 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre They the Same Picture? Adapting Concept Bottleneck Models for Human-AI Collaboration in Image Retrieval
Jul 12, 2024



Image retrieval plays a pivotal role in applications from wildlife conservation to healthcare, for finding individual animals or relevant images to aid diagnosis. Although deep learning techniques for image retrieval have advanced significantly, their imperfect real-world performance often necessitates including human expertise. Human-in-the-loop approaches typically rely on humans completing the task independently and then combining their opinions with an AI model in various ways, as these models offer very little interpretability or \textit{correctability}. To allow humans to intervene in the AI model instead, thereby saving human time and effort, we adapt the Concept Bottleneck Model (CBM) and propose \texttt{CHAIR}. \texttt{CHAIR} (a) enables humans to correct intermediate concepts, which helps \textit{improve} embeddings generated, and (b) allows for flexible levels of intervention that accommodate varying levels of human expertise for better retrieval. To show the efficacy of \texttt{CHAIR}, we demonstrate that our method performs better than similar models on image retrieval metrics without any external intervention. Furthermore, we also showcase how human intervention helps further improve retrieval performance, thereby achieving human-AI complementarity.
Bridging the Gap: Dynamic Learning Strategies for Improving Multilingual Performance in LLMs
May 28, 2024Large language models (LLMs) are at the forefront of transforming numerous domains globally. However, their inclusivity and effectiveness remain limited for non-Latin scripts and low-resource languages. This paper tackles the imperative challenge of enhancing the multilingual performance of LLMs without extensive training or fine-tuning. Through systematic investigation and evaluation of diverse languages using popular question-answering (QA) datasets, we present novel techniques that unlock the true potential of LLMs in a polyglot landscape. Our approach encompasses three key strategies that yield significant improvements in multilingual proficiency. First, by meticulously optimizing prompts tailored for polyglot LLMs, we unlock their latent capabilities, resulting in substantial performance boosts across languages. Second, we introduce a new hybrid approach that synergizes LLM Retrieval Augmented Generation (RAG) with multilingual embeddings and achieves improved multilingual task performance. Finally, we introduce a novel learning approach that dynamically selects the optimal prompt strategy, LLM model, and embedding model per query at run-time. This dynamic adaptation maximizes the efficacy of LLMs across languages, outperforming best static and random strategies. Additionally, our approach adapts configurations in both offline and online settings, and can seamlessly adapt to new languages and datasets, leading to substantial advancements in multilingual understanding and generation across diverse languages.
Breaking Language Barriers with a LEAP: Learning Strategies for Polyglot LLMs
May 28, 2023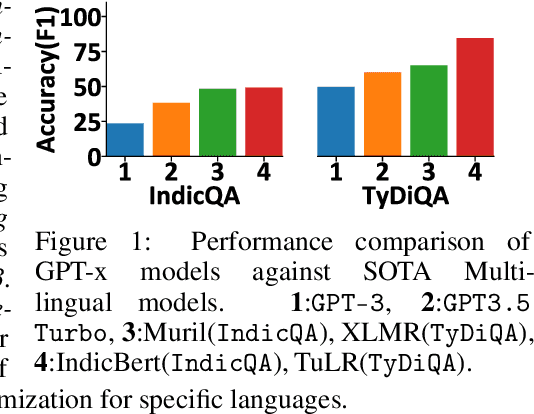

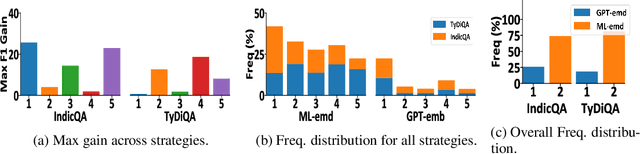
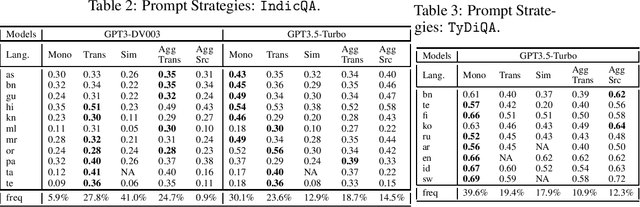
Large language models (LLMs) are at the forefront of transforming numerous domains globally. However, their inclusivity and effectiveness remain limited for non-Latin scripts and low-resource languages. This paper tackles the imperative challenge of enhancing the multilingual performance of LLMs, specifically focusing on Generative models. Through systematic investigation and evaluation of diverse languages using popular question-answering (QA) datasets, we present novel techniques that unlock the true potential of LLMs in a polyglot landscape. Our approach encompasses three key strategies that yield remarkable improvements in multilingual proficiency. First, by meticulously optimizing prompts tailored for polyglot LLMs, we unlock their latent capabilities, resulting in substantial performance boosts across languages. Second, we introduce a new hybrid approach that synergizes GPT generation with multilingual embeddings and achieves significant multilingual performance improvement on critical tasks like QA and retrieval. Finally, to further propel the performance of polyglot LLMs, we introduce a novel learning algorithm that dynamically selects the optimal prompt strategy, LLM model, and embeddings per query. This dynamic adaptation maximizes the efficacy of LLMs across languages, outperforming best static and random strategies. Our results show substantial advancements in multilingual understanding and generation across a diverse range of languages.