 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGist: Towards General and Hardware-aligned Sequence-level Long Context Compression
Sep 19, 2025Large language models are increasingly capable of handling long-context inputs, but the memory overhead of key-value (KV) cache remains a major bottleneck for general-purpose deployment. While various compression strategies have been explored, sequence-level compression, which drops the full KV caches for certain tokens, is particularly challenging as it can lead to the loss of important contextual information. To address this, we introduce UniGist, a sequence-level long-context compression framework that efficiently preserves context information by replacing raw tokens with special compression tokens (gists) in a fine-grained manner. We adopt a chunk-free training strategy and design an efficient kernel with a gist shift trick, enabling optimized GPU training. Our scheme also supports flexible inference by allowing the actual removal of compressed tokens, resulting in real-time memory savings. Experiments across multiple long-context tasks demonstrate that UniGist significantly improves compression quality, with especially strong performance in detail-recalling tasks and long-range dependency modeling.
UniConv: Unifying Retrieval and Response Generation for Large Language Models in Conversations
Jul 09, 2025
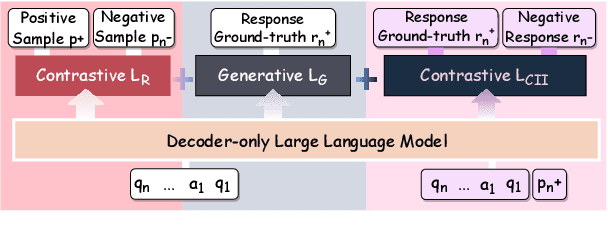
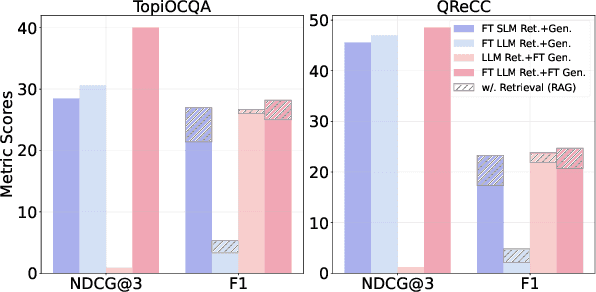
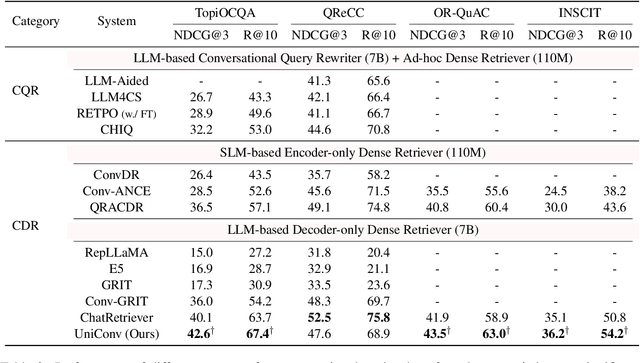
The rapid advancement of conversational search systems revolutionizes how information is accessed by enabling the multi-turn interaction between the user and the system. Existing conversational search systems are usually built with two different models. This separation restricts the system from leveraging the intrinsic knowledge of the models simultaneously, which cannot ensure the effectiveness of retrieval benefiting the generation. The existing studies for developing unified models cannot fully address the aspects of understanding conversational context, managing retrieval independently, and generating responses. In this paper, we explore how to unify dense retrieval and response generation for large language models in conversation. We conduct joint fine-tuning with different objectives and design two mechanisms to reduce the inconsistency risks while mitigating data discrepancy. The evaluations on five conversational search datasets demonstrate that our unified model can mutually improve both tasks and outperform the existing baselines.
A Silver Bullet or a Compromise for Full Attention? A Comprehensive Study of Gist Token-based Context Compression
Dec 23, 2024



In this work, we provide a thorough investigation of gist-based context compression methods to improve long-context processing in large language models. We focus on two key questions: (1) How well can these methods replace full attention models? and (2) What potential failure patterns arise due to compression? Through extensive experiments, we show that while gist-based compression can achieve near-lossless performance on tasks like retrieval-augmented generation and long-document QA, it faces challenges in tasks like synthetic recall. Furthermore, we identify three key failure patterns: lost by the boundary, lost if surprise, and lost along the way. To mitigate these issues, we propose two effective strategies: fine-grained autoencoding, which enhances the reconstruction of original token information, and segment-wise token importance estimation, which adjusts optimization based on token dependencies. Our work provides valuable insights into the understanding of gist token-based context compression and offers practical strategies for improving compression capabilities.
CORAL: Benchmarking Multi-turn Conversational Retrieval-Augmentation Generation
Oct 30, 2024



Retrieval-Augmented Generation (RAG) has become a powerful paradigm for enhancing large language models (LLMs) through external knowledge retrieval. Despite its widespread attention, existing academic research predominantly focuses on single-turn RAG, leaving a significant gap in addressing the complexities of multi-turn conversations found in real-world applications. To bridge this gap, we introduce CORAL, a large-scale benchmark designed to assess RAG systems in realistic multi-turn conversational settings. CORAL includes diverse information-seeking conversations automatically derived from Wikipedia and tackles key challenges such as open-domain coverage, knowledge intensity, free-form responses, and topic shifts. It supports three core tasks of conversational RAG: passage retrieval, response generation, and citation labeling. We propose a unified framework to standardize various conversational RAG methods and conduct a comprehensive evaluation of these methods on CORAL, demonstrating substantial opportunities for improving existing approaches.
A Survey of Conversational Search
Oct 21, 2024



As a cornerstone of modern information access, search engines have become indispensable in everyday life. With the rapid advancements in AI and natural language processing (NLP) technologies, particularly large language models (LLMs), search engines have evolved to support more intuitive and intelligent interactions between users and systems. Conversational search, an emerging paradigm for next-generation search engines, leverages natural language dialogue to facilitate complex and precise information retrieval, thus attracting significant attention. Unlike traditional keyword-based search engines, conversational search systems enhance user experience by supporting intricate queries, maintaining context over multi-turn interactions, and providing robust information integration and processing capabilities. Key components such as query reformulation, search clarification, conversational retrieval, and response generation work in unison to enable these sophisticated interactions. In this survey, we explore the recent advancements and potential future directions in conversational search, examining the critical modules that constitute a conversational search system. We highlight the integration of LLMs in enhancing these systems and discuss the challenges and opportunities that lie ahead in this dynamic field. Additionally, we provide insights into real-world applications and robust evaluations of current conversational search systems, aiming to guide future research and development in conversational search.
MemoRAG: Moving towards Next-Gen RAG Via Memory-Inspired Knowledge Discovery
Sep 10, 2024


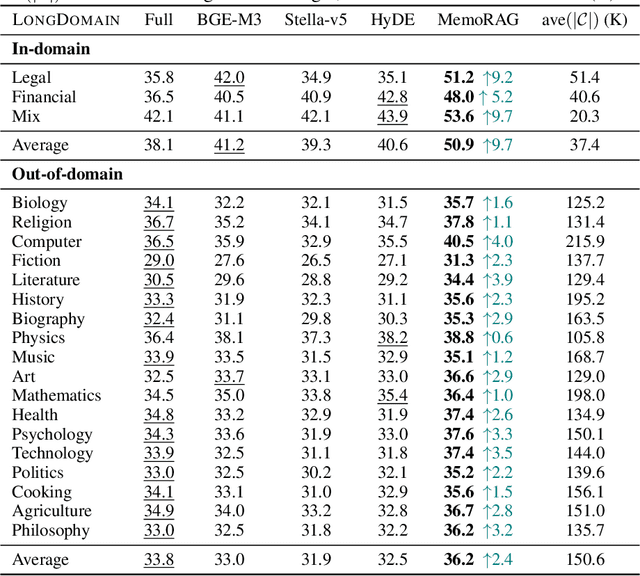
Retrieval-Augmented Generation (RAG) leverages retrieval tools to access external databases, thereby enhancing the generation quality of large language models (LLMs) through optimized context. However, the existing retrieval methods are constrained inherently, as they can only perform relevance matching between explicitly stated queries and well-formed knowledge, but unable to handle tasks involving ambiguous information needs or unstructured knowledge. Consequently, existing RAG systems are primarily effective for straightforward question-answering tasks. In this work, we propose MemoRAG, a novel retrieval-augmented generation paradigm empowered by long-term memory. MemoRAG adopts a dual-system architecture. On the one hand, it employs a light but long-range LLM to form the global memory of database. Once a task is presented, it generates draft answers, cluing the retrieval tools to locate useful information within the database. On the other hand, it leverages an expensive but expressive LLM, which generates the ultimate answer based on the retrieved information. Building on this general framework, we further optimize MemoRAG's performance by enhancing its cluing mechanism and memorization capacity. In our experiment, MemoRAG achieves superior performance across a variety of evaluation tasks, including both complex ones where conventional RAG fails and straightforward ones where RAG is commonly applied.
Aligning Query Representation with Rewritten Query and Relevance Judgments in Conversational Search
Jul 29, 2024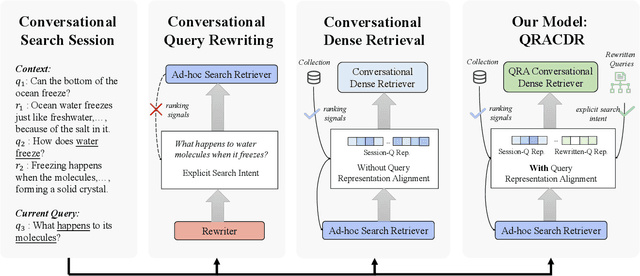
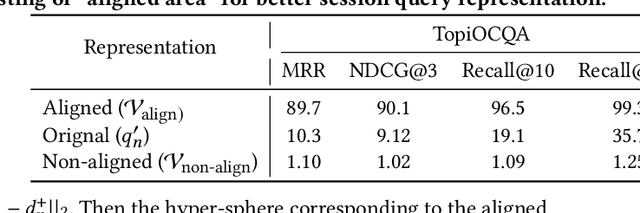
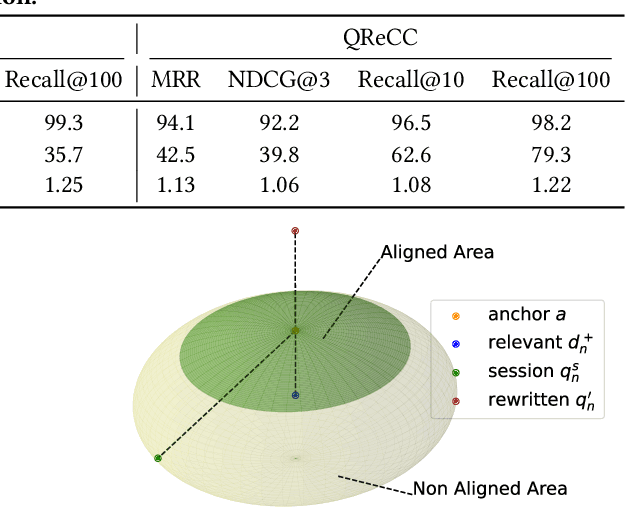

Conversational search supports multi-turn user-system interactions to solve complex information needs. Different from the traditional single-turn ad-hoc search, conversational search encounters a more challenging problem of context-dependent query understanding with the lengthy and long-tail conversational history context. While conversational query rewriting methods leverage explicit rewritten queries to train a rewriting model to transform the context-dependent query into a stand-stone search query, this is usually done without considering the quality of search results. Conversational dense retrieval methods use fine-tuning to improve a pre-trained ad-hoc query encoder, but they are limited by the conversational search data available for training. In this paper, we leverage both rewritten queries and relevance judgments in the conversational search data to train a better query representation model. The key idea is to align the query representation with those of rewritten queries and relevant documents. The proposed model -- Query Representation Alignment Conversational Dense Retriever, QRACDR, is tested on eight datasets, including various settings in conversational search and ad-hoc search. The results demonstrate the strong performance of QRACDR compared with state-of-the-art methods, and confirm the effectiveness of representation alignment.
Enabling Discriminative Reasoning in LLMs for Legal Judgment Prediction
Jul 03, 2024



Legal judgment prediction is essential for enhancing judicial efficiency. In this work, we identify that existing large language models (LLMs) underperform in this domain due to challenges in understanding case complexities and distinguishing between similar charges. To adapt LLMs for effective legal judgment prediction, we introduce the Ask-Discriminate-Predict (ADAPT) reasoning framework inspired by human judicial reasoning. ADAPT involves decomposing case facts, discriminating among potential charges, and predicting the final judgment. We further enhance LLMs through fine-tuning with multi-task synthetic trajectories to improve legal judgment prediction accuracy and efficiency under our ADAPT framework. Extensive experiments conducted on two widely-used datasets demonstrate the superior performance of our framework in legal judgment prediction, particularly when dealing with complex and confusing charges.
Enabling Discriminative Reasoning in Large Language Models for Legal Judgment Prediction
Jul 02, 2024Legal judgment prediction is essential for enhancing judicial efficiency. In this work, we identify that existing large language models (LLMs) underperform in this domain due to challenges in understanding case complexities and distinguishing between similar charges. To adapt LLMs for effective legal judgment prediction, we introduce the Ask-Discriminate-Predict (ADAPT) reasoning framework inspired by human judicial reasoning. ADAPT involves decomposing case facts, discriminating among potential charges, and predicting the final judgment. We further enhance LLMs through fine-tuning with multi-task synthetic trajectories to improve legal judgment prediction accuracy and efficiency under our ADAPT framework. Extensive experiments conducted on two widely-used datasets demonstrate the superior performance of our framework in legal judgment prediction, particularly when dealing with complex and confusing charges.
Learning Interpretable Legal Case Retrieval via Knowledge-Guided Case Reformulation
Jun 28, 2024



Legal case retrieval for sourcing similar cases is critical in upholding judicial fairness. Different from general web search, legal case retrieval involves processing lengthy, complex, and highly specialized legal documents. Existing methods in this domain often overlook the incorporation of legal expert knowledge, which is crucial for accurately understanding and modeling legal cases, leading to unsatisfactory retrieval performance. This paper introduces KELLER, a legal knowledge-guided case reformulation approach based on large language models (LLMs) for effective and interpretable legal case retrieval. By incorporating professional legal knowledge about crimes and law articles, we enable large language models to accurately reformulate the original legal case into concise sub-facts of crimes, which contain the essential information of the case. Extensive experiments on two legal case retrieval benchmarks demonstrate superior retrieval performance and robustness on complex legal case queries of KELLER over existing methods.