 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDST-Det: Simple Dynamic Self-Training for Open-Vocabulary Object Detection
Paper and Code



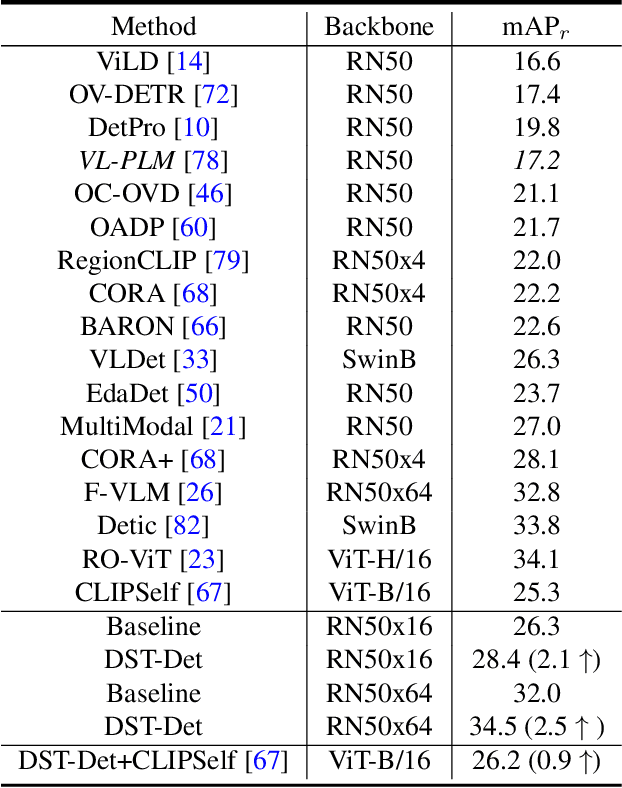
Open-vocabulary object detection (OVOD) aims to detect the objects beyond the set of categories observed during training. This work presents a simple yet effective strategy that leverages the zero-shot classification ability of pre-trained vision-language models (VLM), such as CLIP, to classify proposals for all possible novel classes directly. Unlike previous works that ignore novel classes during training and rely solely on the region proposal network (RPN) for novel object detection, our method selectively filters proposals based on specific design criteria. The resulting sets of identified proposals serve as pseudo-labels for novel classes during the training phase. It enables our self-training strategy to improve the recall and accuracy of novel classes in a self-training manner without requiring additional annotations or datasets. We further propose a simple offline pseudo-label generation strategy to refine the object detector. Empirical evaluations on three datasets, including LVIS, V3Det, and COCO, demonstrate significant improvements over the baseline performance without incurring additional parameters or computational costs during inference. In particular, compared with previous F-VLM, our method achieves a 1.7-2.0% improvement on LVIS dataset and 2.3-3.8% improvement on the recent challenging V3Det dataset. Our method also boosts the strong baseline by 6% mAP on COCO. The code and models will be publicly available at https://github.com/xushilin1/dst-det.