 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEliminating Mole Size in Melanoma Classification
Paper and Code
Dec 09, 2022
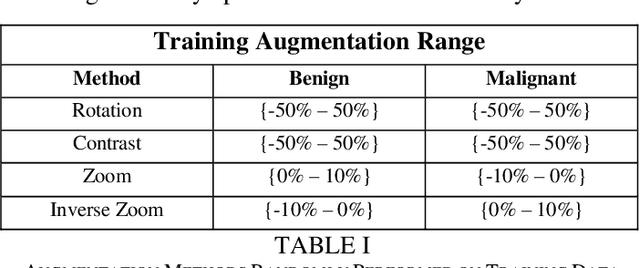


While skin cancer classification has been a popular and valuable deep learning application for years, there has been little consideration of the context in which testing images are taken. Traditional melanoma classifiers rely on the assumption that their testing environments are analogous to the structured images on which they are trained. This paper combats this notion, arguing that mole size, a vital attribute in professional dermatology, is a red herring in automated melanoma detection. Although malignant melanomas are consistently larger than benign melanomas, this distinction proves unreliable and harmful when images cannot be contextually scaled. This implementation builds a custom model that eliminates size as a training feature to prevent overfitting to incorrect parameters. Additionally, random rotation and contrast augmentations are performed to simulate the real-world use of melanoma detection applications. Several custom models with varying forms of data augmentation are implemented to demonstrate the most significant features of the generalization abilities of mole classifiers. These implementations show that user unpredictability is crucial when utilizing such applications. The caution required when manually modifying data is acknowledged, as data loss and biased conclusions are necessary considerations in this process. Additionally, mole size inconsistency and its significance are discussed in both the dermatology and deep learning communities.