 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAMOS-OCTA: Vessel-Aware Multi-Axis Orthogonal Supervision for Inpainting Motion-Corrupted OCT Angiography Volumes
Feb 01, 2026Handheld Optical Coherence Tomography Angiography (OCTA) enables noninvasive retinal imaging in uncooperative or pediatric subjects, but is highly susceptible to motion artifacts that severely degrade volumetric image quality. Sudden motion during 3D acquisition can lead to unsampled retinal regions across entire B-scans (cross-sectional slices), resulting in blank bands in en face projections. We propose VAMOS-OCTA, a deep learning framework for inpainting motion-corrupted B-scans using vessel-aware multi-axis supervision. We employ a 2.5D U-Net architecture that takes a stack of neighboring B-scans as input to reconstruct a corrupted center B-scan, guided by a novel Vessel-Aware Multi-Axis Orthogonal Supervision (VAMOS) loss. This loss combines vessel-weighted intensity reconstruction with axial and lateral projection consistency, encouraging vascular continuity in native B-scans and across orthogonal planes. Unlike prior work that focuses primarily on restoring the en face MIP, VAMOS-OCTA jointly enhances both cross-sectional B-scan sharpness and volumetric projection accuracy, even under severe motion corruptions. We trained our model on both synthetic and real-world corrupted volumes and evaluated its performance using both perceptual quality and pixel-wise accuracy metrics. VAMOS-OCTA consistently outperforms prior methods, producing reconstructions with sharp capillaries, restored vessel continuity, and clean en face projections. These results demonstrate that multi-axis supervision offers a powerful constraint for restoring motion-degraded 3D OCTA data. Our source code is available at https://github.com/MedICL-VU/VAMOS-OCTA.
Transcending the Attention Paradigm: Implicit Learning from Geospatial Social Media Data
Oct 09, 2023
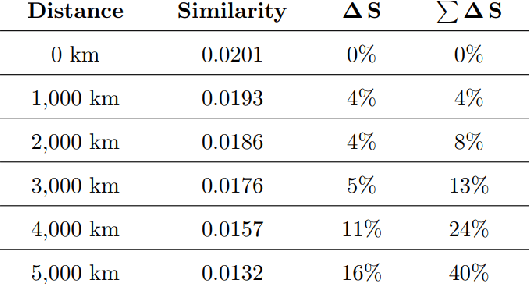
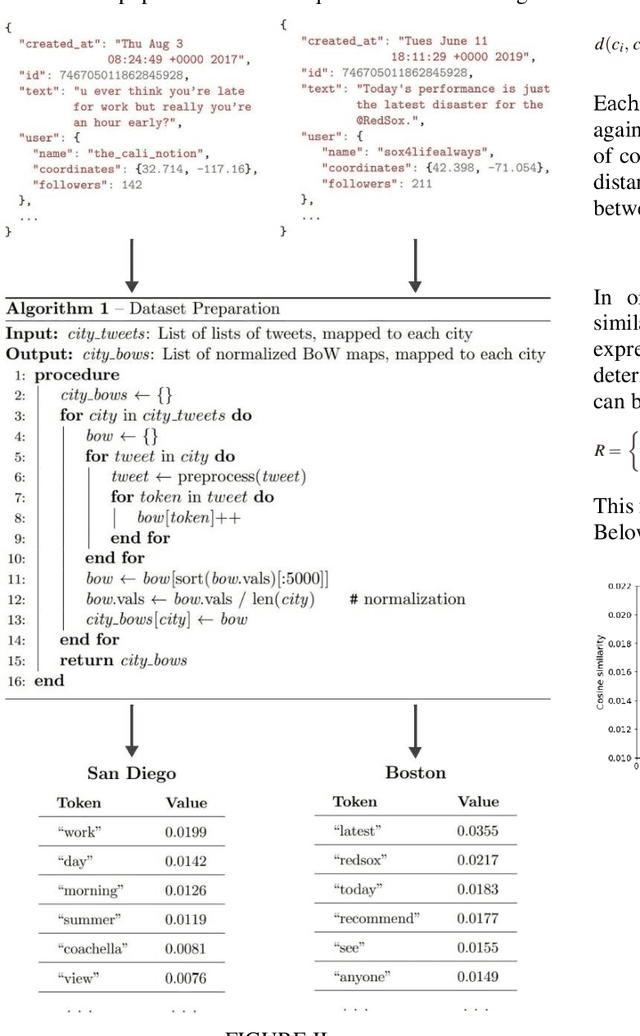
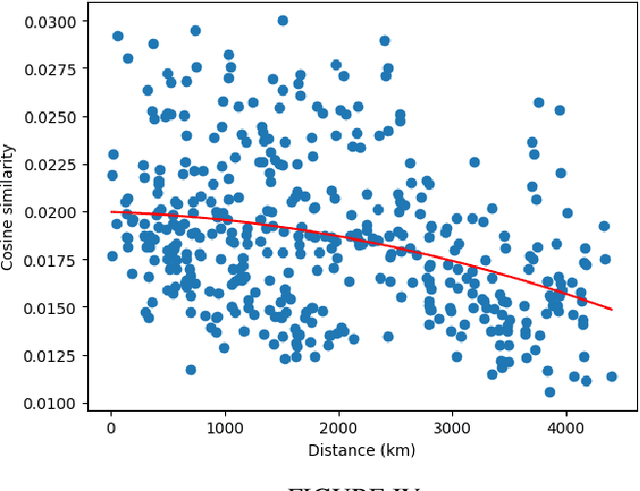
While transformers have pioneered attention-driven architectures as a cornerstone of research, their dependence on explicitly contextual information underscores limitations in their abilities to tacitly learn overarching textual themes. This study investigates social media data as a source of distributed patterns, challenging the heuristic paradigm of performance benchmarking. In stark contrast to networks that rely on capturing complex long-term dependencies, models of online data inherently lack structure and are forced to learn underlying patterns in the aggregate. To properly represent these abstract relationships, this research dissects empirical social media corpora into their elemental components and analyzes over two billion tweets across population-dense locations. Exploring the relationship between location and vernacular in Twitter data, we employ Bag-of-Words models specific to each city and evaluate their respective representation. This demonstrates that hidden insights can be uncovered without the crutch of advanced algorithms and demonstrates that even amidst noisy data, geographic location has a considerable influence on online communication. This evidence presents tangible insights regarding geospatial communication patterns and their implications in social science. It also challenges the notion that intricate models are prerequisites for pattern recognition in natural language, aligning with the evolving landscape that questions the embrace of absolute interpretability over abstract understanding. This study bridges the divide between sophisticated frameworks and intangible relationships, paving the way for systems that blend structured models with conjectural reasoning.
Eliminating Mole Size in Melanoma Classification
Dec 09, 2022
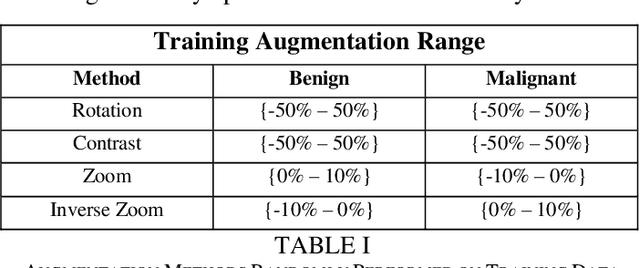


While skin cancer classification has been a popular and valuable deep learning application for years, there has been little consideration of the context in which testing images are taken. Traditional melanoma classifiers rely on the assumption that their testing environments are analogous to the structured images on which they are trained. This paper combats this notion, arguing that mole size, a vital attribute in professional dermatology, is a red herring in automated melanoma detection. Although malignant melanomas are consistently larger than benign melanomas, this distinction proves unreliable and harmful when images cannot be contextually scaled. This implementation builds a custom model that eliminates size as a training feature to prevent overfitting to incorrect parameters. Additionally, random rotation and contrast augmentations are performed to simulate the real-world use of melanoma detection applications. Several custom models with varying forms of data augmentation are implemented to demonstrate the most significant features of the generalization abilities of mole classifiers. These implementations show that user unpredictability is crucial when utilizing such applications. The caution required when manually modifying data is acknowledged, as data loss and biased conclusions are necessary considerations in this process. Additionally, mole size inconsistency and its significance are discussed in both the dermatology and deep learning communities.