 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVC 2026: the Second Multimodal Deception Detection Challenge and the First Domain Generalized Remote Physiological Measurement Challenge
Apr 07, 2026Subtle visual signals, although difficult to perceive with the naked eye, contain important information that can reveal hidden patterns in visual data. These signals play a key role in many applications, including biometric security, multimedia forensics, medical diagnosis, industrial inspection, and affective computing. With the rapid development of computer vision and representation learning techniques, detecting and interpreting such subtle signals has become an emerging research direction. However, existing studies often focus on specific tasks or modalities, and models still face challenges in robustness, representation ability, and generalization when handling subtle and weak signals in real-world environments. To promote research in this area, we organize the Subtle visual Challenge, which aims to learn robust representations for subtle visual signals. The challenge includes two tasks: cross-domain multimodal deception detection and remote photoplethysmography (rPPG) estimation. We hope that this challenge will encourage the development of more robust and generalizable models for subtle visual understanding, and further advance research in computer vision and multimodal learning. A total of 22 teams submitted their final results to this workshop competition, and the corresponding baseline models have been released on the \href{https://sites.google.com/view/svc-cvpr26}{MMDD2026 platform}\footnote{https://sites.google.com/view/svc-cvpr26}
StegaFFD: Privacy-Preserving Face Forgery Detection via Fine-Grained Steganographic Domain Lifting
Mar 03, 2026Most existing Face Forgery Detection (FFD) models assume access to raw face images. In practice, under a client-server framework, private facial data may be intercepted during transmission or leaked by untrusted servers. Previous privacy protection approaches, such as anonymization, encryption, or distortion, partly mitigate leakage but often introduce severe semantic distortion, making images appear obviously protected. This alerts attackers, provoking more aggressive strategies and turning the process into a cat-and-mouse game. Moreover, these methods heavily manipulate image contents, introducing degradation or artifacts that may confuse FFD models, which rely on extremely subtle forgery traces. Inspired by advances in image steganography, which enable high-fidelity hiding and recovery, we propose a Stega}nography-based Face Forgery Detection framework (StegaFFD) to protect privacy without raising suspicion. StegaFFD hides facial images within natural cover images and directly conducts forgery detection in the steganographic domain. However, the hidden forgery-specific features are extremely subtle and interfered with by cover semantics, posing significant challenges. To address this, we propose Low-Frequency-Aware Decomposition (LFAD) and Spatial-Frequency Differential Attention (SFDA), which suppress interference from low-frequency cover semantics and enhance hidden facial feature perception. Furthermore, we introduce Steganographic Domain Alignment (SDA) to align the representations of hidden faces with those of their raw counterparts, enhancing the model's ability to perceive subtle facial cues in the steganographic domain. Extensive experiments on seven FFD datasets demonstrate that StegaFFD achieves strong imperceptibility, avoids raising attackers' suspicion, and better preserves FFD accuracy compared to existing facial privacy protection methods.
Multimodal Mixture-of-Experts with Retrieval Augmentation for Protein Active Site Identification
Mar 02, 2026Accurate identification of protein active sites at the residue level is crucial for understanding protein function and advancing drug discovery. However, current methods face two critical challenges: vulnerability in single-instance prediction due to sparse training data, and inadequate modality reliability estimation that leads to performance degradation when unreliable modalities dominate fusion processes. To address these challenges, we introduce Multimodal Mixture-of-Experts with Retrieval Augmentation (MERA), the first retrieval-augmented framework for protein active site identification. MERA employs hierarchical multi-expert retrieval that dynamically aggregates contextual information from chain, sequence, and active-site perspectives through residue-level mixture-of-experts gating. To prevent modality degradation, we propose a reliability-aware fusion strategy based on Dempster-Shafer evidence theory that quantifies modality trustworthiness through belief mass functions and learnable discounting coefficients, enabling principled multimodal integration. Extensive experiments on ProTAD-Gen and TS125 datasets demonstrate that MERA achieves state-of-the-art performance, with 90% AUPRC on active site prediction and significant gains on peptide-binding site identification, validating the effectiveness of retrieval-augmented multi-expert modeling and reliability-guided fusion.
Time Is All It Takes: Spike-Retiming Attacks on Event-Driven Spiking Neural Networks
Feb 03, 2026Spiking neural networks (SNNs) compute with discrete spikes and exploit temporal structure, yet most adversarial attacks change intensities or event counts instead of timing. We study a timing-only adversary that retimes existing spikes while preserving spike counts and amplitudes in event-driven SNNs, thus remaining rate-preserving. We formalize a capacity-1 spike-retiming threat model with a unified trio of budgets: per-spike jitter $\mathcal{B}_{\infty}$, total delay $\mathcal{B}_{1}$, and tamper count $\mathcal{B}_{0}$. Feasible adversarial examples must satisfy timeline consistency and non-overlap, which makes the search space discrete and constrained. To optimize such retimings at scale, we use projected-in-the-loop (PIL) optimization: shift-probability logits yield a differentiable soft retiming for backpropagation, and a strict projection in the forward pass produces a feasible discrete schedule that satisfies capacity-1, non-overlap, and the chosen budget at every step. The objective maximizes task loss on the projected input and adds a capacity regularizer together with budget-aware penalties, which stabilizes gradients and aligns optimization with evaluation. Across event-driven benchmarks (CIFAR10-DVS, DVS-Gesture, N-MNIST) and diverse SNN architectures, we evaluate under binary and integer event grids and a range of retiming budgets, and also test models trained with timing-aware adversarial training designed to counter timing-only attacks. For example, on DVS-Gesture the attack attains high success (over $90\%$) while touching fewer than $2\%$ of spikes under $\mathcal{B}_{0}$. Taken together, our results show that spike retiming is a practical and stealthy attack surface that current defenses struggle to counter, providing a clear reference for temporal robustness in event-driven SNNs. Code is available at https://github.com/yuyi-sd/Spike-Retiming-Attacks.
StegaVAR: Privacy-Preserving Video Action Recognition via Steganographic Domain Analysis
Dec 14, 2025



Despite the rapid progress of deep learning in video action recognition (VAR) in recent years, privacy leakage in videos remains a critical concern. Current state-of-the-art privacy-preserving methods often rely on anonymization. These methods suffer from (1) low concealment, where producing visually distorted videos that attract attackers' attention during transmission, and (2) spatiotemporal disruption, where degrading essential spatiotemporal features for accurate VAR. To address these issues, we propose StegaVAR, a novel framework that embeds action videos into ordinary cover videos and directly performs VAR in the steganographic domain for the first time. Throughout both data transmission and action analysis, the spatiotemporal information of hidden secret video remains complete, while the natural appearance of cover videos ensures the concealment of transmission. Considering the difficulty of steganographic domain analysis, we propose Secret Spatio-Temporal Promotion (STeP) and Cross-Band Difference Attention (CroDA) for analysis within the steganographic domain. STeP uses the secret video to guide spatiotemporal feature extraction in the steganographic domain during training. CroDA suppresses cover interference by capturing cross-band semantic differences. Experiments demonstrate that StegaVAR achieves superior VAR and privacy-preserving performance on widely used datasets. Moreover, our framework is effective for multiple steganographic models.
Learning Representation and Synergy Invariances: A Povable Framework for Generalized Multimodal Face Anti-Spoofing
Nov 18, 2025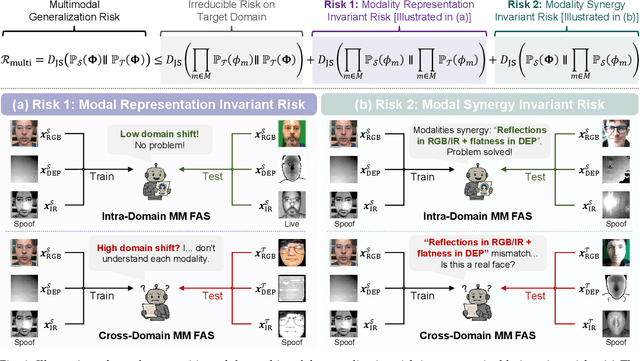

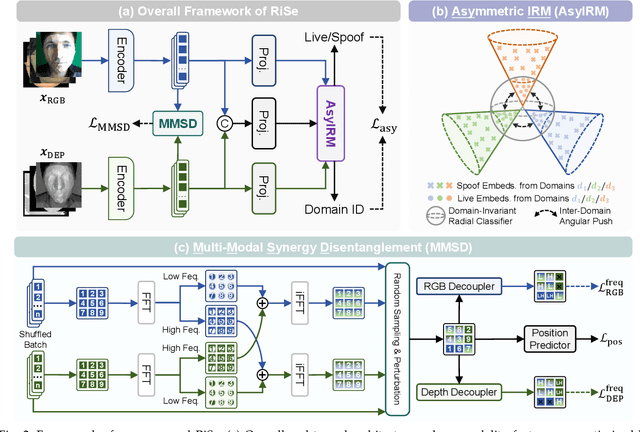
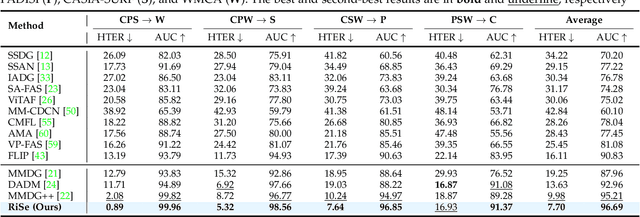
Multimodal Face Anti-Spoofing (FAS) methods, which integrate multiple visual modalities, often suffer even more severe performance degradation than unimodal FAS when deployed in unseen domains. This is mainly due to two overlooked risks that affect cross-domain multimodal generalization. The first is the modal representation invariant risk, i.e., whether representations remain generalizable under domain shift. We theoretically show that the inherent class asymmetry in FAS (diverse spoofs vs. compact reals) enlarges the upper bound of generalization error, and this effect is further amplified in multimodal settings. The second is the modal synergy invariant risk, where models overfit to domain-specific inter-modal correlations. Such spurious synergy cannot generalize to unseen attacks in target domains, leading to performance drops. To solve these issues, we propose a provable framework, namely Multimodal Representation and Synergy Invariance Learning (RiSe). For representation risk, RiSe introduces Asymmetric Invariant Risk Minimization (AsyIRM), which learns an invariant spherical decision boundary in radial space to fit asymmetric distributions, while preserving domain cues in angular space. For synergy risk, RiSe employs Multimodal Synergy Disentanglement (MMSD), a self-supervised task enhancing intrinsic, generalizable modal features via cross-sample mixing and disentanglement. Theoretical analysis and experiments verify RiSe, which achieves state-of-the-art cross-domain performance.
SVC 2025: the First Multimodal Deception Detection Challenge
Aug 06, 2025Deception detection is a critical task in real-world applications such as security screening, fraud prevention, and credibility assessment. While deep learning methods have shown promise in surpassing human-level performance, their effectiveness often depends on the availability of high-quality and diverse deception samples. Existing research predominantly focuses on single-domain scenarios, overlooking the significant performance degradation caused by domain shifts. To address this gap, we present the SVC 2025 Multimodal Deception Detection Challenge, a new benchmark designed to evaluate cross-domain generalization in audio-visual deception detection. Participants are required to develop models that not only perform well within individual domains but also generalize across multiple heterogeneous datasets. By leveraging multimodal data, including audio, video, and text, this challenge encourages the design of models capable of capturing subtle and implicit deceptive cues. Through this benchmark, we aim to foster the development of more adaptable, explainable, and practically deployable deception detection systems, advancing the broader field of multimodal learning. By the conclusion of the workshop competition, a total of 21 teams had submitted their final results. https://sites.google.com/view/svc-mm25 for more information.
FaceShield: Explainable Face Anti-Spoofing with Multimodal Large Language Models
May 14, 2025
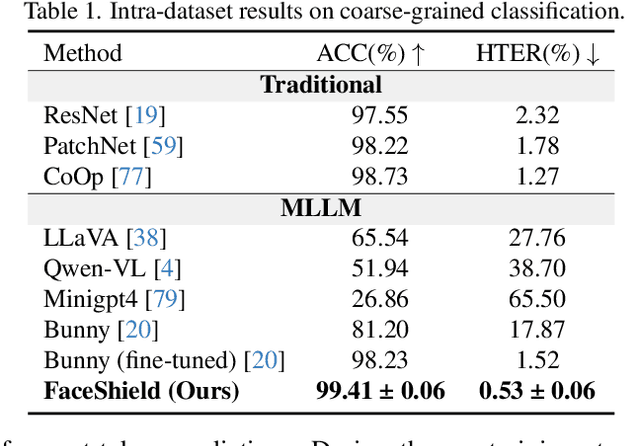
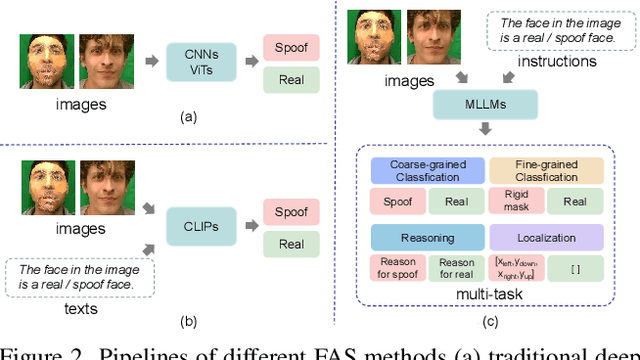
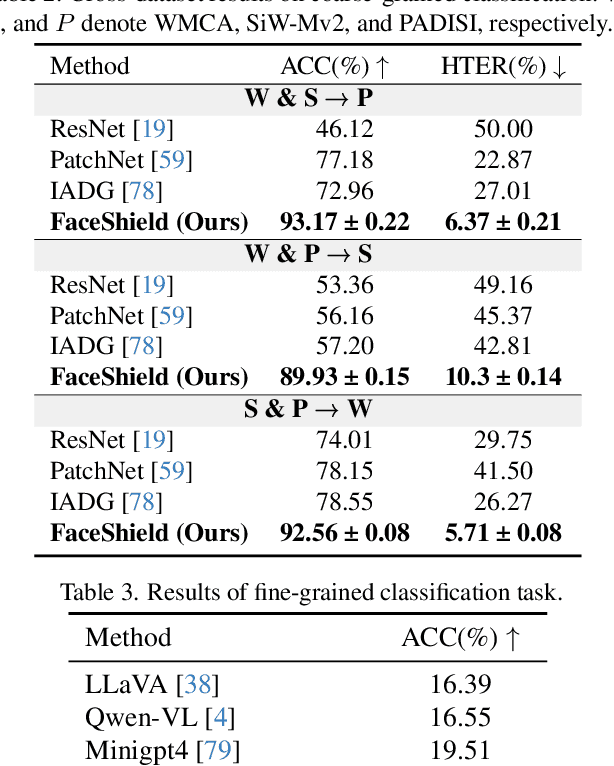
Face anti-spoofing (FAS) is crucial for protecting facial recognition systems from presentation attacks. Previous methods approached this task as a classification problem, lacking interpretability and reasoning behind the predicted results. Recently, multimodal large language models (MLLMs) have shown strong capabilities in perception, reasoning, and decision-making in visual tasks. However, there is currently no universal and comprehensive MLLM and dataset specifically designed for FAS task. To address this gap, we propose FaceShield, a MLLM for FAS, along with the corresponding pre-training and supervised fine-tuning (SFT) datasets, FaceShield-pre10K and FaceShield-sft45K. FaceShield is capable of determining the authenticity of faces, identifying types of spoofing attacks, providing reasoning for its judgments, and detecting attack areas. Specifically, we employ spoof-aware vision perception (SAVP) that incorporates both the original image and auxiliary information based on prior knowledge. We then use an prompt-guided vision token masking (PVTM) strategy to random mask vision tokens, thereby improving the model's generalization ability. We conducted extensive experiments on three benchmark datasets, demonstrating that FaceShield significantly outperforms previous deep learning models and general MLLMs on four FAS tasks, i.e., coarse-grained classification, fine-grained classification, reasoning, and attack localization. Our instruction datasets, protocols, and codes will be released soon.
Denoising and Alignment: Rethinking Domain Generalization for Multimodal Face Anti-Spoofing
May 14, 2025Face Anti-Spoofing (FAS) is essential for the security of facial recognition systems in diverse scenarios such as payment processing and surveillance. Current multimodal FAS methods often struggle with effective generalization, mainly due to modality-specific biases and domain shifts. To address these challenges, we introduce the \textbf{M}ulti\textbf{m}odal \textbf{D}enoising and \textbf{A}lignment (\textbf{MMDA}) framework. By leveraging the zero-shot generalization capability of CLIP, the MMDA framework effectively suppresses noise in multimodal data through denoising and alignment mechanisms, thereby significantly enhancing the generalization performance of cross-modal alignment. The \textbf{M}odality-\textbf{D}omain Joint \textbf{D}ifferential \textbf{A}ttention (\textbf{MD2A}) module in MMDA concurrently mitigates the impacts of domain and modality noise by refining the attention mechanism based on extracted common noise features. Furthermore, the \textbf{R}epresentation \textbf{S}pace \textbf{S}oft (\textbf{RS2}) Alignment strategy utilizes the pre-trained CLIP model to align multi-domain multimodal data into a generalized representation space in a flexible manner, preserving intricate representations and enhancing the model's adaptability to various unseen conditions. We also design a \textbf{U}-shaped \textbf{D}ual \textbf{S}pace \textbf{A}daptation (\textbf{U-DSA}) module to enhance the adaptability of representations while maintaining generalization performance. These improvements not only enhance the framework's generalization capabilities but also boost its ability to represent complex representations. Our experimental results on four benchmark datasets under different evaluation protocols demonstrate that the MMDA framework outperforms existing state-of-the-art methods in terms of cross-domain generalization and multimodal detection accuracy. The code will be released soon.
Towards Model Resistant to Transferable Adversarial Examples via Trigger Activation
Apr 20, 2025Adversarial examples, characterized by imperceptible perturbations, pose significant threats to deep neural networks by misleading their predictions. A critical aspect of these examples is their transferability, allowing them to deceive {unseen} models in black-box scenarios. Despite the widespread exploration of defense methods, including those on transferability, they show limitations: inefficient deployment, ineffective defense, and degraded performance on clean images. In this work, we introduce a novel training paradigm aimed at enhancing robustness against transferable adversarial examples (TAEs) in a more efficient and effective way. We propose a model that exhibits random guessing behavior when presented with clean data $\boldsymbol{x}$ as input, and generates accurate predictions when with triggered data $\boldsymbol{x}+\boldsymbol{\tau}$. Importantly, the trigger $\boldsymbol{\tau}$ remains constant for all data instances. We refer to these models as \textbf{models with trigger activation}. We are surprised to find that these models exhibit certain robustness against TAEs. Through the consideration of first-order gradients, we provide a theoretical analysis of this robustness. Moreover, through the joint optimization of the learnable trigger and the model, we achieve improved robustness to transferable attacks. Extensive experiments conducted across diverse datasets, evaluating a variety of attacking methods, underscore the effectiveness and superiority of our approach.