 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Video Autoencoder with Decoupled Temporal and Spatial Context
Dec 12, 2025Video autoencoders compress videos into compact latent representations for efficient reconstruction, playing a vital role in enhancing the quality and efficiency of video generation. However, existing video autoencoders often entangle spatial and temporal information, limiting their ability to capture temporal consistency and leading to suboptimal performance. To address this, we propose Autoregressive Video Autoencoder (ARVAE), which compresses and reconstructs each frame conditioned on its predecessor in an autoregressive manner, allowing flexible processing of videos with arbitrary lengths. ARVAE introduces a temporal-spatial decoupled representation that combines downsampled flow field for temporal coherence with spatial relative compensation for newly emerged content, achieving high compression efficiency without information loss. Specifically, the encoder compresses the current and previous frames into the temporal motion and spatial supplement, while the decoder reconstructs the original frame from the latent representations given the preceding frame. A multi-stage training strategy is employed to progressively optimize the model. Extensive experiments demonstrate that ARVAE achieves superior reconstruction quality with extremely lightweight models and small-scale training data. Moreover, evaluations on video generation tasks highlight its strong potential for downstream applications.
Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
Mar 27, 2025
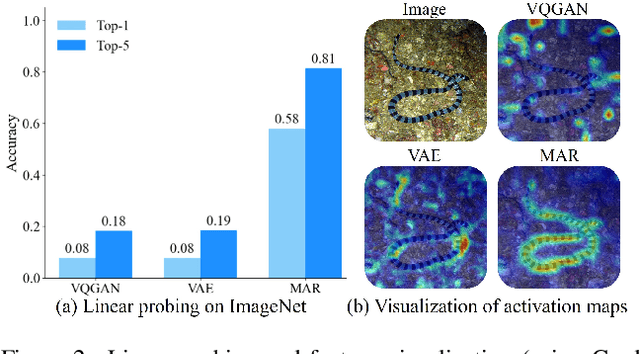
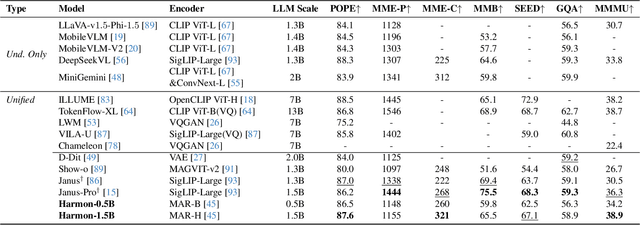
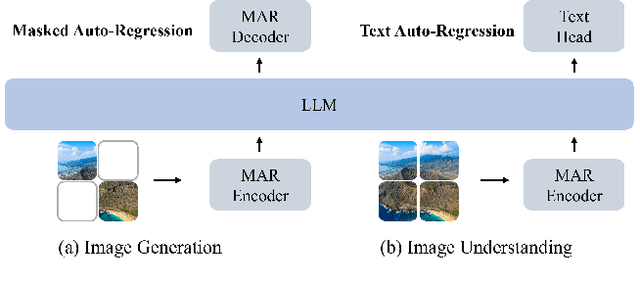
Unifying visual understanding and generation within a single multimodal framework remains a significant challenge, as the two inherently heterogeneous tasks require representations at different levels of granularity. Current approaches that utilize vector quantization (VQ) or variational autoencoders (VAE) for unified visual representation prioritize intrinsic imagery features over semantics, compromising understanding performance. In this work, we take inspiration from masked image modelling (MIM) that learns rich semantics via a mask-and-reconstruct pre-training and its successful extension to masked autoregressive (MAR) image generation. A preliminary study on the MAR encoder's representation reveals exceptional linear probing accuracy and precise feature response to visual concepts, which indicates MAR's potential for visual understanding tasks beyond its original generation role. Based on these insights, we present \emph{Harmon}, a unified autoregressive framework that harmonizes understanding and generation tasks with a shared MAR encoder. Through a three-stage training procedure that progressively optimizes understanding and generation capabilities, Harmon achieves state-of-the-art image generation results on the GenEval, MJHQ30K and WISE benchmarks while matching the performance of methods with dedicated semantic encoders (e.g., Janus) on image understanding benchmarks. Our code and models will be available at https://github.com/wusize/Harmon.
KptLLM: Unveiling the Power of Large Language Model for Keypoint Comprehension
Nov 04, 2024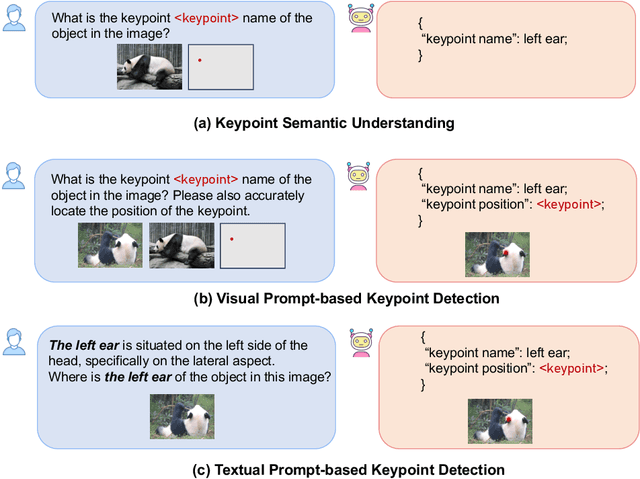



Recent advancements in Multimodal Large Language Models (MLLMs) have greatly improved their abilities in image understanding. However, these models often struggle with grasping pixel-level semantic details, e.g., the keypoints of an object. To bridge this gap, we introduce the novel challenge of Semantic Keypoint Comprehension, which aims to comprehend keypoints across different task scenarios, including keypoint semantic understanding, visual prompt-based keypoint detection, and textual prompt-based keypoint detection. Moreover, we introduce KptLLM, a unified multimodal model that utilizes an identify-then-detect strategy to effectively address these challenges. KptLLM underscores the initial discernment of semantics in keypoints, followed by the precise determination of their positions through a chain-of-thought process. With several carefully designed modules, KptLLM adeptly handles various modality inputs, facilitating the interpretation of both semantic contents and keypoint locations. Our extensive experiments demonstrate KptLLM's superiority in various keypoint detection benchmarks and its unique semantic capabilities in interpreting keypoints.
TCFormer: Visual Recognition via Token Clustering Transformer
Jul 16, 2024
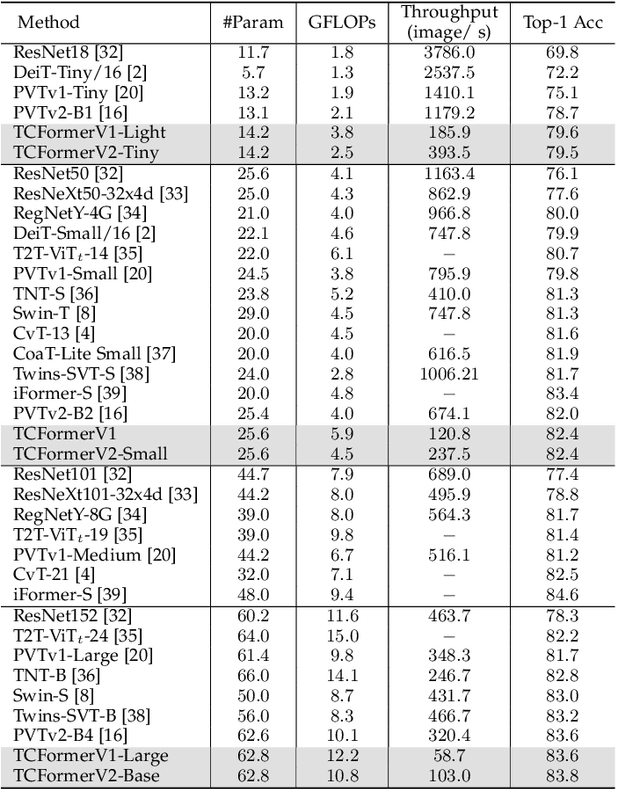
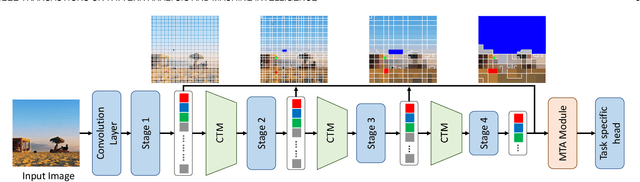
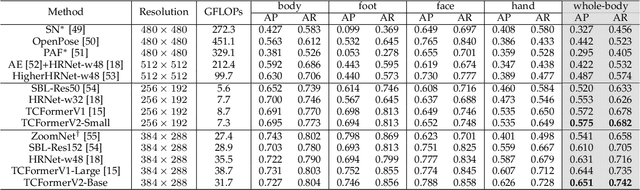
Transformers are widely used in computer vision areas and have achieved remarkable success. Most state-of-the-art approaches split images into regular grids and represent each grid region with a vision token. However, fixed token distribution disregards the semantic meaning of different image regions, resulting in sub-optimal performance. To address this issue, we propose the Token Clustering Transformer (TCFormer), which generates dynamic vision tokens based on semantic meaning. Our dynamic tokens possess two crucial characteristics: (1) Representing image regions with similar semantic meanings using the same vision token, even if those regions are not adjacent, and (2) concentrating on regions with valuable details and represent them using fine tokens. Through extensive experimentation across various applications, including image classification, human pose estimation, semantic segmentation, and object detection, we demonstrate the effectiveness of our TCFormer. The code and models for this work are available at https://github.com/zengwang430521/TCFormer.
F-LMM: Grounding Frozen Large Multimodal Models
Jun 09, 2024



Endowing Large Multimodal Models (LMMs) with visual grounding capability can significantly enhance AIs' understanding of the visual world and their interaction with humans. However, existing methods typically fine-tune the parameters of LMMs to learn additional segmentation tokens and overfit grounding and segmentation datasets. Such a design would inevitably cause a catastrophic diminution in the indispensable conversational capability of general AI assistants. In this paper, we comprehensively evaluate state-of-the-art grounding LMMs across a suite of multimodal question-answering benchmarks, observing pronounced performance drops that indicate vanishing general knowledge comprehension and weakened instruction following ability. To address this issue, we present F-LMM -- grounding frozen off-the-shelf LMMs in human-AI conversations -- a straightforward yet effective design based on the fact that word-pixel correspondences conducive to visual grounding inherently exist in the attention weights of well-trained LMMs. Using only a few trainable CNN layers, we can translate word-pixel attention weights to mask logits, which a SAM-based mask refiner can further optimise. Our F-LMM neither learns special segmentation tokens nor utilises high-quality grounded instruction-tuning data, but achieves competitive performance on referring expression segmentation and panoptic narrative grounding benchmarks while completely preserving LMMs' original conversational ability. Additionally, with instruction-following ability preserved and grounding ability obtained, our F-LMM can perform visual chain-of-thought reasoning and better resist object hallucinations.
UniFS: Universal Few-shot Instance Perception with Point Representations
Apr 30, 2024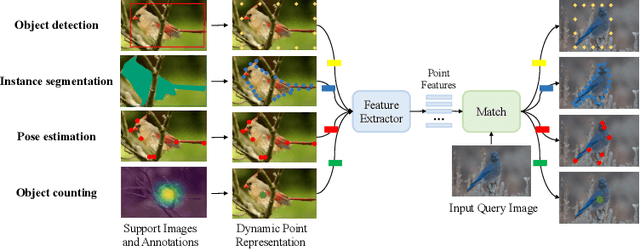
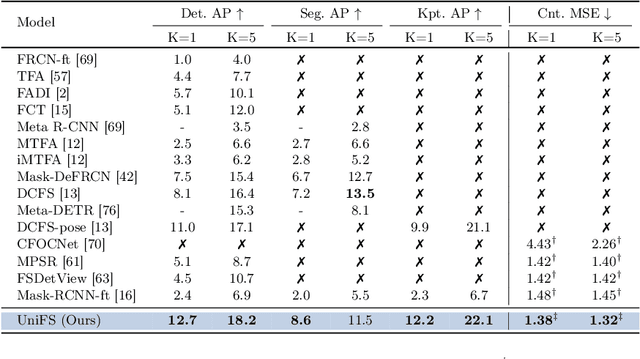
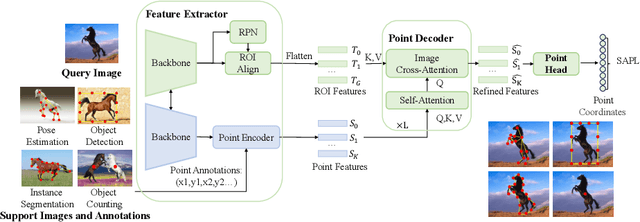
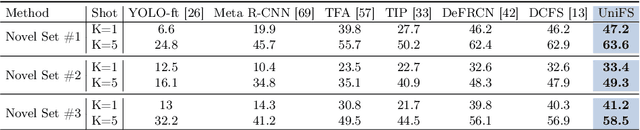
Instance perception tasks (object detection, instance segmentation, pose estimation, counting) play a key role in industrial applications of visual models. As supervised learning methods suffer from high labeling cost, few-shot learning methods which effectively learn from a limited number of labeled examples are desired. Existing few-shot learning methods primarily focus on a restricted set of tasks, presumably due to the challenges involved in designing a generic model capable of representing diverse tasks in a unified manner. In this paper, we propose UniFS, a universal few-shot instance perception model that unifies a wide range of instance perception tasks by reformulating them into a dynamic point representation learning framework. Additionally, we propose Structure-Aware Point Learning (SAPL) to exploit the higher-order structural relationship among points to further enhance representation learning. Our approach makes minimal assumptions about the tasks, yet it achieves competitive results compared to highly specialized and well optimized specialist models. Codes will be released soon.
CLIM: Contrastive Language-Image Mosaic for Region Representation
Dec 19, 2023Detecting objects accurately from a large or open vocabulary necessitates the vision-language alignment on region representations. However, learning such a region-text alignment by obtaining high-quality box annotations with text labels or descriptions is expensive and infeasible. In contrast, collecting image-text pairs is simpler but lacks precise object location information to associate regions with texts. In this paper, we propose a novel approach called Contrastive Language-Image Mosaic (CLIM), which leverages large-scale image-text pairs effectively for aligning region and text representations. CLIM combines multiple images into a mosaicked image and treats each image as a `pseudo region'. The feature of each pseudo region is extracted and trained to be similar to the corresponding text embedding while dissimilar from others by a contrastive loss, enabling the model to learn the region-text alignment without costly box annotations. As a generally applicable approach, CLIM consistently improves different open-vocabulary object detection methods that use caption supervision. Furthermore, CLIM can effectively enhance the region representation of vision-language models, thus providing stronger backbones for open-vocabulary object detectors. Our experimental results demonstrate that CLIM improves different baseline open-vocabulary object detectors by a large margin on both OV-COCO and OV-LVIS benchmarks. The code is available at https://github.com/wusize/CLIM.
Language-driven Open-Vocabulary Keypoint Detection for Animal Body and Face
Oct 10, 2023Current approaches for image-based keypoint detection on animal (including human) body and face are limited to specific keypoints and species. We address the limitation by proposing the Open-Vocabulary Keypoint Detection (OVKD) task. It aims to use text prompts to localize arbitrary keypoints of any species. To accomplish this objective, we propose Open-Vocabulary Keypoint Detection with Semantic-feature Matching (KDSM), which utilizes both vision and language models to harness the relationship between text and vision and thus achieve keypoint detection through associating text prompt with relevant keypoint features. Additionally, KDSM integrates domain distribution matrix matching and some special designs to reinforce the relationship between language and vision, thereby improving the model's generalizability and performance. Extensive experiments show that our proposed components bring significant performance improvements, and our overall method achieves impressive results in OVKD. Remarkably, our method outperforms the state-of-the-art few-shot keypoint detection methods using a zero-shot fashion. We will make the source code publicly accessible.
CLIPSelf: Vision Transformer Distills Itself for Open-Vocabulary Dense Prediction
Oct 02, 2023



Open-vocabulary dense prediction tasks including object detection and image segmentation have been advanced by the success of Contrastive Language-Image Pre-training (CLIP). CLIP models, particularly those incorporating vision transformers (ViTs), have exhibited remarkable generalization ability in zero-shot image classification. However, when transferring the vision-language alignment of CLIP from global image representation to local region representation for the open-vocabulary dense prediction tasks, CLIP ViTs suffer from the domain shift from full images to local image regions. In this paper, we embark on an in-depth analysis of the region-language alignment in CLIP models, which is essential for downstream open-vocabulary dense prediction tasks. Subsequently, we propose an approach named CLIPSelf, which adapts the image-level recognition ability of CLIP ViT to local image regions without needing any region-text pairs. CLIPSelf empowers ViTs to distill itself by aligning a region representation extracted from its dense feature map with the image-level representation of the corresponding image crop. With the enhanced CLIP ViTs, we achieve new state-of-the-art performance on open-vocabulary object detection, semantic segmentation, and panoptic segmentation across various benchmarks. Models and code will be available at https://github.com/wusize/CLIPSelf.
GKGNet: Group K-Nearest Neighbor based Graph Convolutional Network for Multi-Label Image Recognition
Aug 28, 2023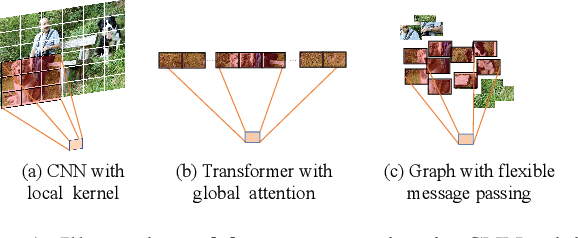

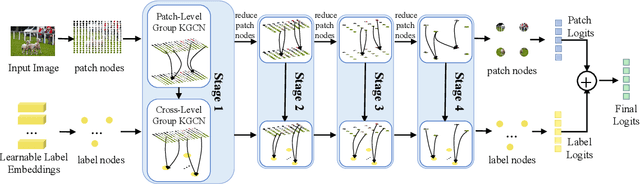

Multi-Label Image Recognition (MLIR) is a challenging task that aims to predict multiple object labels in a single image while modeling the complex relationships between labels and image regions. Although convolutional neural networks and vision transformers have succeeded in processing images as regular grids of pixels or patches, these representations are sub-optimal for capturing irregular and discontinuous regions of interest. In this work, we present the first fully graph convolutional model, Group K-nearest neighbor based Graph convolutional Network (GKGNet), which models the connections between semantic label embeddings and image patches in a flexible and unified graph structure. To address the scale variance of different objects and to capture information from multiple perspectives, we propose the Group KGCN module for dynamic graph construction and message passing. Our experiments demonstrate that GKGNet achieves state-of-the-art performance with significantly lower computational costs on the challenging multi-label datasets, \ie MS-COCO and VOC2007 datasets. We will release the code and models to facilitate future research in this area.