 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudit After Segmentation: Reference-Free Mask Quality Assessment for Language-Referred Audio-Visual Segmentation
Feb 03, 2026Language-referred audio-visual segmentation (Ref-AVS) aims to segment target objects described by natural language by jointly reasoning over video, audio, and text. Beyond generating segmentation masks, providing rich and interpretable diagnoses of mask quality remains largely underexplored. In this work, we introduce Mask Quality Assessment in the Ref-AVS context (MQA-RefAVS), a new task that evaluates the quality of candidate segmentation masks without relying on ground-truth annotations as references at inference time. Given audio-visual-language inputs and each provided segmentation mask, the task requires estimating its IoU with the unobserved ground truth, identifying the corresponding error type, and recommending an actionable quality-control decision. To support this task, we construct MQ-RAVSBench, a benchmark featuring diverse and representative mask error modes that span both geometric and semantic issues. We further propose MQ-Auditor, a multimodal large language model (MLLM)-based auditor that explicitly reasons over multimodal cues and mask information to produce quantitative and qualitative mask quality assessments. Extensive experiments demonstrate that MQ-Auditor outperforms strong open-source and commercial MLLMs and can be integrated with existing Ref-AVS systems to detect segmentation failures and support downstream segmentation improvement. Data and codes will be released at https://github.com/jasongief/MQA-RefAVS.
SAM3-DMS: Decoupled Memory Selection for Multi-target Video Segmentation of SAM3
Jan 14, 2026Segment Anything 3 (SAM3) has established a powerful foundation that robustly detects, segments, and tracks specified targets in videos. However, in its original implementation, its group-level collective memory selection is suboptimal for complex multi-object scenarios, as it employs a synchronized decision across all concurrent targets conditioned on their average performance, often overlooking individual reliability. To this end, we propose SAM3-DMS, a training-free decoupled strategy that utilizes fine-grained memory selection on individual objects. Experiments demonstrate that our approach achieves robust identity preservation and tracking stability. Notably, our advantage becomes more pronounced with increased target density, establishing a solid foundation for simultaneous multi-target video segmentation in the wild.
MeViS: A Multi-Modal Dataset for Referring Motion Expression Video Segmentation
Dec 11, 2025



This paper proposes a large-scale multi-modal dataset for referring motion expression video segmentation, focusing on segmenting and tracking target objects in videos based on language description of objects' motions. Existing referring video segmentation datasets often focus on salient objects and use language expressions rich in static attributes, potentially allowing the target object to be identified in a single frame. Such datasets underemphasize the role of motion in both videos and languages. To explore the feasibility of using motion expressions and motion reasoning clues for pixel-level video understanding, we introduce MeViS, a dataset containing 33,072 human-annotated motion expressions in both text and audio, covering 8,171 objects in 2,006 videos of complex scenarios. We benchmark 15 existing methods across 4 tasks supported by MeViS, including 6 referring video object segmentation (RVOS) methods, 3 audio-guided video object segmentation (AVOS) methods, 2 referring multi-object tracking (RMOT) methods, and 4 video captioning methods for the newly introduced referring motion expression generation (RMEG) task. The results demonstrate weaknesses and limitations of existing methods in addressing motion expression-guided video understanding. We further analyze the challenges and propose an approach LMPM++ for RVOS/AVOS/RMOT that achieves new state-of-the-art results. Our dataset provides a platform that facilitates the development of motion expression-guided video understanding algorithms in complex video scenes. The proposed MeViS dataset and the method's source code are publicly available at https://henghuiding.com/MeViS/
* IEEE TPAMI, Project Page: https://henghuiding.com/MeViS/
Segment Anything Across Shots: A Method and Benchmark
Nov 17, 2025This work focuses on multi-shot semi-supervised video object segmentation (MVOS), which aims at segmenting the target object indicated by an initial mask throughout a video with multiple shots. The existing VOS methods mainly focus on single-shot videos and struggle with shot discontinuities, thereby limiting their real-world applicability. We propose a transition mimicking data augmentation strategy (TMA) which enables cross-shot generalization with single-shot data to alleviate the severe annotated multi-shot data sparsity, and the Segment Anything Across Shots (SAAS) model, which can detect and comprehend shot transitions effectively. To support evaluation and future study in MVOS, we introduce Cut-VOS, a new MVOS benchmark with dense mask annotations, diverse object categories, and high-frequency transitions. Extensive experiments on YouMVOS and Cut-VOS demonstrate that the proposed SAAS achieves state-of-the-art performance by effectively mimicking, understanding, and segmenting across complex transitions. The code and datasets are released at https://henghuiding.com/SAAS/.
Free-Form Scene Editor: Enabling Multi-Round Object Manipulation like in a 3D Engine
Nov 17, 2025Recent advances in text-to-image (T2I) diffusion models have significantly improved semantic image editing, yet most methods fall short in performing 3D-aware object manipulation. In this work, we present FFSE, a 3D-aware autoregressive framework designed to enable intuitive, physically-consistent object editing directly on real-world images. Unlike previous approaches that either operate in image space or require slow and error-prone 3D reconstruction, FFSE models editing as a sequence of learned 3D transformations, allowing users to perform arbitrary manipulations, such as translation, scaling, and rotation, while preserving realistic background effects (e.g., shadows, reflections) and maintaining global scene consistency across multiple editing rounds. To support learning of multi-round 3D-aware object manipulation, we introduce 3DObjectEditor, a hybrid dataset constructed from simulated editing sequences across diverse objects and scenes, enabling effective training under multi-round and dynamic conditions. Extensive experiments show that the proposed FFSE significantly outperforms existing methods in both single-round and multi-round 3D-aware editing scenarios.
Hierarchical Visual Prompt Learning for Continual Video Instance Segmentation
Aug 12, 2025
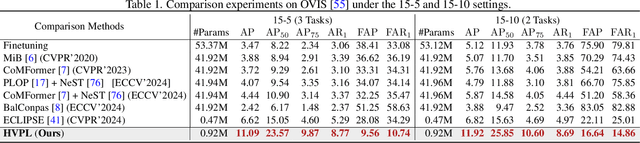
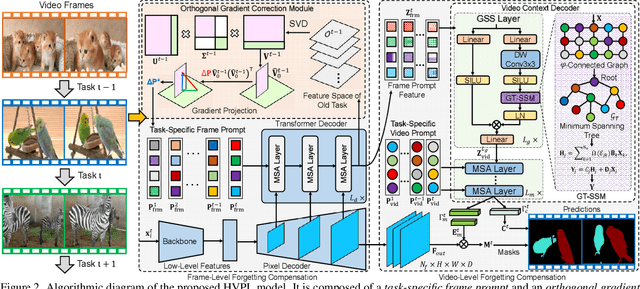
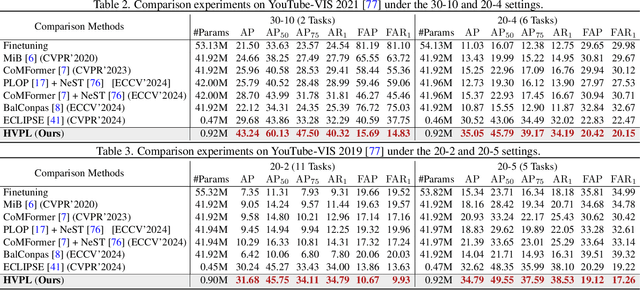
Video instance segmentation (VIS) has gained significant attention for its capability in tracking and segmenting object instances across video frames. However, most of the existing VIS approaches unrealistically assume that the categories of object instances remain fixed over time. Moreover, they experience catastrophic forgetting of old classes when required to continuously learn object instances belonging to new categories. To resolve these challenges, we develop a novel Hierarchical Visual Prompt Learning (HVPL) model that overcomes catastrophic forgetting of previous categories from both frame-level and video-level perspectives. Specifically, to mitigate forgetting at the frame level, we devise a task-specific frame prompt and an orthogonal gradient correction (OGC) module. The OGC module helps the frame prompt encode task-specific global instance information for new classes in each individual frame by projecting its gradients onto the orthogonal feature space of old classes. Furthermore, to address forgetting at the video level, we design a task-specific video prompt and a video context decoder. This decoder first embeds structural inter-class relationships across frames into the frame prompt features, and then propagates task-specific global video contexts from the frame prompt features to the video prompt. Through rigorous comparisons, our HVPL model proves to be more effective than baseline approaches. The code is available at https://github.com/JiahuaDong/HVPL.
ReferSplat: Referring Segmentation in 3D Gaussian Splatting
Aug 11, 2025We introduce Referring 3D Gaussian Splatting Segmentation (R3DGS), a new task that aims to segment target objects in a 3D Gaussian scene based on natural language descriptions, which often contain spatial relationships or object attributes. This task requires the model to identify newly described objects that may be occluded or not directly visible in a novel view, posing a significant challenge for 3D multi-modal understanding. Developing this capability is crucial for advancing embodied AI. To support research in this area, we construct the first R3DGS dataset, Ref-LERF. Our analysis reveals that 3D multi-modal understanding and spatial relationship modeling are key challenges for R3DGS. To address these challenges, we propose ReferSplat, a framework that explicitly models 3D Gaussian points with natural language expressions in a spatially aware paradigm. ReferSplat achieves state-of-the-art performance on both the newly proposed R3DGS task and 3D open-vocabulary segmentation benchmarks. Dataset and code are available at https://github.com/heshuting555/ReferSplat.
MOSEv2: A More Challenging Dataset for Video Object Segmentation in Complex Scenes
Aug 07, 2025Video object segmentation (VOS) aims to segment specified target objects throughout a video. Although state-of-the-art methods have achieved impressive performance (e.g., 90+% J&F) on existing benchmarks such as DAVIS and YouTube-VOS, these datasets primarily contain salient, dominant, and isolated objects, limiting their generalization to real-world scenarios. To advance VOS toward more realistic environments, coMplex video Object SEgmentation (MOSEv1) was introduced to facilitate VOS research in complex scenes. Building on the strengths and limitations of MOSEv1, we present MOSEv2, a significantly more challenging dataset designed to further advance VOS methods under real-world conditions. MOSEv2 consists of 5,024 videos and over 701,976 high-quality masks for 10,074 objects across 200 categories. Compared to its predecessor, MOSEv2 introduces significantly greater scene complexity, including more frequent object disappearance and reappearance, severe occlusions and crowding, smaller objects, as well as a range of new challenges such as adverse weather (e.g., rain, snow, fog), low-light scenes (e.g., nighttime, underwater), multi-shot sequences, camouflaged objects, non-physical targets (e.g., shadows, reflections), scenarios requiring external knowledge, etc. We benchmark 20 representative VOS methods under 5 different settings and observe consistent performance drops. For example, SAM2 drops from 76.4% on MOSEv1 to only 50.9% on MOSEv2. We further evaluate 9 video object tracking methods and find similar declines, demonstrating that MOSEv2 presents challenges across tasks. These results highlight that despite high accuracy on existing datasets, current VOS methods still struggle under real-world complexities. MOSEv2 is publicly available at https://MOSE.video.
Multimodal Referring Segmentation: A Survey
Aug 01, 2025Multimodal referring segmentation aims to segment target objects in visual scenes, such as images, videos, and 3D scenes, based on referring expressions in text or audio format. This task plays a crucial role in practical applications requiring accurate object perception based on user instructions. Over the past decade, it has gained significant attention in the multimodal community, driven by advances in convolutional neural networks, transformers, and large language models, all of which have substantially improved multimodal perception capabilities. This paper provides a comprehensive survey of multimodal referring segmentation. We begin by introducing this field's background, including problem definitions and commonly used datasets. Next, we summarize a unified meta architecture for referring segmentation and review representative methods across three primary visual scenes, including images, videos, and 3D scenes. We further discuss Generalized Referring Expression (GREx) methods to address the challenges of real-world complexity, along with related tasks and practical applications. Extensive performance comparisons on standard benchmarks are also provided. We continually track related works at https://github.com/henghuiding/Awesome-Multimodal-Referring-Segmentation.
Towards Omnimodal Expressions and Reasoning in Referring Audio-Visual Segmentation
Jul 30, 2025Referring audio-visual segmentation (RAVS) has recently seen significant advancements, yet challenges remain in integrating multimodal information and deeply understanding and reasoning about audiovisual content. To extend the boundaries of RAVS and facilitate future research in this field, we propose Omnimodal Referring Audio-Visual Segmentation (OmniAVS), a new dataset containing 2,098 videos and 59,458 multimodal referring expressions. OmniAVS stands out with three key innovations: (1) 8 types of multimodal expressions that flexibly combine text, speech, sound, and visual cues; (2) an emphasis on understanding audio content beyond just detecting their presence; and (3) the inclusion of complex reasoning and world knowledge in expressions. Furthermore, we introduce Omnimodal Instructed Segmentation Assistant (OISA), to address the challenges of multimodal reasoning and fine-grained understanding of audiovisual content in OmniAVS. OISA uses MLLM to comprehend complex cues and perform reasoning-based segmentation. Extensive experiments show that OISA outperforms existing methods on OmniAVS and achieves competitive results on other related tasks.