 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRestoring Exploration after Post-Training: Latent Exploration Decoding for Large Reasoning Models
Feb 02, 2026Large Reasoning Models (LRMs) have recently achieved strong mathematical and code reasoning performance through Reinforcement Learning (RL) post-training. However, we show that modern reasoning post-training induces an unintended exploration collapse: temperature-based sampling no longer increases pass@$n$ accuracy. Empirically, the final-layer posterior of post-trained LRMs exhibit sharply reduced entropy, while the entropy of intermediate layers remains relatively high. Motivated by this entropy asymmetry, we propose Latent Exploration Decoding (LED), a depth-conditioned decoding strategy. LED aggregates intermediate posteriors via cumulative sum and selects depth configurations with maximal entropy as exploration candidates. Without additional training or parameters, LED consistently improves pass@1 and pass@16 accuracy by 0.61 and 1.03 percentage points across multiple reasoning benchmarks and models. Project page: https://GitHub.com/Xiaomi-Research/LED.
DPWriter: Reinforcement Learning with Diverse Planning Branching for Creative Writing
Jan 14, 2026Reinforcement learning (RL)-based enhancement of large language models (LLMs) often leads to reduced output diversity, undermining their utility in open-ended tasks like creative writing. Current methods lack explicit mechanisms for guiding diverse exploration and instead prioritize optimization efficiency and performance over diversity. This paper proposes an RL framework structured around a semi-structured long Chain-of-Thought (CoT), in which the generation process is decomposed into explicitly planned intermediate steps. We introduce a Diverse Planning Branching method that strategically introduces divergence at the planning phase based on diversity variation, alongside a group-aware diversity reward to encourage distinct trajectories. Experimental results on creative writing benchmarks demonstrate that our approach significantly improves output diversity without compromising generation quality, consistently outperforming existing baselines.
DiffVLA: Vision-Language Guided Diffusion Planning for Autonomous Driving
May 26, 2025Research interest in end-to-end autonomous driving has surged owing to its fully differentiable design integrating modular tasks, i.e. perception, prediction and planing, which enables optimization in pursuit of the ultimate goal. Despite the great potential of the end-to-end paradigm, existing methods suffer from several aspects including expensive BEV (bird's eye view) computation, action diversity, and sub-optimal decision in complex real-world scenarios. To address these challenges, we propose a novel hybrid sparse-dense diffusion policy, empowered by a Vision-Language Model (VLM), called Diff-VLA. We explore the sparse diffusion representation for efficient multi-modal driving behavior. Moreover, we rethink the effectiveness of VLM driving decision and improve the trajectory generation guidance through deep interaction across agent, map instances and VLM output. Our method shows superior performance in Autonomous Grand Challenge 2025 which contains challenging real and reactive synthetic scenarios. Our methods achieves 45.0 PDMS.
Evaluating Text Creativity across Diverse Domains: A Dataset and Large Language Model Evaluator
May 25, 2025Creativity evaluation remains a challenging frontier for large language models (LLMs). Current evaluations heavily rely on inefficient and costly human judgments, hindering progress in enhancing machine creativity. While automated methods exist, ranging from psychological testing to heuristic- or prompting-based approaches, they often lack generalizability or alignment with human judgment. To address these issues, in this paper, we propose a novel pairwise-comparison framework for assessing textual creativity, leveraging shared contextual instructions to improve evaluation consistency. We introduce CreataSet, a large-scale dataset with 100K+ human-level and 1M+ synthetic creative instruction-response pairs spanning diverse open-domain tasks. Through training on CreataSet, we develop an LLM-based evaluator named CrEval. CrEval demonstrates remarkable superiority over existing methods in alignment with human judgments. Experimental results underscore the indispensable significance of integrating both human-generated and synthetic data in training highly robust evaluators, and showcase the practical utility of CrEval in boosting the creativity of LLMs. We will release all data, code, and models publicly soon to support further research.
Feature Interaction Fusion Self-Distillation Network For CTR Prediction
Nov 13, 2024


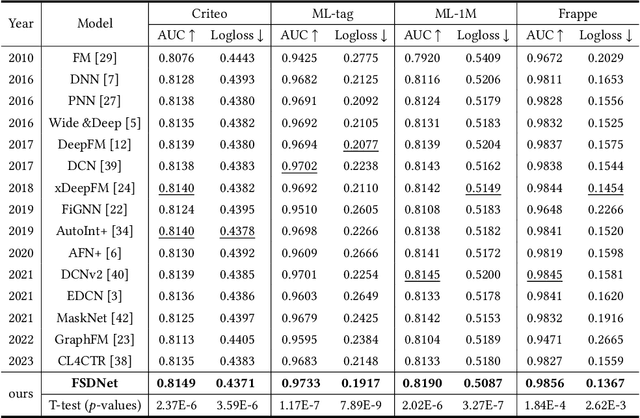
Click-Through Rate (CTR) prediction plays a vital role in recommender systems, online advertising, and search engines. Most of the current approaches model feature interactions through stacked or parallel structures, with some employing knowledge distillation for model compression. However, we observe some limitations with these approaches: (1) In parallel structure models, the explicit and implicit components are executed independently and simultaneously, which leads to insufficient information sharing within the feature set. (2) The introduction of knowledge distillation technology brings about the problems of complex teacher-student framework design and low knowledge transfer efficiency. (3) The dataset and the process of constructing high-order feature interactions contain significant noise, which limits the model's effectiveness. To address these limitations, we propose FSDNet, a CTR prediction framework incorporating a plug-and-play fusion self-distillation module. Specifically, FSDNet forms connections between explicit and implicit feature interactions at each layer, enhancing the sharing of information between different features. The deepest fusion layer is then used as the teacher model, utilizing self-distillation to guide the training of shallow layers. Empirical evaluation across four benchmark datasets validates the framework's efficacy and generalization capabilities. The code is available on https://anonymous.4open.science/r/FSDNet.
BSharedRAG: Backbone Shared Retrieval-Augmented Generation for the E-commerce Domain
Sep 30, 2024



Retrieval Augmented Generation (RAG) system is important in domains such as e-commerce, which has many long-tail entities and frequently updated information. Most existing works adopt separate modules for retrieval and generation, which may be suboptimal since the retrieval task and the generation task cannot benefit from each other to improve performance. We propose a novel Backbone Shared RAG framework (BSharedRAG). It first uses a domain-specific corpus to continually pre-train a base model as a domain-specific backbone model and then trains two plug-and-play Low-Rank Adaptation (LoRA) modules based on the shared backbone to minimize retrieval and generation losses respectively. Experimental results indicate that our proposed BSharedRAG outperforms baseline models by 5% and 13% in Hit@3 upon two datasets in retrieval evaluation and by 23% in terms of BLEU-3 in generation evaluation. Our codes, models, and dataset are available at https://bsharedrag.github.io.
See or Guess: Counterfactually Regularized Image Captioning
Aug 29, 2024



Image captioning, which generates natural language descriptions of the visual information in an image, is a crucial task in vision-language research. Previous models have typically addressed this task by aligning the generative capabilities of machines with human intelligence through statistical fitting of existing datasets. While effective for normal images, they may struggle to accurately describe those where certain parts of the image are obscured or edited, unlike humans who excel in such cases. These weaknesses they exhibit, including hallucinations and limited interpretability, often hinder performance in scenarios with shifted association patterns. In this paper, we present a generic image captioning framework that employs causal inference to make existing models more capable of interventional tasks, and counterfactually explainable. Our approach includes two variants leveraging either total effect or natural direct effect. Integrating them into the training process enables models to handle counterfactual scenarios, increasing their generalizability. Extensive experiments on various datasets show that our method effectively reduces hallucinations and improves the model's faithfulness to images, demonstrating high portability across both small-scale and large-scale image-to-text models. The code is available at https://github.com/Aman-4-Real/See-or-Guess.
YuLan: An Open-source Large Language Model
Jun 28, 2024



Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
TorchSpatial: A Location Encoding Framework and Benchmark for Spatial Representation Learning
Jun 21, 2024Spatial representation learning (SRL) aims at learning general-purpose neural network representations from various types of spatial data (e.g., points, polylines, polygons, networks, images, etc.) in their native formats. Learning good spatial representations is a fundamental problem for various downstream applications such as species distribution modeling, weather forecasting, trajectory generation, geographic question answering, etc. Even though SRL has become the foundation of almost all geospatial artificial intelligence (GeoAI) research, we have not yet seen significant efforts to develop an extensive deep learning framework and benchmark to support SRL model development and evaluation. To fill this gap, we propose TorchSpatial, a learning framework and benchmark for location (point) encoding, which is one of the most fundamental data types of spatial representation learning. TorchSpatial contains three key components: 1) a unified location encoding framework that consolidates 15 commonly recognized location encoders, ensuring scalability and reproducibility of the implementations; 2) the LocBench benchmark tasks encompassing 7 geo-aware image classification and 4 geo-aware image regression datasets; 3) a comprehensive suite of evaluation metrics to quantify geo-aware models' overall performance as well as their geographic bias, with a novel Geo-Bias Score metric. Finally, we provide a detailed analysis and insights into the model performance and geographic bias of different location encoders. We believe TorchSpatial will foster future advancement of spatial representation learning and spatial fairness in GeoAI research. The TorchSpatial model framework, LocBench, and Geo-Bias Score evaluation framework are available at https://github.com/seai-lab/TorchSpatial.
Retaining Key Information under High Compression Ratios: Query-Guided Compressor for LLMs
Jun 04, 2024



The growing popularity of Large Language Models has sparked interest in context compression for Large Language Models (LLMs). However, the performance of previous methods degrades dramatically as compression ratios increase, sometimes even falling to the closed-book level. This decline can be attributed to the loss of key information during the compression process. Our preliminary study supports this hypothesis, emphasizing the significance of retaining key information to maintain model performance under high compression ratios. As a result, we introduce Query-Guided Compressor (QGC), which leverages queries to guide the context compression process, effectively preserving key information within the compressed context. Additionally, we employ a dynamic compression strategy. We validate the effectiveness of our proposed QGC on the Question Answering task, including NaturalQuestions, TriviaQA, and HotpotQA datasets. Experimental results show that QGC can consistently perform well even at high compression ratios, which also offers significant benefits in terms of inference cost and throughput.