 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Based 3D Multi-Person Pose Estimation Using Multi-View Images
Paper and Code
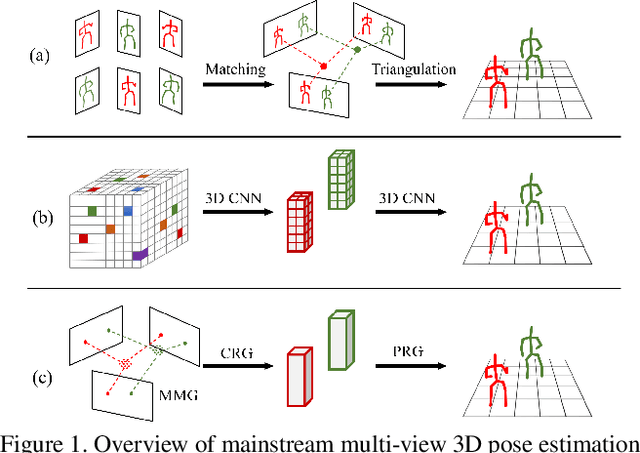



This paper studies the task of estimating the 3D human poses of multiple persons from multiple calibrated camera views. Following the top-down paradigm, we decompose the task into two stages, i.e. person localization and pose estimation. Both stages are processed in coarse-to-fine manners. And we propose three task-specific graph neural networks for effective message passing. For 3D person localization, we first use Multi-view Matching Graph Module (MMG) to learn the cross-view association and recover coarse human proposals. The Center Refinement Graph Module (CRG) further refines the results via flexible point-based prediction. For 3D pose estimation, the Pose Regression Graph Module (PRG) learns both the multi-view geometry and structural relations between human joints. Our approach achieves state-of-the-art performance on CMU Panoptic and Shelf datasets with significantly lower computation complexity.