 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjectClear: Complete Object Removal via Object-Effect Attention
May 28, 2025Object removal requires eliminating not only the target object but also its effects, such as shadows and reflections. However, diffusion-based inpainting methods often produce artifacts, hallucinate content, alter background, and struggle to remove object effects accurately. To address this challenge, we introduce a new dataset for OBject-Effect Removal, named OBER, which provides paired images with and without object effects, along with precise masks for both objects and their associated visual artifacts. The dataset comprises high-quality captured and simulated data, covering diverse object categories and complex multi-object scenes. Building on OBER, we propose a novel framework, ObjectClear, which incorporates an object-effect attention mechanism to guide the model toward the foreground removal regions by learning attention masks, effectively decoupling foreground removal from background reconstruction. Furthermore, the predicted attention map enables an attention-guided fusion strategy during inference, greatly preserving background details. Extensive experiments demonstrate that ObjectClear outperforms existing methods, achieving improved object-effect removal quality and background fidelity, especially in complex scenarios.
MatAnyone: Stable Video Matting with Consistent Memory Propagation
Jan 24, 2025



Auxiliary-free human video matting methods, which rely solely on input frames, often struggle with complex or ambiguous backgrounds. To address this, we propose MatAnyone, a robust framework tailored for target-assigned video matting. Specifically, building on a memory-based paradigm, we introduce a consistent memory propagation module via region-adaptive memory fusion, which adaptively integrates memory from the previous frame. This ensures semantic stability in core regions while preserving fine-grained details along object boundaries. For robust training, we present a larger, high-quality, and diverse dataset for video matting. Additionally, we incorporate a novel training strategy that efficiently leverages large-scale segmentation data, boosting matting stability. With this new network design, dataset, and training strategy, MatAnyone delivers robust and accurate video matting results in diverse real-world scenarios, outperforming existing methods.
Adaptive Window Pruning for Efficient Local Motion Deblurring
Jun 25, 2023
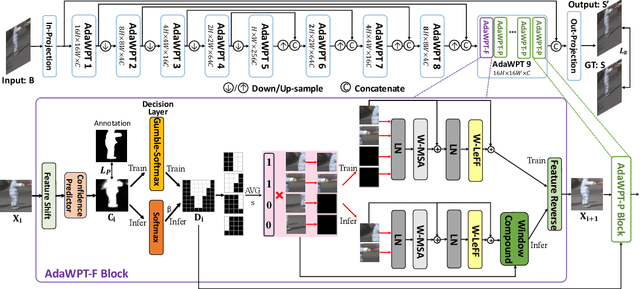
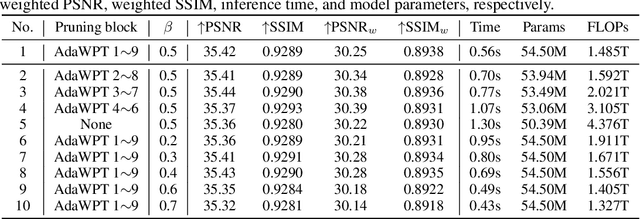

Local motion blur commonly occurs in real-world photography due to the mixing between moving objects and stationary backgrounds during exposure. Existing image deblurring methods predominantly focus on global deblurring, inadvertently affecting the sharpness of backgrounds in locally blurred images and wasting unnecessary computation on sharp pixels, especially for high-resolution images. This paper aims to adaptively and efficiently restore high-resolution locally blurred images. We propose a local motion deblurring vision Transformer (LMD-ViT) built on adaptive window pruning Transformer blocks (AdaWPT). To focus deblurring on local regions and reduce computation, AdaWPT prunes unnecessary windows, only allowing the active windows to be involved in the deblurring processes. The pruning operation relies on the blurriness confidence predicted by a confidence predictor that is trained end-to-end using a reconstruction loss with Gumbel-Softmax re-parameterization and a pruning loss guided by annotated blur masks. Our method removes local motion blur effectively without distorting sharp regions, demonstrated by its exceptional perceptual and quantitative improvements (+0.24dB) compared to state-of-the-art methods. In addition, our approach substantially reduces FLOPs by 66% and achieves more than a twofold increase in inference speed compared to Transformer-based deblurring methods. We will make our code and annotated blur masks publicly available.
BeautyREC: Robust, Efficient, and Content-preserving Makeup Transfer
Dec 12, 2022In this work, we propose a Robust, Efficient, and Component-specific makeup transfer method (abbreviated as BeautyREC). A unique departure from prior methods that leverage global attention, simply concatenate features, or implicitly manipulate features in latent space, we propose a component-specific correspondence to directly transfer the makeup style of a reference image to the corresponding components (e.g., skin, lips, eyes) of a source image, making elaborate and accurate local makeup transfer. As an auxiliary, the long-range visual dependencies of Transformer are introduced for effective global makeup transfer. Instead of the commonly used cycle structure that is complex and unstable, we employ a content consistency loss coupled with a content encoder to implement efficient single-path makeup transfer. The key insights of this study are modeling component-specific correspondence for local makeup transfer, capturing long-range dependencies for global makeup transfer, and enabling efficient makeup transfer via a single-path structure. We also contribute BeautyFace, a makeup transfer dataset to supplement existing datasets. This dataset contains 3,000 faces, covering more diverse makeup styles, face poses, and races. Each face has annotated parsing map. Extensive experiments demonstrate the effectiveness of our method against state-of-the-art methods. Besides, our method is appealing as it is with only 1M parameters, outperforming the state-of-the-art methods (BeautyGAN: 8.43M, PSGAN: 12.62M, SCGAN: 15.30M, CPM: 9.24M, SSAT: 10.48M).