 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatAnyone 2: Scaling Video Matting via a Learned Quality Evaluator
Dec 12, 2025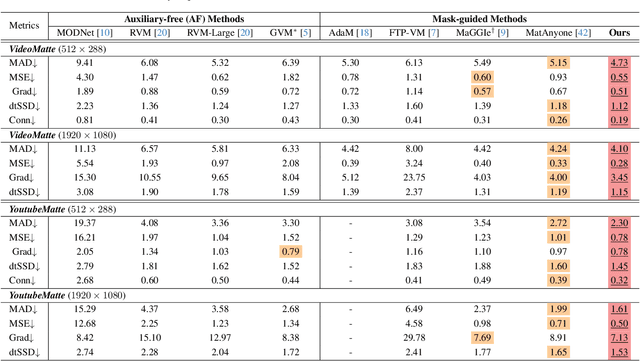
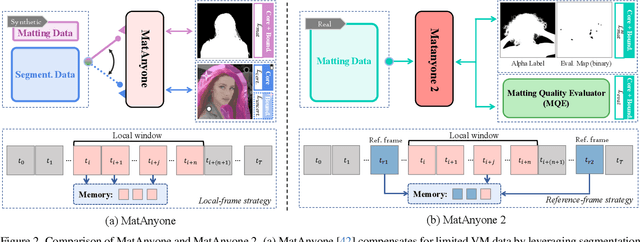
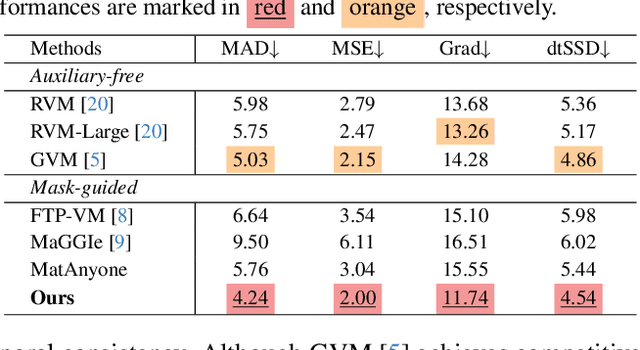
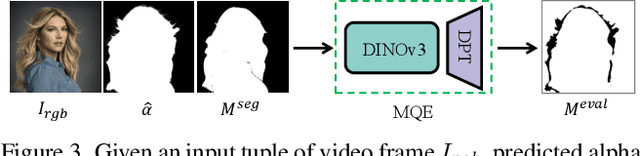
Video matting remains limited by the scale and realism of existing datasets. While leveraging segmentation data can enhance semantic stability, the lack of effective boundary supervision often leads to segmentation-like mattes lacking fine details. To this end, we introduce a learned Matting Quality Evaluator (MQE) that assesses semantic and boundary quality of alpha mattes without ground truth. It produces a pixel-wise evaluation map that identifies reliable and erroneous regions, enabling fine-grained quality assessment. The MQE scales up video matting in two ways: (1) as an online matting-quality feedback during training to suppress erroneous regions, providing comprehensive supervision, and (2) as an offline selection module for data curation, improving annotation quality by combining the strengths of leading video and image matting models. This process allows us to build a large-scale real-world video matting dataset, VMReal, containing 28K clips and 2.4M frames. To handle large appearance variations in long videos, we introduce a reference-frame training strategy that incorporates long-range frames beyond the local window for effective training. Our MatAnyone 2 achieves state-of-the-art performance on both synthetic and real-world benchmarks, surpassing prior methods across all metrics.
SA-LUT: Spatial Adaptive 4D Look-Up Table for Photorealistic Style Transfer
Jun 16, 2025Photorealistic style transfer (PST) enables real-world color grading by adapting reference image colors while preserving content structure. Existing methods mainly follow either approaches: generation-based methods that prioritize stylistic fidelity at the cost of content integrity and efficiency, or global color transformation methods such as LUT, which preserve structure but lack local adaptability. To bridge this gap, we propose Spatial Adaptive 4D Look-Up Table (SA-LUT), combining LUT efficiency with neural network adaptability. SA-LUT features: (1) a Style-guided 4D LUT Generator that extracts multi-scale features from the style image to predict a 4D LUT, and (2) a Context Generator using content-style cross-attention to produce a context map. This context map enables spatially-adaptive adjustments, allowing our 4D LUT to apply precise color transformations while preserving structural integrity. To establish a rigorous evaluation framework for photorealistic style transfer, we introduce PST50, the first benchmark specifically designed for PST assessment. Experiments demonstrate that SA-LUT substantially outperforms state-of-the-art methods, achieving a 66.7% reduction in LPIPS score compared to 3D LUT approaches, while maintaining real-time performance at 16 FPS for video stylization. Our code and benchmark are available at https://github.com/Ry3nG/SA-LUT
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation
May 29, 2025In this report, we present OpenUni, a simple, lightweight, and fully open-source baseline for unifying multimodal understanding and generation. Inspired by prevailing practices in unified model learning, we adopt an efficient training strategy that minimizes the training complexity and overhead by bridging the off-the-shelf multimodal large language models (LLMs) and diffusion models through a set of learnable queries and a light-weight transformer-based connector. With a minimalist choice of architecture, we demonstrate that OpenUni can: 1) generate high-quality and instruction-aligned images, and 2) achieve exceptional performance on standard benchmarks such as GenEval, DPG- Bench, and WISE, with only 1.1B and 3.1B activated parameters. To support open research and community advancement, we release all model weights, training code, and our curated training datasets (including 23M image-text pairs) at https://github.com/wusize/OpenUni.
Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
Mar 27, 2025
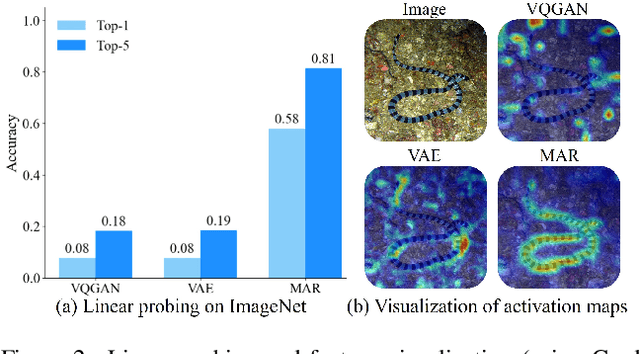
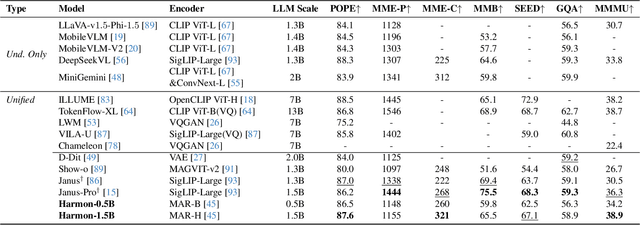
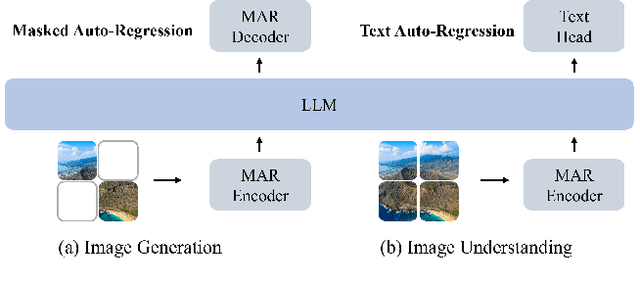
Unifying visual understanding and generation within a single multimodal framework remains a significant challenge, as the two inherently heterogeneous tasks require representations at different levels of granularity. Current approaches that utilize vector quantization (VQ) or variational autoencoders (VAE) for unified visual representation prioritize intrinsic imagery features over semantics, compromising understanding performance. In this work, we take inspiration from masked image modelling (MIM) that learns rich semantics via a mask-and-reconstruct pre-training and its successful extension to masked autoregressive (MAR) image generation. A preliminary study on the MAR encoder's representation reveals exceptional linear probing accuracy and precise feature response to visual concepts, which indicates MAR's potential for visual understanding tasks beyond its original generation role. Based on these insights, we present \emph{Harmon}, a unified autoregressive framework that harmonizes understanding and generation tasks with a shared MAR encoder. Through a three-stage training procedure that progressively optimizes understanding and generation capabilities, Harmon achieves state-of-the-art image generation results on the GenEval, MJHQ30K and WISE benchmarks while matching the performance of methods with dedicated semantic encoders (e.g., Janus) on image understanding benchmarks. Our code and models will be available at https://github.com/wusize/Harmon.
MatAnyone: Stable Video Matting with Consistent Memory Propagation
Jan 24, 2025



Auxiliary-free human video matting methods, which rely solely on input frames, often struggle with complex or ambiguous backgrounds. To address this, we propose MatAnyone, a robust framework tailored for target-assigned video matting. Specifically, building on a memory-based paradigm, we introduce a consistent memory propagation module via region-adaptive memory fusion, which adaptively integrates memory from the previous frame. This ensures semantic stability in core regions while preserving fine-grained details along object boundaries. For robust training, we present a larger, high-quality, and diverse dataset for video matting. Additionally, we incorporate a novel training strategy that efficiently leverages large-scale segmentation data, boosting matting stability. With this new network design, dataset, and training strategy, MatAnyone delivers robust and accurate video matting results in diverse real-world scenarios, outperforming existing methods.
Towards Robust and Expressive Whole-body Human Pose and Shape Estimation
Dec 14, 2023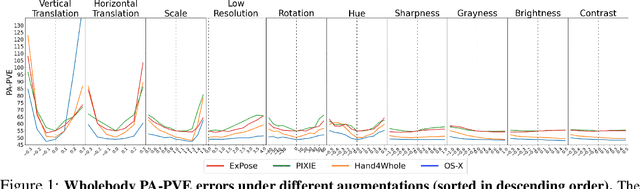


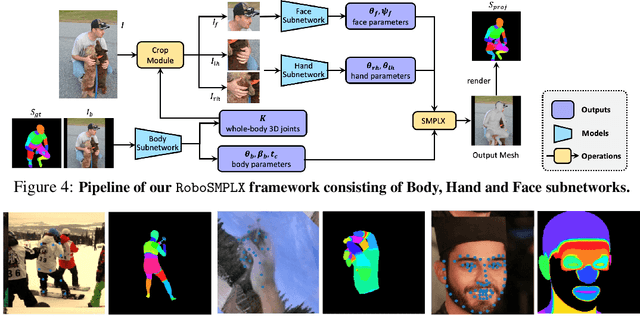
Whole-body pose and shape estimation aims to jointly predict different behaviors (e.g., pose, hand gesture, facial expression) of the entire human body from a monocular image. Existing methods often exhibit degraded performance under the complexity of in-the-wild scenarios. We argue that the accuracy and reliability of these models are significantly affected by the quality of the predicted \textit{bounding box}, e.g., the scale and alignment of body parts. The natural discrepancy between the ideal bounding box annotations and model detection results is particularly detrimental to the performance of whole-body pose and shape estimation. In this paper, we propose a novel framework to enhance the robustness of whole-body pose and shape estimation. Our framework incorporates three new modules to address the above challenges from three perspectives: \textbf{1) Localization Module} enhances the model's awareness of the subject's location and semantics within the image space. \textbf{2) Contrastive Feature Extraction Module} encourages the model to be invariant to robust augmentations by incorporating contrastive loss with dedicated positive samples. \textbf{3) Pixel Alignment Module} ensures the reprojected mesh from the predicted camera and body model parameters are accurate and pixel-aligned. We perform comprehensive experiments to demonstrate the effectiveness of our proposed framework on body, hands, face and whole-body benchmarks. Codebase is available at \url{https://github.com/robosmplx/robosmplx}.
PGDiff: Guiding Diffusion Models for Versatile Face Restoration via Partial Guidance
Sep 19, 2023Exploiting pre-trained diffusion models for restoration has recently become a favored alternative to the traditional task-specific training approach. Previous works have achieved noteworthy success by limiting the solution space using explicit degradation models. However, these methods often fall short when faced with complex degradations as they generally cannot be precisely modeled. In this paper, we propose PGDiff by introducing partial guidance, a fresh perspective that is more adaptable to real-world degradations compared to existing works. Rather than specifically defining the degradation process, our approach models the desired properties, such as image structure and color statistics of high-quality images, and applies this guidance during the reverse diffusion process. These properties are readily available and make no assumptions about the degradation process. When combined with a diffusion prior, this partial guidance can deliver appealing results across a range of restoration tasks. Additionally, PGDiff can be extended to handle composite tasks by consolidating multiple high-quality image properties, achieved by integrating the guidance from respective tasks. Experimental results demonstrate that our method not only outperforms existing diffusion-prior-based approaches but also competes favorably with task-specific models.
Modeling Continuous Motion for 3D Point Cloud Object Tracking
Mar 14, 2023The task of 3D single object tracking (SOT) with LiDAR point clouds is crucial for various applications, such as autonomous driving and robotics. However, existing approaches have primarily relied on appearance matching or motion modeling within only two successive frames, thereby overlooking the long-range continuous motion property of objects in 3D space. To address this issue, this paper presents a novel approach that views each tracklet as a continuous stream: at each timestamp, only the current frame is fed into the network to interact with multi-frame historical features stored in a memory bank, enabling efficient exploitation of sequential information. To achieve effective cross-frame message passing, a hybrid attention mechanism is designed to account for both long-range relation modeling and local geometric feature extraction. Furthermore, to enhance the utilization of multi-frame features for robust tracking, a contrastive sequence enhancement strategy is designed, which uses ground truth tracklets to augment training sequences and promote discrimination against false positives in a contrastive manner. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art method by significant margins (approximately 8%, 6%, and 12% improvements in the success performance on KITTI, nuScenes, and Waymo, respectively).
ReCasNet: Improving consistency within the two-stage mitosis detection framework
Feb 28, 2022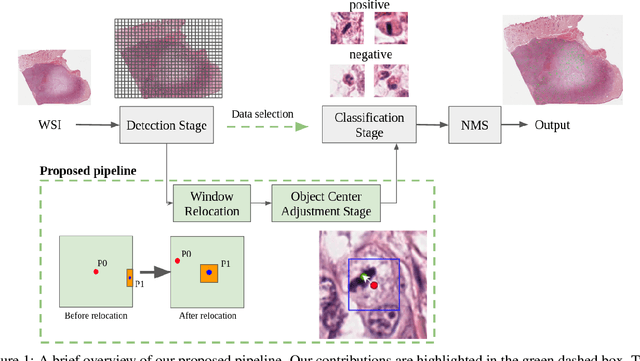
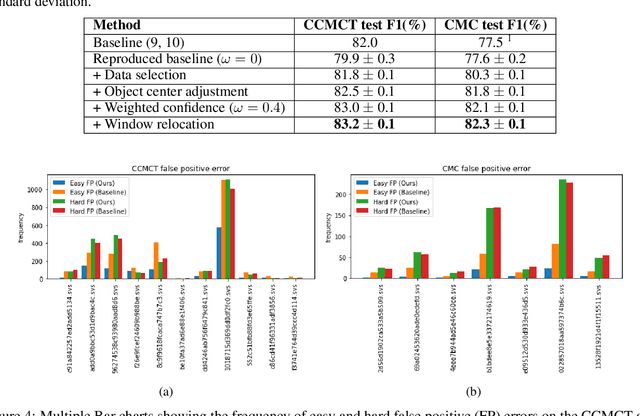
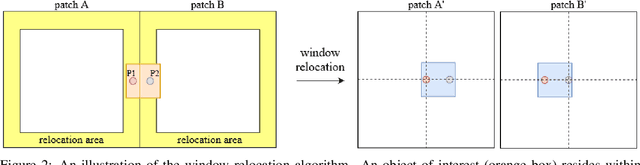

Mitotic count (MC) is an important histological parameter for cancer diagnosis and grading, but the manual process for obtaining MC from whole-slide histopathological images is very time-consuming and prone to error. Therefore, deep learning models have been proposed to facilitate this process. Existing approaches utilize a two-stage pipeline: the detection stage for identifying the locations of potential mitotic cells and the classification stage for refining prediction confidences. However, this pipeline formulation can lead to inconsistencies in the classification stage due to the poor prediction quality of the detection stage and the mismatches in training data distributions between the two stages. In this study, we propose a Refine Cascade Network (ReCasNet), an enhanced deep learning pipeline that mitigates the aforementioned problems with three improvements. First, window relocation was used to reduce the number of poor quality false positives generated during the detection stage. Second, object re-cropping was performed with another deep learning model to adjust poorly centered objects. Third, improved data selection strategies were introduced during the classification stage to reduce the mismatches in training data distributions. ReCasNet was evaluated on two large-scale mitotic figure recognition datasets, canine cutaneous mast cell tumor (CCMCT) and canine mammary carcinoma (CMC), which resulted in up to 4.8% percentage point improvements in the F1 scores for mitotic cell detection and 44.1% reductions in mean absolute percentage error (MAPE) for MC prediction. Techniques that underlie ReCasNet can be generalized to other two-stage object detection networks and should contribute to improving the performances of deep learning models in broad digital pathology applications.
Unsupervised Domain Adaptation for Retinal Vessel Segmentation with Adversarial Learning and Transfer Normalization
Aug 04, 2021
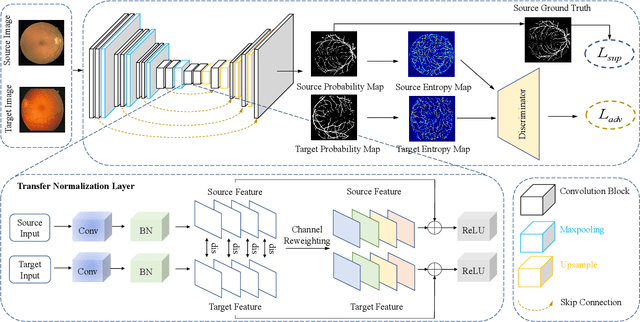
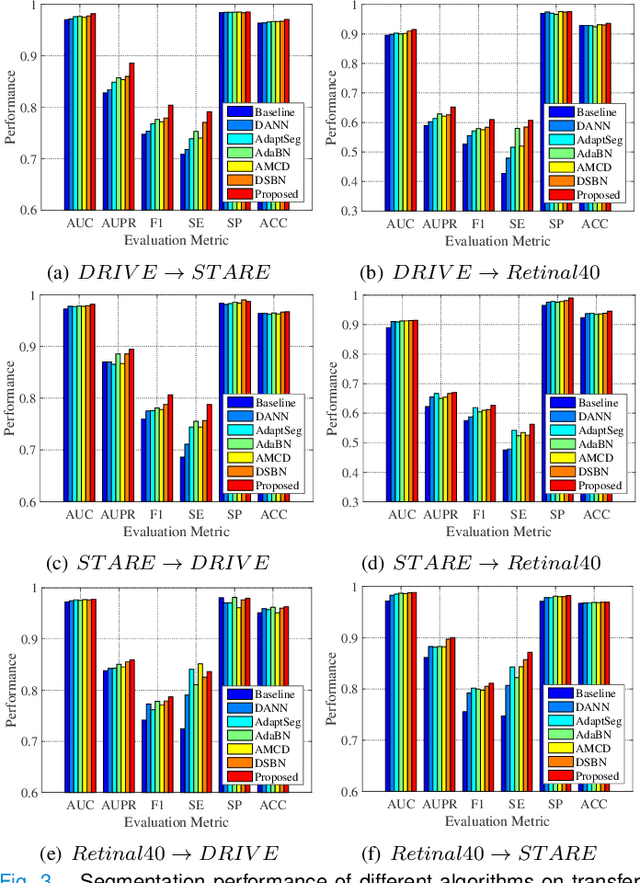

Retinal vessel segmentation plays a key role in computer-aided screening, diagnosis, and treatment of various cardiovascular and ophthalmic diseases. Recently, deep learning-based retinal vessel segmentation algorithms have achieved remarkable performance. However, due to the domain shift problem, the performance of these algorithms often degrades when they are applied to new data that is different from the training data. Manually labeling new data for each test domain is often a time-consuming and laborious task. In this work, we explore unsupervised domain adaptation in retinal vessel segmentation by using entropy-based adversarial learning and transfer normalization layer to train a segmentation network, which generalizes well across domains and requires no annotation of the target domain. Specifically, first, an entropy-based adversarial learning strategy is developed to reduce the distribution discrepancy between the source and target domains while also achieving the objective of entropy minimization on the target domain. In addition, a new transfer normalization layer is proposed to further boost the transferability of the deep network. It normalizes the features of each domain separately to compensate for the domain distribution gap. Besides, it also adaptively selects those feature channels that are more transferable between domains, thus further enhancing the generalization performance of the network. We conducted extensive experiments on three regular fundus image datasets and an ultra-widefield fundus image dataset, and the results show that our approach yields significant performance gains compared to other state-of-the-art methods.