 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeriGraph: Towards Verifiable Data-Analytic Agents
Jun 15, 2026LLM-based agents have demonstrated strong capabilities in data-intensive analytical tasks, yet their outputs are rarely verifiable: a reliance on linear text trajectories makes their reasoning difficult to audit. In particular, deterministic computations over raw data and semantic deductions over natural-language claims are often entangled in an unstructured stream, leaving numerical conclusions hard to reproduce and qualitative judgments hard to inspect. To address this, we propose VeriGraph, a traceable neuro-symbolic reasoning framework that enables agents to construct an explicit heterogeneous evidence directed acyclic graph (DAG) during execution. VeriGraph introduces three evidence-expansion primitives, namely computational, grounding, and derivational expansion, to connect raw data, interpreter variables, computed results, and natural-language claims in a unified graph. Under this formulation, structural traceability is reduced to graph reachability from raw data sources to terminal claims, while semantic support is measured by claim-level evidence evaluation. To improve graph construction, we further design a graph-based policy optimization strategy with a composite reward that jointly supervises answer correctness, computational integrity, and derivational coherence. Experiments on four benchmarks show that VeriGraph-8B achieves the highest overall score among all baselines. More importantly, VeriGraph produces auditable evidence graphs with substantially stronger claim grounding, achieving a 87.61\% Grounding Rate under our claim-level evidence support evaluation. These results suggest that explicit evidence-graph construction is a promising path toward verifiable data-analytic agents. Our code is available at https://github.com/ignorejjj/VeriGraph.
Toward Generalist Autonomous Research via Hypothesis-Tree Refinement
Jun 10, 2026Scientific progress depends on a repeated loop of exploration, experimentation, and abstraction. Researchers test candidate directions, interpret the evidence, and carry the resulting lessons into later attempts. We study how an AI agent can run this loop autonomously over long horizons. We introduce Arbor, a general framework for autonomous research that combines a long-lived coordinator, short-lived executors, and Hypothesis Tree Refinement (HTR), a persistent tree that links hypotheses, artifacts, evidence, and distilled insights across time. The coordinator manages global research strategy over the tree, while executors implement and test individual hypotheses in isolated worktrees. As results return, Arbor updates the tree, propagates reusable lessons, refines the search frontier, and admits verified improvements. This design turns autonomous research from a sequence of local attempts into a cumulative process in which strategy, execution, and evidence are carried across time. We evaluate Arbor under Autonomous Optimization (AO), an operational setting where an agent improves an initial research artifact through iterative experimentation without step-level human supervision. Across six real research tasks in model training, harness engineering, and data synthesis, Arbor achieves the best held-out result on all six tasks, attaining more than 2.5x the average relative held-out gain of Codex and Claude Code under the same task interface and resource budget. On MLE-Bench Lite, Arbor reaches 86.36% Any Medal with GPT-5.5, the strongest result in our comparison.
Towards Verifiable Multimodal Deep Research: A Multi-Agent Harness for Interleaved Report Generation
May 28, 2026Large Language Models (LLMs) have advanced autonomous agents from deep search, which retrieves concise factual answers, to deep research, which synthesizes scattered evidence into long-form reports. However, verifiable multimodal deep research remains challenging due to open-ended synthesis without deterministic ground truth and the need to interleave textual arguments with visual evidence. We propose \textsc{Ptah}, a multi-agent harness for interleaved report generation. \textsc{Ptah} orchestrates the lifecycle from user query to rendered web report through planning, research, and writing stages, where specialized agents construct visual-aware plans, collect claim-grounded evidence, maintain source-aligned images in a \textit{Visual Working Memory}, and compose reports through declarative multimodal tool use. A verifier agent serves as the harness's acceptance function, enforcing factual grounding, citation fidelity, and cross-modal consistency throughout the workflow. We further introduce \textsc{Ptah}Eval, an evaluation protocol that augments existing benchmarks with image-level and presentation-level assessments. Experiments on deep research benchmarks show that \textsc{Ptah} produces more reliable, visually informative, and usable human-facing multimodal reports than strong baselines.
Agent-World: Scaling Real-World Environment Synthesis for Evolving General Agent Intelligence
Apr 20, 2026Large language models are increasingly expected to serve as general-purpose agents that interact with external, stateful tool environments. The Model Context Protocol (MCP) and broader agent skills offer a unified interface for connecting agents with scalable real-world services, but training robust agents remains limited by the lack of realistic environments and principled mechanisms for life-long learning. In this paper, we present \textbf{Agent-World}, a self-evolving training arena for advancing general agent intelligence through scalable environments. Agent-World has two main components: (1) Agentic Environment-Task Discovery, which autonomously explores topic-aligned databases and executable tool ecosystems from thousands of real-world environment themes and synthesizes verifiable tasks with controllable difficulty; and (2) Continuous Self-Evolving Agent Training, which combines multi-environment reinforcement learning with a self-evolving agent arena that automatically identifies capability gaps through dynamic task synthesis and drives targeted learning, enabling the co-evolution of agent policies and environments. Across 23 challenging agent benchmarks, Agent-World-8B and 14B consistently outperforms strong proprietary models and environment scaling baselines. Further analyses reveal scaling trends in relation to environment diversity and self-evolution rounds, offering insights for building general agent intelligence.
OmniGAIA: Towards Native Omni-Modal AI Agents
Feb 26, 2026Human intelligence naturally intertwines omni-modal perception -- spanning vision, audio, and language -- with complex reasoning and tool usage to interact with the world. However, current multi-modal LLMs are primarily confined to bi-modal interactions (e.g., vision-language), lacking the unified cognitive capabilities required for general AI assistants. To bridge this gap, we introduce OmniGAIA, a comprehensive benchmark designed to evaluate omni-modal agents on tasks necessitating deep reasoning and multi-turn tool execution across video, audio, and image modalities. Constructed via a novel omni-modal event graph approach, OmniGAIA synthesizes complex, multi-hop queries derived from real-world data that require cross-modal reasoning and external tool integration. Furthermore, we propose OmniAtlas, a native omni-modal foundation agent under tool-integrated reasoning paradigm with active omni-modal perception. Trained on trajectories synthesized via a hindsight-guided tree exploration strategy and OmniDPO for fine-grained error correction, OmniAtlas effectively enhances the tool-use capabilities of existing open-source models. This work marks a step towards next-generation native omni-modal AI assistants for real-world scenarios.
ET-Agent: Incentivizing Effective Tool-Integrated Reasoning Agent via Behavior Calibration
Jan 11, 2026Large Language Models (LLMs) can extend their parameter knowledge limits by adopting the Tool-Integrated Reasoning (TIR) paradigm. However, existing LLM-based agent training framework often focuses on answers' accuracy, overlooking specific alignment for behavior patterns. Consequently, agent often exhibits ineffective actions during TIR tasks, such as redundant and insufficient tool calls. How to calibrate erroneous behavioral patterns when executing TIR tasks, thereby exploring effective trajectories, remains an open-ended problem. In this paper, we propose ET-Agent, a training framework for calibrating agent's tool-use behavior through two synergistic perspectives: Self-evolving Data Flywheel and Behavior Calibration Training. Specifically, we introduce a self-evolutionary data flywheel to generate enhanced data, used to fine-tune LLM to improve its exploration ability. Based on this, we implement an two-phases behavior-calibration training framework. It is designed to progressively calibrate erroneous behavioral patterns to optimal behaviors. Further in-depth experiments confirm the superiority of \ourmodel{} across multiple dimensions, including correctness, efficiency, reasoning conciseness, and tool execution accuracy. Our ET-Agent framework provides practical insights for research in the TIR field. Codes can be found in https://github.com/asilverlight/ET-Agent
EnvScaler: Scaling Tool-Interactive Environments for LLM Agent via Programmatic Synthesis
Jan 09, 2026Large language models (LLMs) are expected to be trained to act as agents in various real-world environments, but this process relies on rich and varied tool-interaction sandboxes. However, access to real systems is often restricted; LLM-simulated environments are prone to hallucinations and inconsistencies; and manually built sandboxes are hard to scale. In this paper, we propose EnvScaler, an automated framework for scalable tool-interaction environments via programmatic synthesis. EnvScaler comprises two components. First, SkelBuilder constructs diverse environment skeletons through topic mining, logic modeling, and quality evaluation. Then, ScenGenerator generates multiple task scenarios and rule-based trajectory validation functions for each environment. With EnvScaler, we synthesize 191 environments and about 7K scenarios, and apply them to Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) for Qwen3 series models. Results on three benchmarks show that EnvScaler significantly improves LLMs' ability to solve tasks in complex environments involving multi-turn, multi-tool interactions. We release our code and data at https://github.com/RUC-NLPIR/EnvScaler.
SmartSearch: Process Reward-Guided Query Refinement for Search Agents
Jan 08, 2026Large language model (LLM)-based search agents have proven promising for addressing knowledge-intensive problems by incorporating information retrieval capabilities. Existing works largely focus on optimizing the reasoning paradigms of search agents, yet the quality of intermediate search queries during reasoning remains overlooked. As a result, the generated queries often remain inaccurate, leading to unexpected retrieval results and ultimately limiting search agents' overall effectiveness. To mitigate this issue, we introduce SmartSearch, a framework built upon two key mechanisms: (1) Process rewards, which provide fine-grained supervision for the quality of each intermediate search query through Dual-Level Credit Assessment. (2) Query refinement, which promotes the optimization of query generation by selectively refining low-quality search queries and regenerating subsequent search rounds based on these refinements. To enable the search agent to progressively internalize the ability to improve query quality under the guidance of process rewards, we design a three-stage curriculum learning framework. This framework guides the agent through a progression from imitation, to alignment, and ultimately to generalization. Experimental results show that SmartSearch consistently surpasses existing baselines, and additional quantitative analyses further confirm its significant gains in both search efficiency and query quality. The code is available at https://github.com/MYVAE/SmartSearch.
V-Thinker: Interactive Thinking with Images
Nov 06, 2025Empowering Large Multimodal Models (LMMs) to deeply integrate image interaction with long-horizon reasoning capabilities remains a long-standing challenge in this field. Recent advances in vision-centric reasoning explore a promising "Thinking with Images" paradigm for LMMs, marking a shift from image-assisted reasoning to image-interactive thinking. While this milestone enables models to focus on fine-grained image regions, progress remains constrained by limited visual tool spaces and task-specific workflow designs. To bridge this gap, we present V-Thinker, a general-purpose multimodal reasoning assistant that enables interactive, vision-centric thinking through end-to-end reinforcement learning. V-Thinker comprises two key components: (1) a Data Evolution Flywheel that automatically synthesizes, evolves, and verifies interactive reasoning datasets across three dimensions-diversity, quality, and difficulty; and (2) a Visual Progressive Training Curriculum that first aligns perception via point-level supervision, then integrates interactive reasoning through a two-stage reinforcement learning framework. Furthermore, we introduce VTBench, an expert-verified benchmark targeting vision-centric interactive reasoning tasks. Extensive experiments demonstrate that V-Thinker consistently outperforms strong LMM-based baselines in both general and interactive reasoning scenarios, providing valuable insights for advancing image-interactive reasoning applications.
ToolScope: An Agentic Framework for Vision-Guided and Long-Horizon Tool Use
Oct 31, 2025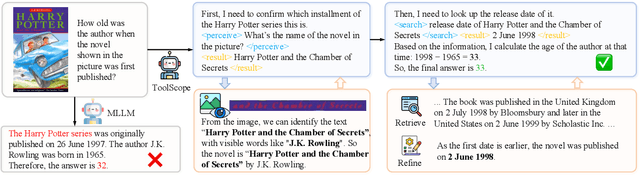
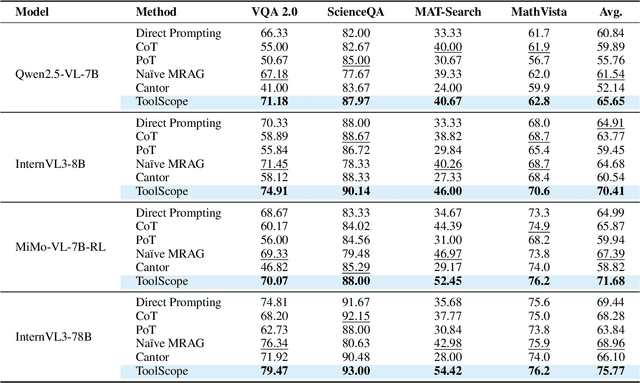
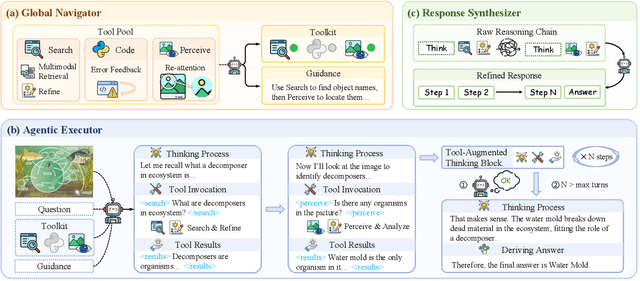
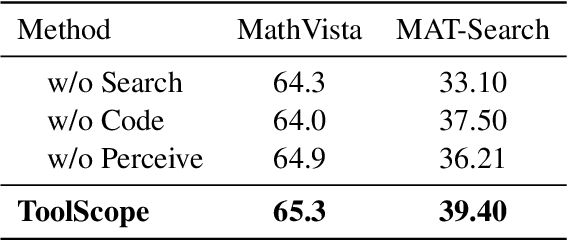
Recently, large language models (LLMs) have demonstrated remarkable problem-solving capabilities by autonomously integrating with external tools for collaborative reasoning. However, due to the inherently complex and diverse nature of multimodal information, enabling multimodal large language models (MLLMs) to flexibly and efficiently utilize external tools during reasoning remains an underexplored challenge. In this work, we introduce ToolScope, an agentic framework designed to unify global planning with local multimodal perception, adopting a specialized Perceive tool to mitigates visual context degradation in long-horizon VQA task. ToolScope comprises three primary components: the Global Navigator, the Agentic Executor, and the Response Synthesizer. The Global Navigator functions as a "telescope", offering high-level strategic guidance. The Agentic Executor operates iteratively to augment MLLM with local perception through the integration of external tools-Search, Code, and Perceive. Finally, the Response Synthesizer consolidates and organizes the reasoning process into a coherent, user-friendly output. We evaluate ToolScope on four VQA benchmarks across diverse domains, including VQA 2.0, ScienceQA, MAT-Search and MathVista. It demonstrates strong generalization capabilities, achieving an average performance improvement of up to +6.69% across all datasets.