 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrisma-World: Camera-Controllable Multi-Agent Video World Model
Jun 08, 2026Video world models have made rapid progress in generating controllable visual experiences, but most of them still simulate the world from a single observer. Extending such models to multiple agents raises a central challenge: if each agent's future state is generated independently, overlapping views may instantiate different versions of the same scene, leading to inconsistent objects, layouts, and appearances across agents. Conventional camera conditioning controls individual trajectories, but it does not explicitly couple the generation of views that should agree under shared scene geometry. We introduce Prisma-World, a camera-controllable multi-agent world model that formulates multi-agent generation as a joint geometry-aware denoising process for cross-view consistency. Prisma-World processes all agent videos within one full-attention sequence, uses a multi-agent RoPE design to distinguish agent identities while preserving synchronized temporal coordinates, and injects relative camera geometry into attention to bias overlapping viewpoints toward shared scene evidence. To further strengthen multi-view consistency and enhance global spatial perception, we augment our framework with an overlap-decaying curriculum training paradigm alongside minimap-conditioned structural guidance. To facilitate the training and evaluation of multi-agent models, we introduce PrismaDataset, a large-scale UE5 dataset with panoramic acquisition across diverse scenes, composable multi-agent view groups with flexible agent counts and complex camera trajectories, and precise camera/action annotations for consistency training and evaluation. Experiments show that a single Prisma-World model can generate high-fidelity multi-agent videos with flexible agent numbers, camera controllability, improved cross-view consistency, and spatial grounding under minimap guidance.
Knowledge Visualization: A Benchmark and Method for Knowledge-Intensive Text-to-Image Generation
Apr 24, 2026Recent text-to-image (T2I) models have demonstrated impressive capabilities in photorealistic synthesis and instruction following. However, their reliability in knowledge-intensive settings remains largely unexplored. Unlike natural image generation, knowledge visualization requires not only semantic alignment but also strict adherence to domain knowledge, structural constraints, and symbolic conventions, exposing a critical gap between visual plausibility and scientific correctness. To systematically study this problem, we introduce KVBench, a curriculum-grounded benchmark for evaluating knowledge-intensive T2I generation. KVBench covers six senior high-school subjects: Biology, Chemistry, Geography, History, Mathematics, and Physics. The benchmark consists of 1,800 expert-curated prompts derived from over 30 authoritative textbooks. Using this benchmark, we evaluate 14 state-of-the-art open- and closed-source models, revealing substantial deficiencies in logical reasoning, symbolic precision, and multilingual robustness, with open-source models consistently underperforming proprietary systems. To address these limitations, we further propose KE-Check, a two-stage framework that improves scientific fidelity via (1) Knowledge Elaboration for structured prompt enrichment, and (2) Checklist-Guided Refinement for explicit constraint enforcement through violation identification and constraint-guided editing. KE-Check effectively mitigates scientific hallucinations, narrowing the performance gap between open-source and leading closed-source models. Data and codes are publicly available at https://github.com/zhaoran66/KVBench.
UniReason 1.0: A Unified Reasoning Framework for World Knowledge Aligned Image Generation and Editing
Feb 02, 2026Unified multimodal models often struggle with complex synthesis tasks that demand deep reasoning, and typically treat text-to-image generation and image editing as isolated capabilities rather than interconnected reasoning steps. To address this, we propose UniReason, a unified framework that harmonizes these two tasks through a dual reasoning paradigm. We formulate generation as world knowledge-enhanced planning to inject implicit constraints, and leverage editing capabilities for fine-grained visual refinement to further correct visual errors via self-reflection. This approach unifies generation and editing within a shared representation, mirroring the human cognitive process of planning followed by refinement. We support this framework by systematically constructing a large-scale reasoning-centric dataset (~300k samples) covering five major knowledge domains (e.g., cultural commonsense, physics, etc.) for planning, alongside an agent-generated corpus for visual self-correction. Extensive experiments demonstrate that UniReason achieves advanced performance on reasoning-intensive benchmarks such as WISE, KrisBench and UniREditBench, while maintaining superior general synthesis capabilities.
Skywork UniPic 3.0: Unified Multi-Image Composition via Sequence Modeling
Jan 22, 2026The recent surge in popularity of Nano-Banana and Seedream 4.0 underscores the community's strong interest in multi-image composition tasks. Compared to single-image editing, multi-image composition presents significantly greater challenges in terms of consistency and quality, yet existing models have not disclosed specific methodological details for achieving high-quality fusion. Through statistical analysis, we identify Human-Object Interaction (HOI) as the most sought-after category by the community. We therefore systematically analyze and implement a state-of-the-art solution for multi-image composition with a primary focus on HOI-centric tasks. We present Skywork UniPic 3.0, a unified multimodal framework that integrates single-image editing and multi-image composition. Our model supports an arbitrary (1~6) number and resolution of input images, as well as arbitrary output resolutions (within a total pixel budget of 1024x1024). To address the challenges of multi-image composition, we design a comprehensive data collection, filtering, and synthesis pipeline, achieving strong performance with only 700K high-quality training samples. Furthermore, we introduce a novel training paradigm that formulates multi-image composition as a sequence-modeling problem, transforming conditional generation into unified sequence synthesis. To accelerate inference, we integrate trajectory mapping and distribution matching into the post-training stage, enabling the model to produce high-fidelity samples in just 8 steps and achieve a 12.5x speedup over standard synthesis sampling. Skywork UniPic 3.0 achieves state-of-the-art performance on single-image editing benchmark and surpasses both Nano-Banana and Seedream 4.0 on multi-image composition benchmark, thereby validating the effectiveness of our data pipeline and training paradigm. Code, models and dataset are publicly available.
RecTok: Reconstruction Distillation along Rectified Flow
Dec 17, 2025Visual tokenizers play a crucial role in diffusion models. The dimensionality of latent space governs both reconstruction fidelity and the semantic expressiveness of the latent feature. However, a fundamental trade-off is inherent between dimensionality and generation quality, constraining existing methods to low-dimensional latent spaces. Although recent works have leveraged vision foundation models to enrich the semantics of visual tokenizers and accelerate convergence, high-dimensional tokenizers still underperform their low-dimensional counterparts. In this work, we propose RecTok, which overcomes the limitations of high-dimensional visual tokenizers through two key innovations: flow semantic distillation and reconstruction--alignment distillation. Our key insight is to make the forward flow in flow matching semantically rich, which serves as the training space of diffusion transformers, rather than focusing on the latent space as in previous works. Specifically, our method distills the semantic information in VFMs into the forward flow trajectories in flow matching. And we further enhance the semantics by introducing a masked feature reconstruction loss. Our RecTok achieves superior image reconstruction, generation quality, and discriminative performance. It achieves state-of-the-art results on the gFID-50K under both with and without classifier-free guidance settings, while maintaining a semantically rich latent space structure. Furthermore, as the latent dimensionality increases, we observe consistent improvements. Code and model are available at https://shi-qingyu.github.io/rectok.github.io.
Generative Photographic Control for Scene-Consistent Video Cinematic Editing
Nov 17, 2025Cinematic storytelling is profoundly shaped by the artful manipulation of photographic elements such as depth of field and exposure. These effects are crucial in conveying mood and creating aesthetic appeal. However, controlling these effects in generative video models remains highly challenging, as most existing methods are restricted to camera motion control. In this paper, we propose CineCtrl, the first video cinematic editing framework that provides fine control over professional camera parameters (e.g., bokeh, shutter speed). We introduce a decoupled cross-attention mechanism to disentangle camera motion from photographic inputs, allowing fine-grained, independent control without compromising scene consistency. To overcome the shortage of training data, we develop a comprehensive data generation strategy that leverages simulated photographic effects with a dedicated real-world collection pipeline, enabling the construction of a large-scale dataset for robust model training. Extensive experiments demonstrate that our model generates high-fidelity videos with precisely controlled, user-specified photographic camera effects.
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation
May 29, 2025In this report, we present OpenUni, a simple, lightweight, and fully open-source baseline for unifying multimodal understanding and generation. Inspired by prevailing practices in unified model learning, we adopt an efficient training strategy that minimizes the training complexity and overhead by bridging the off-the-shelf multimodal large language models (LLMs) and diffusion models through a set of learnable queries and a light-weight transformer-based connector. With a minimalist choice of architecture, we demonstrate that OpenUni can: 1) generate high-quality and instruction-aligned images, and 2) achieve exceptional performance on standard benchmarks such as GenEval, DPG- Bench, and WISE, with only 1.1B and 3.1B activated parameters. To support open research and community advancement, we release all model weights, training code, and our curated training datasets (including 23M image-text pairs) at https://github.com/wusize/OpenUni.
Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
Mar 27, 2025
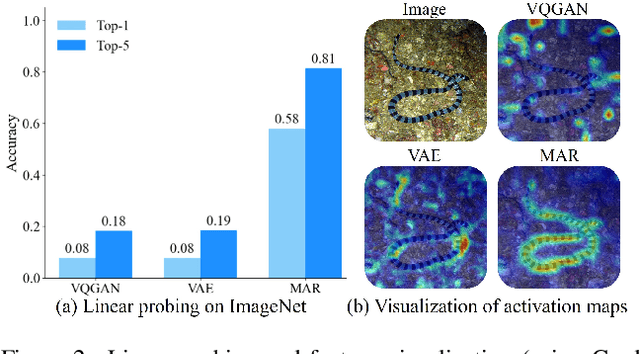
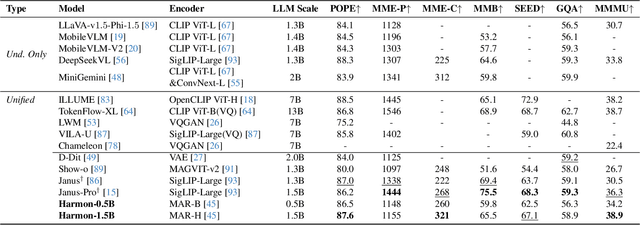
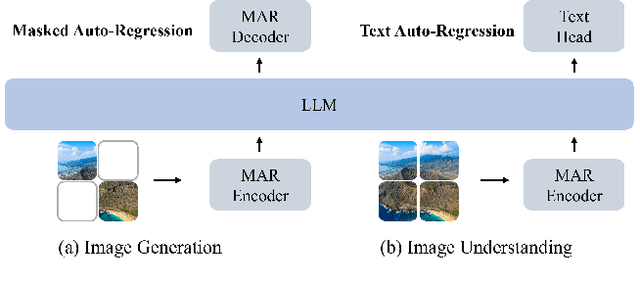
Unifying visual understanding and generation within a single multimodal framework remains a significant challenge, as the two inherently heterogeneous tasks require representations at different levels of granularity. Current approaches that utilize vector quantization (VQ) or variational autoencoders (VAE) for unified visual representation prioritize intrinsic imagery features over semantics, compromising understanding performance. In this work, we take inspiration from masked image modelling (MIM) that learns rich semantics via a mask-and-reconstruct pre-training and its successful extension to masked autoregressive (MAR) image generation. A preliminary study on the MAR encoder's representation reveals exceptional linear probing accuracy and precise feature response to visual concepts, which indicates MAR's potential for visual understanding tasks beyond its original generation role. Based on these insights, we present \emph{Harmon}, a unified autoregressive framework that harmonizes understanding and generation tasks with a shared MAR encoder. Through a three-stage training procedure that progressively optimizes understanding and generation capabilities, Harmon achieves state-of-the-art image generation results on the GenEval, MJHQ30K and WISE benchmarks while matching the performance of methods with dedicated semantic encoders (e.g., Janus) on image understanding benchmarks. Our code and models will be available at https://github.com/wusize/Harmon.
F-LMM: Grounding Frozen Large Multimodal Models
Jun 09, 2024



Endowing Large Multimodal Models (LMMs) with visual grounding capability can significantly enhance AIs' understanding of the visual world and their interaction with humans. However, existing methods typically fine-tune the parameters of LMMs to learn additional segmentation tokens and overfit grounding and segmentation datasets. Such a design would inevitably cause a catastrophic diminution in the indispensable conversational capability of general AI assistants. In this paper, we comprehensively evaluate state-of-the-art grounding LMMs across a suite of multimodal question-answering benchmarks, observing pronounced performance drops that indicate vanishing general knowledge comprehension and weakened instruction following ability. To address this issue, we present F-LMM -- grounding frozen off-the-shelf LMMs in human-AI conversations -- a straightforward yet effective design based on the fact that word-pixel correspondences conducive to visual grounding inherently exist in the attention weights of well-trained LMMs. Using only a few trainable CNN layers, we can translate word-pixel attention weights to mask logits, which a SAM-based mask refiner can further optimise. Our F-LMM neither learns special segmentation tokens nor utilises high-quality grounded instruction-tuning data, but achieves competitive performance on referring expression segmentation and panoptic narrative grounding benchmarks while completely preserving LMMs' original conversational ability. Additionally, with instruction-following ability preserved and grounding ability obtained, our F-LMM can perform visual chain-of-thought reasoning and better resist object hallucinations.
OMG-Seg: Is One Model Good Enough For All Segmentation?
Jan 18, 2024



In this work, we address various segmentation tasks, each traditionally tackled by distinct or partially unified models. We propose OMG-Seg, One Model that is Good enough to efficiently and effectively handle all the segmentation tasks, including image semantic, instance, and panoptic segmentation, as well as their video counterparts, open vocabulary settings, prompt-driven, interactive segmentation like SAM, and video object segmentation. To our knowledge, this is the first model to handle all these tasks in one model and achieve satisfactory performance. We show that OMG-Seg, a transformer-based encoder-decoder architecture with task-specific queries and outputs, can support over ten distinct segmentation tasks and yet significantly reduce computational and parameter overhead across various tasks and datasets. We rigorously evaluate the inter-task influences and correlations during co-training. Code and models are available at https://github.com/lxtGH/OMG-Seg.