 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Actively on the Fly: Relevance-Guided Online Meta-Learning with Latent Concepts for Geospatial Discovery
Feb 19, 2026In many real-world settings, such as environmental monitoring, disaster response, or public health, with costly and difficult data collection and dynamic environments, strategically sampling from unobserved regions is essential for efficiently uncovering hidden targets under tight resource constraints. Yet, sparse and biased geospatial ground truth limits the applicability of existing learning-based methods, such as reinforcement learning. To address this, we propose a unified geospatial discovery framework that integrates active learning, online meta-learning, and concept-guided reasoning. Our approach introduces two key innovations built on a shared notion of *concept relevance*, which captures how domain-specific factors influence target presence: a *concept-weighted uncertainty sampling strategy*, where uncertainty is modulated by learned relevance based on readily-available domain-specific concepts (e.g., land cover, source proximity); and a *relevance-aware meta-batch formation strategy* that promotes semantic diversity during online-meta updates, improving generalization in dynamic environments. Our experiments include testing on a real-world dataset of cancer-causing PFAS (Per- and polyfluoroalkyl substances) contamination, showcasing our method's reliability at uncovering targets with limited data and a varying environment.
Evaluation Framework for AI Systems in "the Wild"
Apr 23, 2025Generative AI (GenAI) models have become vital across industries, yet current evaluation methods have not adapted to their widespread use. Traditional evaluations often rely on benchmarks and fixed datasets, frequently failing to reflect real-world performance, which creates a gap between lab-tested outcomes and practical applications. This white paper proposes a comprehensive framework for how we should evaluate real-world GenAI systems, emphasizing diverse, evolving inputs and holistic, dynamic, and ongoing assessment approaches. The paper offers guidance for practitioners on how to design evaluation methods that accurately reflect real-time capabilities, and provides policymakers with recommendations for crafting GenAI policies focused on societal impacts, rather than fixed performance numbers or parameter sizes. We advocate for holistic frameworks that integrate performance, fairness, and ethics and the use of continuous, outcome-oriented methods that combine human and automated assessments while also being transparent to foster trust among stakeholders. Implementing these strategies ensures GenAI models are not only technically proficient but also ethically responsible and impactful.
Find Rhinos without Finding Rhinos: Active Learning with Multimodal Imagery of South African Rhino Habitats
Sep 26, 2024


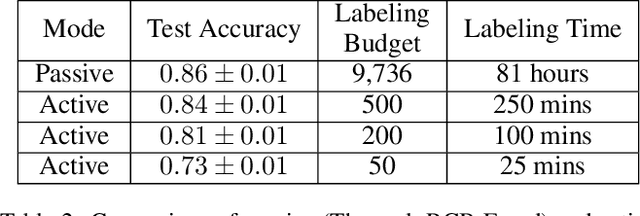
Much of Earth's charismatic megafauna is endangered by human activities, particularly the rhino, which is at risk of extinction due to the poaching crisis in Africa. Monitoring rhinos' movement is crucial to their protection but has unfortunately proven difficult because rhinos are elusive. Therefore, instead of tracking rhinos, we propose the novel approach of mapping communal defecation sites, called middens, which give information about rhinos' spatial behavior valuable to anti-poaching, management, and reintroduction efforts. This paper provides the first-ever mapping of rhino midden locations by building classifiers to detect them using remotely sensed thermal, RGB, and LiDAR imagery in passive and active learning settings. As existing active learning methods perform poorly due to the extreme class imbalance in our dataset, we design MultimodAL, an active learning system employing a ranking technique and multimodality to achieve competitive performance with passive learning models with 94% fewer labels. Our methods could therefore save over 76 hours in labeling time when used on a similarly-sized dataset. Unexpectedly, our midden map reveals that rhino middens are not randomly distributed throughout the landscape; rather, they are clustered. Consequently, rangers should be targeted at areas with high midden densities to strengthen anti-poaching efforts, in line with UN Target 15.7.
* 9 pages, 9 figures, IJCAI 2023 Special Track on AI for Good
Are They the Same Picture? Adapting Concept Bottleneck Models for Human-AI Collaboration in Image Retrieval
Jul 12, 2024



Image retrieval plays a pivotal role in applications from wildlife conservation to healthcare, for finding individual animals or relevant images to aid diagnosis. Although deep learning techniques for image retrieval have advanced significantly, their imperfect real-world performance often necessitates including human expertise. Human-in-the-loop approaches typically rely on humans completing the task independently and then combining their opinions with an AI model in various ways, as these models offer very little interpretability or \textit{correctability}. To allow humans to intervene in the AI model instead, thereby saving human time and effort, we adapt the Concept Bottleneck Model (CBM) and propose \texttt{CHAIR}. \texttt{CHAIR} (a) enables humans to correct intermediate concepts, which helps \textit{improve} embeddings generated, and (b) allows for flexible levels of intervention that accommodate varying levels of human expertise for better retrieval. To show the efficacy of \texttt{CHAIR}, we demonstrate that our method performs better than similar models on image retrieval metrics without any external intervention. Furthermore, we also showcase how human intervention helps further improve retrieval performance, thereby achieving human-AI complementarity.
Impact of Large Language Model Assistance on Patients Reading Clinical Notes: A Mixed-Methods Study
Jan 17, 2024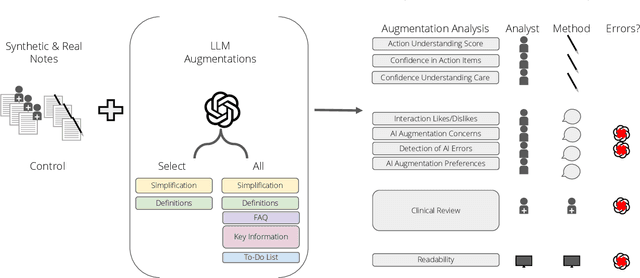
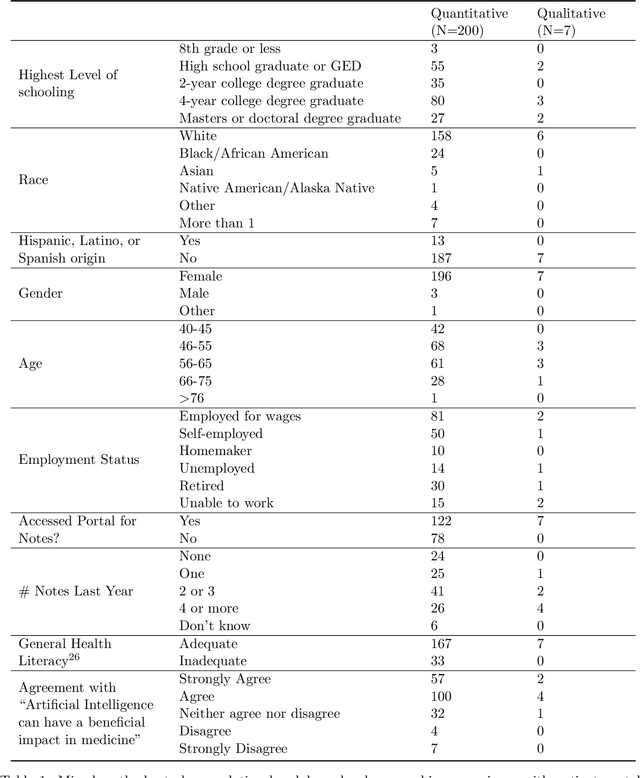
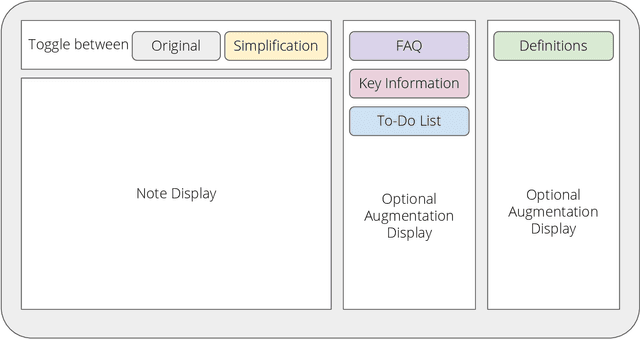
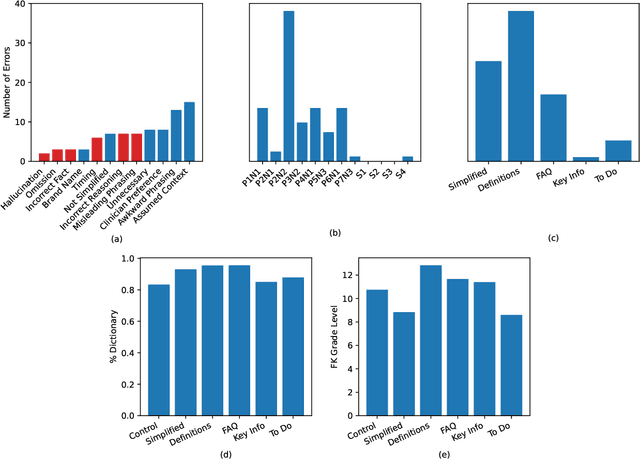
Patients derive numerous benefits from reading their clinical notes, including an increased sense of control over their health and improved understanding of their care plan. However, complex medical concepts and jargon within clinical notes hinder patient comprehension and may lead to anxiety. We developed a patient-facing tool to make clinical notes more readable, leveraging large language models (LLMs) to simplify, extract information from, and add context to notes. We prompt engineered GPT-4 to perform these augmentation tasks on real clinical notes donated by breast cancer survivors and synthetic notes generated by a clinician, a total of 12 notes with 3868 words. In June 2023, 200 female-identifying US-based participants were randomly assigned three clinical notes with varying levels of augmentations using our tool. Participants answered questions about each note, evaluating their understanding of follow-up actions and self-reported confidence. We found that augmentations were associated with a significant increase in action understanding score (0.63 $\pm$ 0.04 for select augmentations, compared to 0.54 $\pm$ 0.02 for the control) with p=0.002. In-depth interviews of self-identifying breast cancer patients (N=7) were also conducted via video conferencing. Augmentations, especially definitions, elicited positive responses among the seven participants, with some concerns about relying on LLMs. Augmentations were evaluated for errors by clinicians, and we found misleading errors occur, with errors more common in real donated notes than synthetic notes, illustrating the importance of carefully written clinical notes. Augmentations improve some but not all readability metrics. This work demonstrates the potential of LLMs to improve patients' experience with clinical notes at a lower burden to clinicians. However, having a human in the loop is important to correct potential model errors.
Reflections from the Workshop on AI-Assisted Decision Making for Conservation
Jul 17, 2023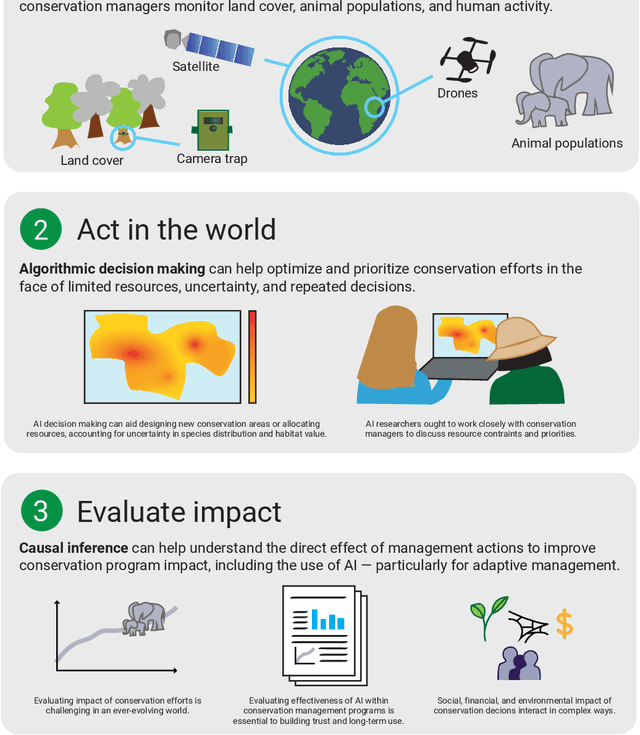

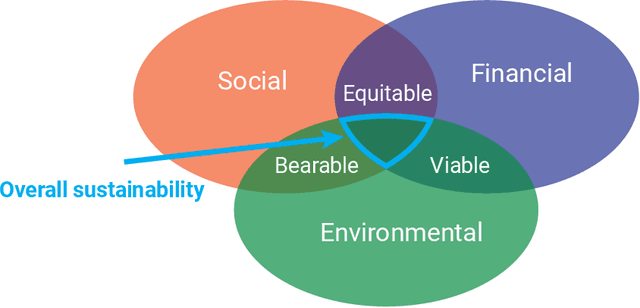
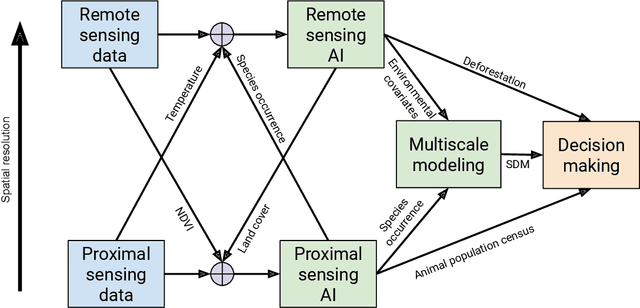
In this white paper, we synthesize key points made during presentations and discussions from the AI-Assisted Decision Making for Conservation workshop, hosted by the Center for Research on Computation and Society at Harvard University on October 20-21, 2022. We identify key open research questions in resource allocation, planning, and interventions for biodiversity conservation, highlighting conservation challenges that not only require AI solutions, but also require novel methodological advances. In addition to providing a summary of the workshop talks and discussions, we hope this document serves as a call-to-action to orient the expansion of algorithmic decision-making approaches to prioritize real-world conservation challenges, through collaborative efforts of ecologists, conservation decision-makers, and AI researchers.