 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranscending the Attention Paradigm: Implicit Learning from Geospatial Social Media Data
Paper and Code
Oct 09, 2023
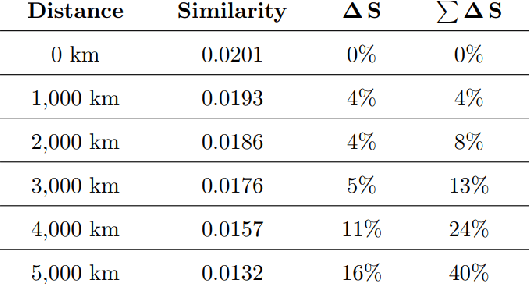
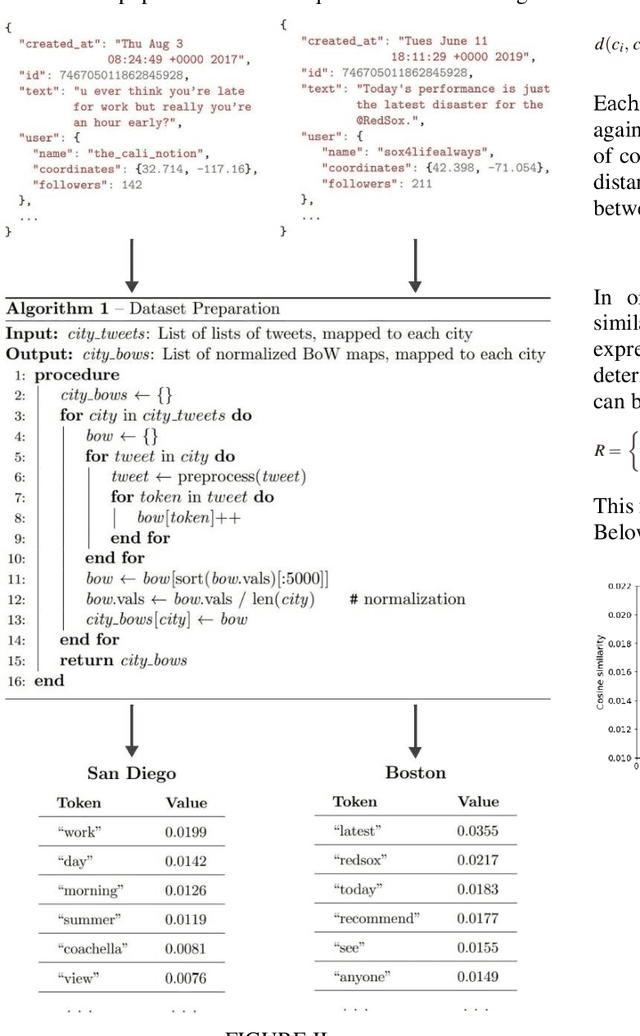
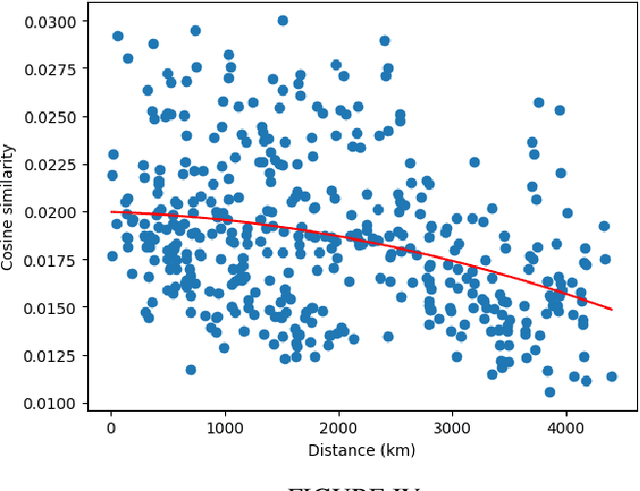
While transformers have pioneered attention-driven architectures as a cornerstone of research, their dependence on explicitly contextual information underscores limitations in their abilities to tacitly learn overarching textual themes. This study investigates social media data as a source of distributed patterns, challenging the heuristic paradigm of performance benchmarking. In stark contrast to networks that rely on capturing complex long-term dependencies, models of online data inherently lack structure and are forced to learn underlying patterns in the aggregate. To properly represent these abstract relationships, this research dissects empirical social media corpora into their elemental components and analyzes over two billion tweets across population-dense locations. Exploring the relationship between location and vernacular in Twitter data, we employ Bag-of-Words models specific to each city and evaluate their respective representation. This demonstrates that hidden insights can be uncovered without the crutch of advanced algorithms and demonstrates that even amidst noisy data, geographic location has a considerable influence on online communication. This evidence presents tangible insights regarding geospatial communication patterns and their implications in social science. It also challenges the notion that intricate models are prerequisites for pattern recognition in natural language, aligning with the evolving landscape that questions the embrace of absolute interpretability over abstract understanding. This study bridges the divide between sophisticated frameworks and intangible relationships, paving the way for systems that blend structured models with conjectural reasoning.