenarios. This paper proposes a holistic assessment methodology for the reliability of ML systems. Our framework evaluates five key properties: in-distribution accuracy, distribution-shift robustness, adversarial robustness, calibration, and out-of-distribution detection. A reliability score is also introduced and used to assess the overall system reliability. To provide insights into the performance of different algorithmic approaches, we identify and categorize state-of-the-art techniques, then evaluate a selection on real-world tasks using our proposed reliability metrics and reliability score. Our analysis of over 500 models reveals that designing for one metric does not necessarily constrain others but certain algorithmic techniques can improve reliability across multiple metrics simultaneously. This study contributes to a more comprehensive understanding of ML reliability and provides a roadmap for future research and development.
Reflections from the Workshop on AI-Assisted Decision Making for Conservation
Jul 17, 2023

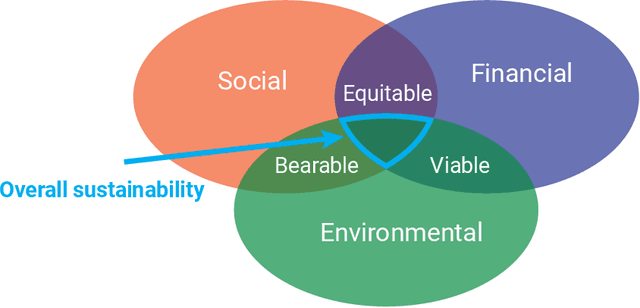
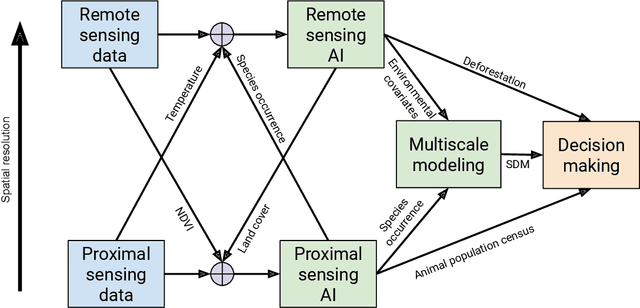
In this white paper, we synthesize key points made during presentations and discussions from the AI-Assisted Decision Making for Conservation workshop, hosted by the Center for Research on Computation and Society at Harvard University on October 20-21, 2022. We identify key open research questions in resource allocation, planning, and interventions for biodiversity conservation, highlighting conservation challenges that not only require AI solutions, but also require novel methodological advances. In addition to providing a summary of the workshop talks and discussions, we hope this document serves as a call-to-action to orient the expansion of algorithmic decision-making approaches to prioritize real-world conservation challenges, through collaborative efforts of ecologists, conservation decision-makers, and AI researchers.