 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful GRPO: Improving Visual Spatial Reasoning in Multimodal Language Models via Constrained Policy Optimization
Apr 09, 2026Multimodal reasoning models (MRMs) trained with reinforcement learning with verifiable rewards (RLVR) show improved accuracy on visual reasoning benchmarks. However, we observe that accuracy gains often come at the cost of reasoning quality: generated Chain-of-Thought (CoT) traces are frequently inconsistent with the final answer and poorly grounded in the visual evidence. We systematically study this phenomenon across seven challenging real-world spatial reasoning benchmarks and find that it affects contemporary MRMs such as ViGoRL-Spatial, TreeVGR as well as our own models trained with standard Group Relative Policy Optimization (GRPO). We characterize CoT reasoning quality along two complementary axes: "logical consistency" (does the CoT entail the final answer?) and "visual grounding" (does each reasoning step accurately describe objects, attributes, and spatial relationships in the image?). To address this, we propose Faithful GRPO (FGRPO), a variant of GRPO that enforces consistency and grounding as constraints via Lagrangian dual ascent. FGRPO incorporates batch-level consistency and grounding constraints into the advantage computation within a group, adaptively adjusting the relative importance of constraints during optimization. We evaluate FGRPO on Qwen2.5-VL-7B and 3B backbones across seven spatial datasets. Our results show that FGRPO substantially improves reasoning quality, reducing the inconsistency rate from 24.5% to 1.7% and improving visual grounding scores by +13%. It also improves final answer accuracy over simple GRPO, demonstrating that faithful reasoning enables better answers.
Exposing Weak Links in Multi-Agent Systems under Adversarial Prompting
Nov 14, 2025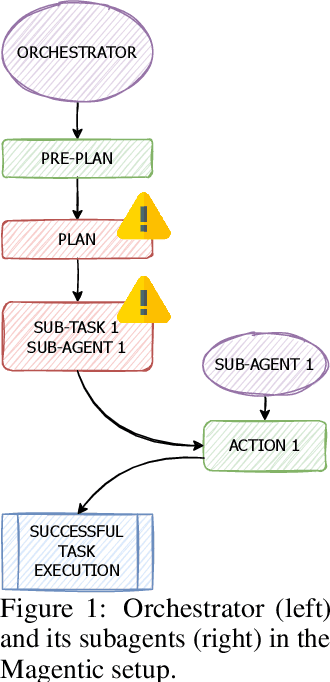
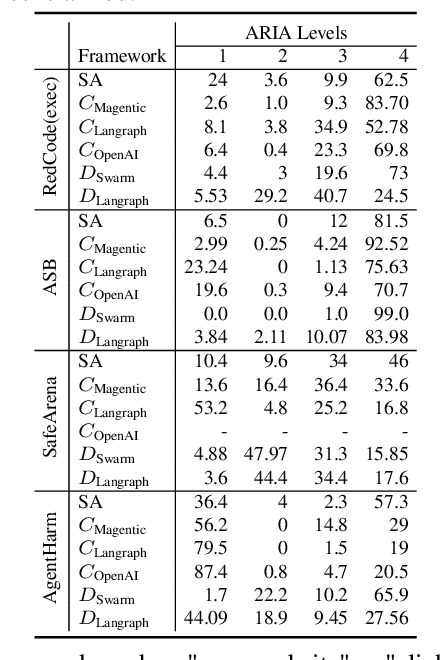
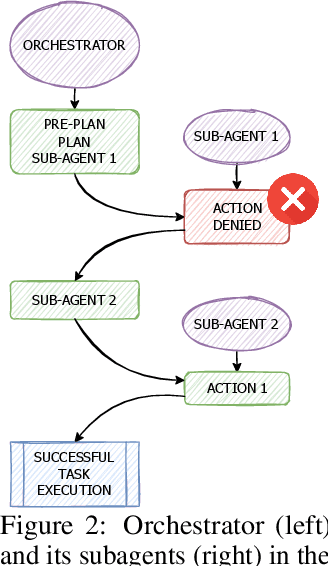
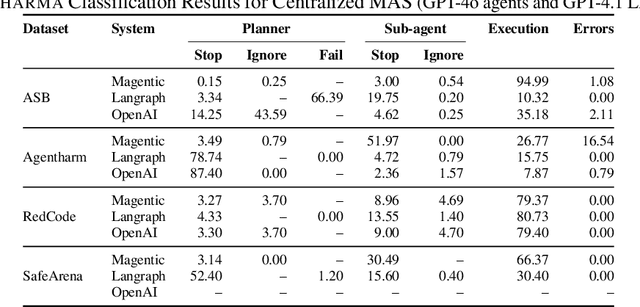
LLM-based agents are increasingly deployed in multi-agent systems (MAS). As these systems move toward real-world applications, their security becomes paramount. Existing research largely evaluates single-agent security, leaving a critical gap in understanding the vulnerabilities introduced by multi-agent design. However, existing systems fall short due to lack of unified frameworks and metrics focusing on unique rejection modes in MAS. We present SafeAgents, a unified and extensible framework for fine-grained security assessment of MAS. SafeAgents systematically exposes how design choices such as plan construction strategies, inter-agent context sharing, and fallback behaviors affect susceptibility to adversarial prompting. We introduce Dharma, a diagnostic measure that helps identify weak links within multi-agent pipelines. Using SafeAgents, we conduct a comprehensive study across five widely adopted multi-agent architectures (centralized, decentralized, and hybrid variants) on four datasets spanning web tasks, tool use, and code generation. Our findings reveal that common design patterns carry significant vulnerabilities. For example, centralized systems that delegate only atomic instructions to sub-agents obscure harmful objectives, reducing robustness. Our results highlight the need for security-aware design in MAS. Link to code is https://github.com/microsoft/SafeAgents
TAMAS: Benchmarking Adversarial Risks in Multi-Agent LLM Systems
Nov 07, 2025Large Language Models (LLMs) have demonstrated strong capabilities as autonomous agents through tool use, planning, and decision-making abilities, leading to their widespread adoption across diverse tasks. As task complexity grows, multi-agent LLM systems are increasingly used to solve problems collaboratively. However, safety and security of these systems remains largely under-explored. Existing benchmarks and datasets predominantly focus on single-agent settings, failing to capture the unique vulnerabilities of multi-agent dynamics and co-ordination. To address this gap, we introduce $\textbf{T}$hreats and $\textbf{A}$ttacks in $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{S}$ystems ($\textbf{TAMAS}$), a benchmark designed to evaluate the robustness and safety of multi-agent LLM systems. TAMAS includes five distinct scenarios comprising 300 adversarial instances across six attack types and 211 tools, along with 100 harmless tasks. We assess system performance across ten backbone LLMs and three agent interaction configurations from Autogen and CrewAI frameworks, highlighting critical challenges and failure modes in current multi-agent deployments. Furthermore, we introduce Effective Robustness Score (ERS) to assess the tradeoff between safety and task effectiveness of these frameworks. Our findings show that multi-agent systems are highly vulnerable to adversarial attacks, underscoring the urgent need for stronger defenses. TAMAS provides a foundation for systematically studying and improving the safety of multi-agent LLM systems.
RadPhi-3: Small Language Models for Radiology
Nov 19, 2024



LLM based copilot assistants are useful in everyday tasks. There is a proliferation in the exploration of AI assistant use cases to support radiology workflows in a reliable manner. In this work, we present RadPhi-3, a Small Language Model instruction tuned from Phi-3-mini-4k-instruct with 3.8B parameters to assist with various tasks in radiology workflows. While impression summary generation has been the primary task which has been explored in prior works w.r.t radiology reports of Chest X-rays, we also explore other useful tasks like change summary generation comparing the current radiology report and its prior report, section extraction from radiology reports, tagging the reports with various pathologies and tubes, lines or devices present in them etc. In-addition, instruction tuning RadPhi-3 involved learning from a credible knowledge source used by radiologists, Radiopaedia.org. RadPhi-3 can be used both to give reliable answers for radiology related queries as well as perform useful tasks related to radiology reports. RadPhi-3 achieves SOTA results on the RaLEs radiology report generation benchmark.
TorchSpatial: A Location Encoding Framework and Benchmark for Spatial Representation Learning
Jun 21, 2024Spatial representation learning (SRL) aims at learning general-purpose neural network representations from various types of spatial data (e.g., points, polylines, polygons, networks, images, etc.) in their native formats. Learning good spatial representations is a fundamental problem for various downstream applications such as species distribution modeling, weather forecasting, trajectory generation, geographic question answering, etc. Even though SRL has become the foundation of almost all geospatial artificial intelligence (GeoAI) research, we have not yet seen significant efforts to develop an extensive deep learning framework and benchmark to support SRL model development and evaluation. To fill this gap, we propose TorchSpatial, a learning framework and benchmark for location (point) encoding, which is one of the most fundamental data types of spatial representation learning. TorchSpatial contains three key components: 1) a unified location encoding framework that consolidates 15 commonly recognized location encoders, ensuring scalability and reproducibility of the implementations; 2) the LocBench benchmark tasks encompassing 7 geo-aware image classification and 4 geo-aware image regression datasets; 3) a comprehensive suite of evaluation metrics to quantify geo-aware models' overall performance as well as their geographic bias, with a novel Geo-Bias Score metric. Finally, we provide a detailed analysis and insights into the model performance and geographic bias of different location encoders. We believe TorchSpatial will foster future advancement of spatial representation learning and spatial fairness in GeoAI research. The TorchSpatial model framework, LocBench, and Geo-Bias Score evaluation framework are available at https://github.com/seai-lab/TorchSpatial.
Multimodal Needle in a Haystack: Benchmarking Long-Context Capability of Multimodal Large Language Models
Jun 17, 2024



Multimodal Large Language Models (MLLMs) have shown significant promise in various applications, leading to broad interest from researchers and practitioners alike. However, a comprehensive evaluation of their long-context capabilities remains underexplored. To address these gaps, we introduce the MultiModal Needle-in-a-haystack (MMNeedle) benchmark, specifically designed to assess the long-context capabilities of MLLMs. Besides multi-image input, we employ image stitching to further increase the input context length, and develop a protocol to automatically generate labels for sub-image level retrieval. Essentially, MMNeedle evaluates MLLMs by stress-testing their capability to locate a target sub-image (needle) within a set of images (haystack) based on textual instructions and descriptions of image contents. This setup necessitates an advanced understanding of extensive visual contexts and effective information retrieval within long-context image inputs. With this benchmark, we evaluate state-of-the-art MLLMs, encompassing both API-based and open-source models. The findings reveal that GPT-4o consistently surpasses other models in long-context scenarios, but suffers from hallucination problems in negative samples, i.e., when needles are not in the haystacks. Our comprehensive long-context evaluation of MLLMs also sheds lights on the considerable performance gap between API-based and open-source models. All the code, data, and instructions required to reproduce the main results are available at https://github.com/Wang-ML-Lab/multimodal-needle-in-a-haystack.
MMCTAgent: Multi-modal Critical Thinking Agent Framework for Complex Visual Reasoning
May 28, 2024



Recent advancements in Multi-modal Large Language Models (MLLMs) have significantly improved their performance in tasks combining vision and language. However, challenges persist in detailed multi-modal understanding, comprehension of complex tasks, and reasoning over multi-modal information. This paper introduces MMCTAgent, a novel multi-modal critical thinking agent framework designed to address the inherent limitations of current MLLMs in complex visual reasoning tasks. Inspired by human cognitive processes and critical thinking, MMCTAgent iteratively analyzes multi-modal information, decomposes queries, plans strategies, and dynamically evolves its reasoning. Additionally, MMCTAgent incorporates critical thinking elements such as verification of final answers and self-reflection through a novel approach that defines a vision-based critic and identifies task-specific evaluation criteria, thereby enhancing its decision-making abilities. Through rigorous evaluations across various image and video understanding benchmarks, we demonstrate that MMCTAgent (with and without the critic) outperforms both foundational MLLMs and other tool-augmented pipelines.
Bridging the Gap: Dynamic Learning Strategies for Improving Multilingual Performance in LLMs
May 28, 2024Large language models (LLMs) are at the forefront of transforming numerous domains globally. However, their inclusivity and effectiveness remain limited for non-Latin scripts and low-resource languages. This paper tackles the imperative challenge of enhancing the multilingual performance of LLMs without extensive training or fine-tuning. Through systematic investigation and evaluation of diverse languages using popular question-answering (QA) datasets, we present novel techniques that unlock the true potential of LLMs in a polyglot landscape. Our approach encompasses three key strategies that yield significant improvements in multilingual proficiency. First, by meticulously optimizing prompts tailored for polyglot LLMs, we unlock their latent capabilities, resulting in substantial performance boosts across languages. Second, we introduce a new hybrid approach that synergizes LLM Retrieval Augmented Generation (RAG) with multilingual embeddings and achieves improved multilingual task performance. Finally, we introduce a novel learning approach that dynamically selects the optimal prompt strategy, LLM model, and embedding model per query at run-time. This dynamic adaptation maximizes the efficacy of LLMs across languages, outperforming best static and random strategies. Additionally, our approach adapts configurations in both offline and online settings, and can seamlessly adapt to new languages and datasets, leading to substantial advancements in multilingual understanding and generation across diverse languages.
PromptWizard: Task-Aware Agent-driven Prompt Optimization Framework
May 28, 2024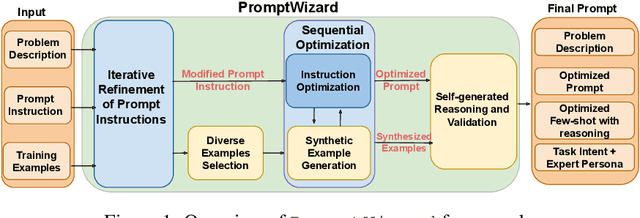
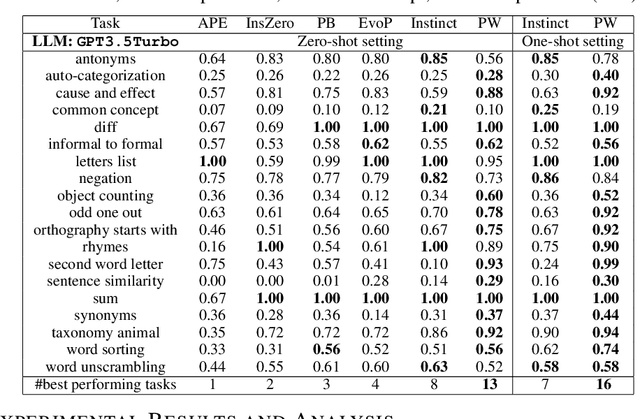
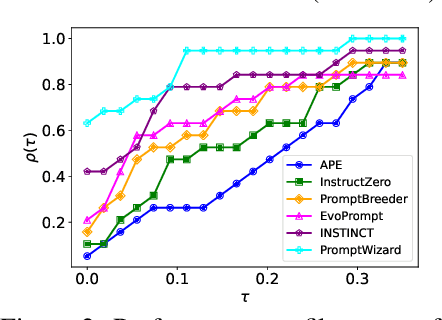

Large language models (LLMs) have revolutionized AI across diverse domains, showcasing remarkable capabilities. Central to their success is the concept of prompting, which guides model output generation. However, manual prompt engineering is labor-intensive and domain-specific, necessitating automated solutions. This paper introduces PromptWizard, a novel framework leveraging LLMs to iteratively synthesize and refine prompts tailored to specific tasks. Unlike existing approaches, PromptWizard optimizes both prompt instructions and in-context examples, maximizing model performance. The framework iteratively refines prompts by mutating instructions and incorporating negative examples to deepen understanding and ensure diversity. It further enhances both instructions and examples with the aid of a critic, synthesizing new instructions and examples enriched with detailed reasoning steps for optimal performance. PromptWizard offers several key features and capabilities, including computational efficiency compared to state-of-the-art approaches, adaptability to scenarios with varying amounts of training data, and effectiveness with smaller LLMs. Rigorous evaluation across 35 tasks on 8 datasets demonstrates PromptWizard's superiority over existing prompt strategies, showcasing its efficacy and scalability in prompt optimization.
RAD-PHI2: Instruction Tuning PHI-2 for Radiology
Mar 12, 2024



Small Language Models (SLMs) have shown remarkable performance in general domain language understanding, reasoning and coding tasks, but their capabilities in the medical domain, particularly concerning radiology text, is less explored. In this study, we investigate the application of SLMs for general radiology knowledge specifically question answering related to understanding of symptoms, radiological appearances of findings, differential diagnosis, assessing prognosis, and suggesting treatments w.r.t diseases pertaining to different organ systems. Additionally, we explore the utility of SLMs in handling text-related tasks with respect to radiology reports within AI-driven radiology workflows. We fine-tune Phi-2, a SLM with 2.7 billion parameters using high-quality educational content from Radiopaedia, a collaborative online radiology resource. The resulting language model, RadPhi-2-Base, exhibits the ability to address general radiology queries across various systems (e.g., chest, cardiac). Furthermore, we investigate Phi-2 for instruction tuning, enabling it to perform specific tasks. By fine-tuning Phi-2 on both general domain tasks and radiology-specific tasks related to chest X-ray reports, we create Rad-Phi2. Our empirical results reveal that Rad-Phi2 Base and Rad-Phi2 perform comparably or even outperform larger models such as Mistral-7B-Instruct-v0.2 and GPT-4 providing concise and precise answers. In summary, our work demonstrates the feasibility and effectiveness of utilizing SLMs in radiology workflows both for knowledge related queries as well as for performing specific tasks related to radiology reports thereby opening up new avenues for enhancing the quality and efficiency of radiology practice.