 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
Dec 12, 2025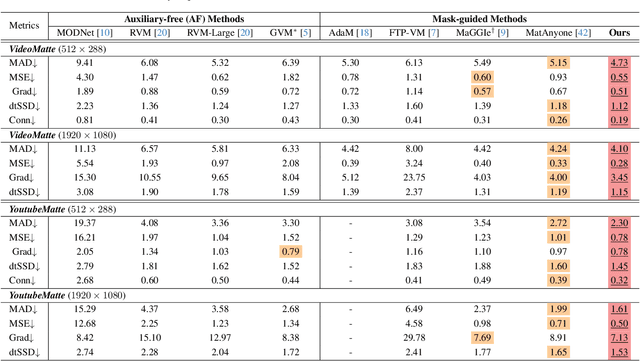
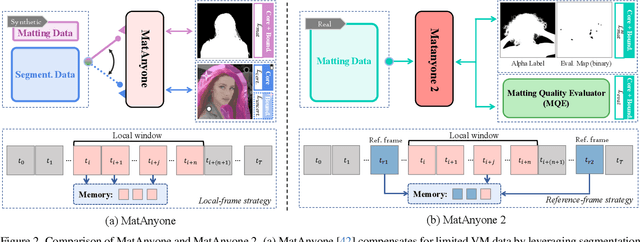
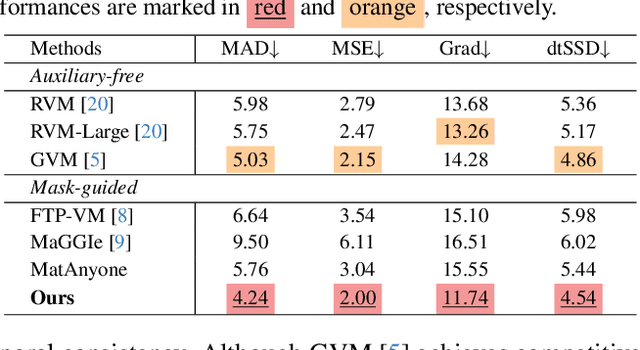
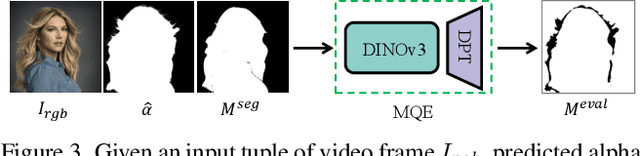
Video matting remains limited by the scale and realism of existing datasets. While leveraging segmentation data can enhance semantic stability, the lack of effective boundary supervision often leads to segmentation-like mattes lacking fine details. To this end, we introduce a learned Matting Quality Evaluator (MQE) that assesses semantic and boundary quality of alpha mattes without ground truth. It produces a pixel-wise evaluation map that identifies reliable and erroneous regions, enabling fine-grained quality assessment. The MQE scales up video matting in two ways: (1) as an online matting-quality feedback during training to suppress erroneous regions, providing comprehensive supervision, and (2) as an offline selection module for data curation, improving annotation quality by combining the strengths of leading video and image matting models. This process allows us to build a large-scale real-world video matting dataset, VMReal, containing 28K clips and 2.4M frames. To handle large appearance variations in long videos, we introduce a reference-frame training strategy that incorporates long-range frames beyond the local window for effective training. Our MatAnyone 2 achieves state-of-the-art performance on both synthetic and real-world benchmarks, surpassing prior methods across all metrics.
V-Thinker: Interactive Thinking with Images
Nov 06, 2025Empowering Large Multimodal Models (LMMs) to deeply integrate image interaction with long-horizon reasoning capabilities remains a long-standing challenge in this field. Recent advances in vision-centric reasoning explore a promising "Thinking with Images" paradigm for LMMs, marking a shift from image-assisted reasoning to image-interactive thinking. While this milestone enables models to focus on fine-grained image regions, progress remains constrained by limited visual tool spaces and task-specific workflow designs. To bridge this gap, we present V-Thinker, a general-purpose multimodal reasoning assistant that enables interactive, vision-centric thinking through end-to-end reinforcement learning. V-Thinker comprises two key components: (1) a Data Evolution Flywheel that automatically synthesizes, evolves, and verifies interactive reasoning datasets across three dimensions-diversity, quality, and difficulty; and (2) a Visual Progressive Training Curriculum that first aligns perception via point-level supervision, then integrates interactive reasoning through a two-stage reinforcement learning framework. Furthermore, we introduce VTBench, an expert-verified benchmark targeting vision-centric interactive reasoning tasks. Extensive experiments demonstrate that V-Thinker consistently outperforms strong LMM-based baselines in both general and interactive reasoning scenarios, providing valuable insights for advancing image-interactive reasoning applications.
We-Math 2.0: A Versatile MathBook System for Incentivizing Visual Mathematical Reasoning
Aug 14, 2025Multimodal Large Language Models (MLLMs) have demonstrated impressive capabilities across various tasks, but still struggle with complex mathematical reasoning. Existing research primarily focuses on dataset construction and method optimization, often overlooking two critical aspects: comprehensive knowledge-driven design and model-centric data space modeling. In this paper, we introduce We-Math 2.0, a unified system that integrates a structured mathematical knowledge system, model-centric data space modeling, and a reinforcement learning (RL)-based training paradigm to comprehensively enhance the mathematical reasoning abilities of MLLMs. The key contributions of We-Math 2.0 are fourfold: (1) MathBook Knowledge System: We construct a five-level hierarchical system encompassing 491 knowledge points and 1,819 fundamental principles. (2) MathBook-Standard & Pro: We develop MathBook-Standard, a dataset that ensures broad conceptual coverage and flexibility through dual expansion. Additionally, we define a three-dimensional difficulty space and generate 7 progressive variants per problem to build MathBook-Pro, a challenging dataset for robust training. (3) MathBook-RL: We propose a two-stage RL framework comprising: (i) Cold-Start Fine-tuning, which aligns the model with knowledge-oriented chain-of-thought reasoning; and (ii) Progressive Alignment RL, leveraging average-reward learning and dynamic data scheduling to achieve progressive alignment across difficulty levels. (4) MathBookEval: We introduce a comprehensive benchmark covering all 491 knowledge points with diverse reasoning step distributions. Experimental results show that MathBook-RL performs competitively with existing baselines on four widely-used benchmarks and achieves strong results on MathBookEval, suggesting promising generalization in mathematical reasoning.
ObjectClear: Complete Object Removal via Object-Effect Attention
May 28, 2025Object removal requires eliminating not only the target object but also its effects, such as shadows and reflections. However, diffusion-based inpainting methods often produce artifacts, hallucinate content, alter background, and struggle to remove object effects accurately. To address this challenge, we introduce a new dataset for OBject-Effect Removal, named OBER, which provides paired images with and without object effects, along with precise masks for both objects and their associated visual artifacts. The dataset comprises high-quality captured and simulated data, covering diverse object categories and complex multi-object scenes. Building on OBER, we propose a novel framework, ObjectClear, which incorporates an object-effect attention mechanism to guide the model toward the foreground removal regions by learning attention masks, effectively decoupling foreground removal from background reconstruction. Furthermore, the predicted attention map enables an attention-guided fusion strategy during inference, greatly preserving background details. Extensive experiments demonstrate that ObjectClear outperforms existing methods, achieving improved object-effect removal quality and background fidelity, especially in complex scenarios.
MatAnyone: Stable Video Matting with Consistent Memory Propagation
Jan 24, 2025



Auxiliary-free human video matting methods, which rely solely on input frames, often struggle with complex or ambiguous backgrounds. To address this, we propose MatAnyone, a robust framework tailored for target-assigned video matting. Specifically, building on a memory-based paradigm, we introduce a consistent memory propagation module via region-adaptive memory fusion, which adaptively integrates memory from the previous frame. This ensures semantic stability in core regions while preserving fine-grained details along object boundaries. For robust training, we present a larger, high-quality, and diverse dataset for video matting. Additionally, we incorporate a novel training strategy that efficiently leverages large-scale segmentation data, boosting matting stability. With this new network design, dataset, and training strategy, MatAnyone delivers robust and accurate video matting results in diverse real-world scenarios, outperforming existing methods.
Multi-Dimensional Insights: Benchmarking Real-World Personalization in Large Multimodal Models
Dec 17, 2024



The rapidly developing field of large multimodal models (LMMs) has led to the emergence of diverse models with remarkable capabilities. However, existing benchmarks fail to comprehensively, objectively and accurately evaluate whether LMMs align with the diverse needs of humans in real-world scenarios. To bridge this gap, we propose the Multi-Dimensional Insights (MDI) benchmark, which includes over 500 images covering six common scenarios of human life. Notably, the MDI-Benchmark offers two significant advantages over existing evaluations: (1) Each image is accompanied by two types of questions: simple questions to assess the model's understanding of the image, and complex questions to evaluate the model's ability to analyze and reason beyond basic content. (2) Recognizing that people of different age groups have varying needs and perspectives when faced with the same scenario, our benchmark stratifies questions into three age categories: young people, middle-aged people, and older people. This design allows for a detailed assessment of LMMs' capabilities in meeting the preferences and needs of different age groups. With MDI-Benchmark, the strong model like GPT-4o achieve 79% accuracy on age-related tasks, indicating that existing LMMs still have considerable room for improvement in addressing real-world applications. Looking ahead, we anticipate that the MDI-Benchmark will open new pathways for aligning real-world personalization in LMMs. The MDI-Benchmark data and evaluation code are available at https://mdi-benchmark.github.io/
MIPI 2024 Challenge on Few-shot RAW Image Denoising: Methods and Results
Jun 11, 2024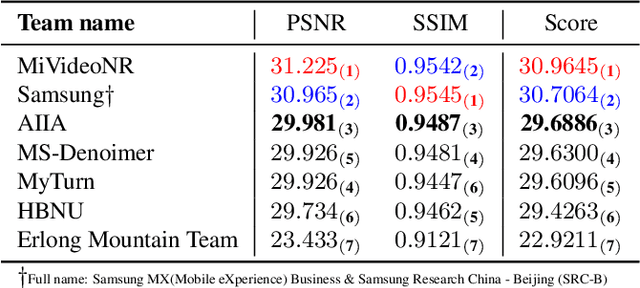
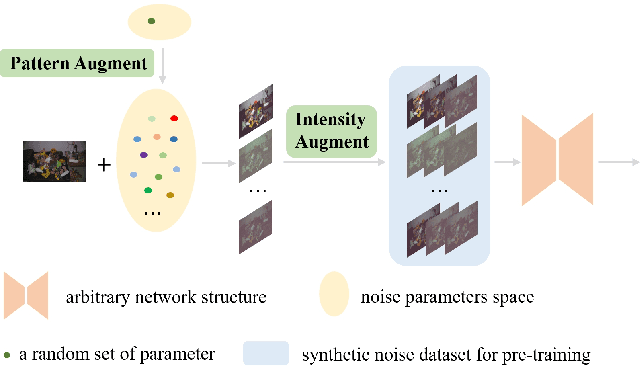

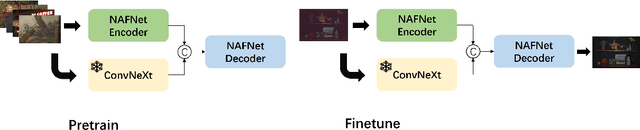
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Few-shot RAW Image Denoising track on MIPI 2024. In total, 165 participants were successfully registered, and 7 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art erformance on Few-shot RAW Image Denoising. More details of this challenge and the link to the dataset can be found at https://mipichallenge.org/MIPI2024.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024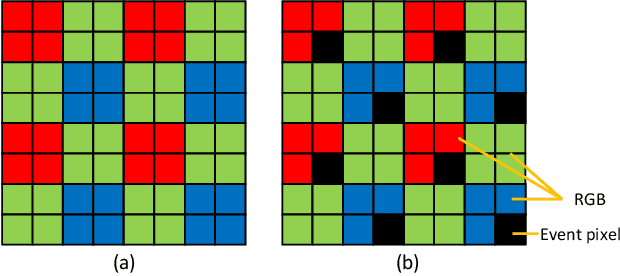
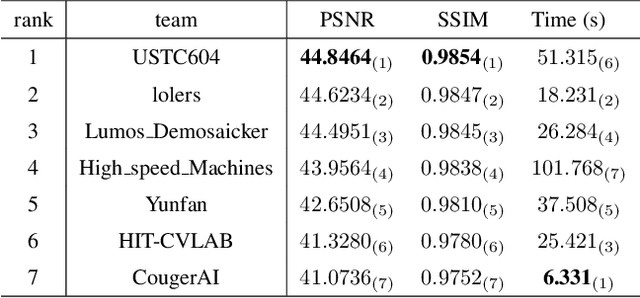
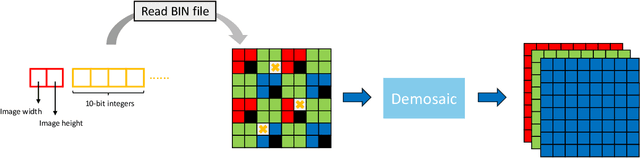

The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024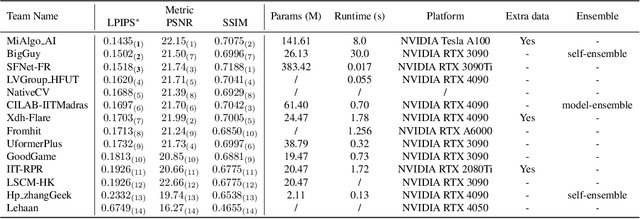
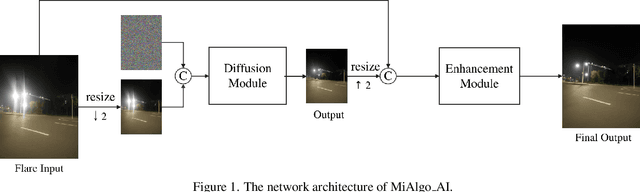
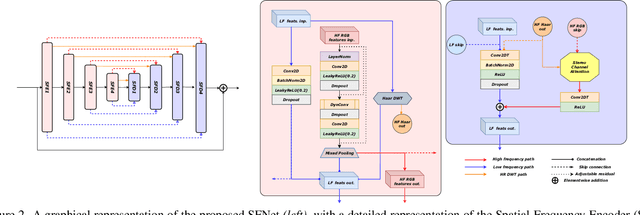
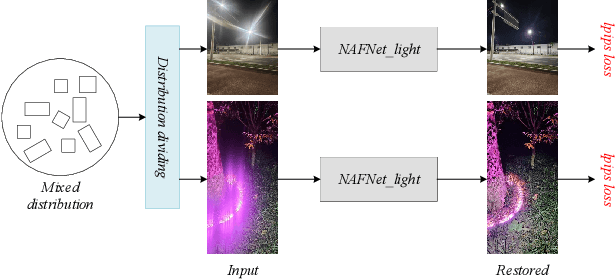
The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution
Dec 11, 2023Text-based diffusion models have exhibited remarkable success in generation and editing, showing great promise for enhancing visual content with their generative prior. However, applying these models to video super-resolution remains challenging due to the high demands for output fidelity and temporal consistency, which is complicated by the inherent randomness in diffusion models. Our study introduces Upscale-A-Video, a text-guided latent diffusion framework for video upscaling. This framework ensures temporal coherence through two key mechanisms: locally, it integrates temporal layers into U-Net and VAE-Decoder, maintaining consistency within short sequences; globally, without training, a flow-guided recurrent latent propagation module is introduced to enhance overall video stability by propagating and fusing latent across the entire sequences. Thanks to the diffusion paradigm, our model also offers greater flexibility by allowing text prompts to guide texture creation and adjustable noise levels to balance restoration and generation, enabling a trade-off between fidelity and quality. Extensive experiments show that Upscale-A-Video surpasses existing methods in both synthetic and real-world benchmarks, as well as in AI-generated videos, showcasing impressive visual realism and temporal consistency.