 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks against No-Reference Image Quality Assessment Models via A Scalable Trigger
Dec 10, 2024



No-Reference Image Quality Assessment (NR-IQA), responsible for assessing the quality of a single input image without using any reference, plays a critical role in evaluating and optimizing computer vision systems, e.g., low-light enhancement. Recent research indicates that NR-IQA models are susceptible to adversarial attacks, which can significantly alter predicted scores with visually imperceptible perturbations. Despite revealing vulnerabilities, these attack methods have limitations, including high computational demands, untargeted manipulation, limited practical utility in white-box scenarios, and reduced effectiveness in black-box scenarios. To address these challenges, we shift our focus to another significant threat and present a novel poisoning-based backdoor attack against NR-IQA (BAIQA), allowing the attacker to manipulate the IQA model's output to any desired target value by simply adjusting a scaling coefficient $\alpha$ for the trigger. We propose to inject the trigger in the discrete cosine transform (DCT) domain to improve the local invariance of the trigger for countering trigger diminishment in NR-IQA models due to widely adopted data augmentations. Furthermore, the universal adversarial perturbations (UAP) in the DCT space are designed as the trigger, to increase IQA model susceptibility to manipulation and improve attack effectiveness. In addition to the heuristic method for poison-label BAIQA (P-BAIQA), we explore the design of clean-label BAIQA (C-BAIQA), focusing on $\alpha$ sampling and image data refinement, driven by theoretical insights we reveal. Extensive experiments on diverse datasets and various NR-IQA models demonstrate the effectiveness of our attacks. Code will be released at https://github.com/yuyi-sd/BAIQA.
POAR: Towards Open-World Pedestrian Attribute Recognition
Mar 26, 2023



Pedestrian attribute recognition (PAR) aims to predict the attributes of a target pedestrian in a surveillance system. Existing methods address the PAR problem by training a multi-label classifier with predefined attribute classes. However, it is impossible to exhaust all pedestrian attributes in the real world. To tackle this problem, we develop a novel pedestrian open-attribute recognition (POAR) framework. Our key idea is to formulate the POAR problem as an image-text search problem. We design a Transformer-based image encoder with a masking strategy. A set of attribute tokens are introduced to focus on specific pedestrian parts (e.g., head, upper body, lower body, feet, etc.) and encode corresponding attributes into visual embeddings. Each attribute category is described as a natural language sentence and encoded by the text encoder. Then, we compute the similarity between the visual and text embeddings of attributes to find the best attribute descriptions for the input images. Different from existing methods that learn a specific classifier for each attribute category, we model the pedestrian at a part-level and explore the searching method to handle the unseen attributes. Finally, a many-to-many contrastive (MTMC) loss with masked tokens is proposed to train the network since a pedestrian image can comprise multiple attributes. Extensive experiments have been conducted on benchmark PAR datasets with an open-attribute setting. The results verified the effectiveness of the proposed POAR method, which can form a strong baseline for the POAR task.
Backdoor Attacks Against Deep Image Compression via Adaptive Frequency Trigger
Feb 28, 2023Recent deep-learning-based compression methods have achieved superior performance compared with traditional approaches. However, deep learning models have proven to be vulnerable to backdoor attacks, where some specific trigger patterns added to the input can lead to malicious behavior of the models. In this paper, we present a novel backdoor attack with multiple triggers against learned image compression models. Motivated by the widely used discrete cosine transform (DCT) in existing compression systems and standards, we propose a frequency-based trigger injection model that adds triggers in the DCT domain. In particular, we design several attack objectives for various attacking scenarios, including: 1) attacking compression quality in terms of bit-rate and reconstruction quality; 2) attacking task-driven measures, such as down-stream face recognition and semantic segmentation. Moreover, a novel simple dynamic loss is designed to balance the influence of different loss terms adaptively, which helps achieve more efficient training. Extensive experiments show that with our trained trigger injection models and simple modification of encoder parameters (of the compression model), the proposed attack can successfully inject several backdoors with corresponding triggers in a single image compression model.
Benchmarking the Robustness of Spatial-Temporal Models Against Corruptions
Oct 13, 2021
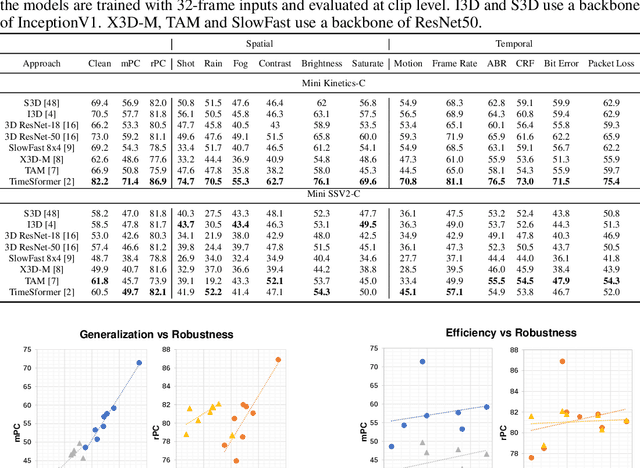
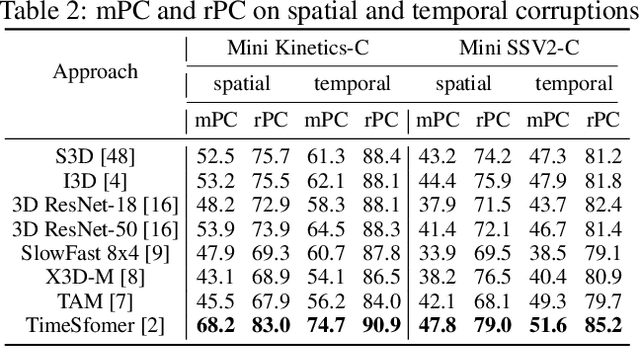
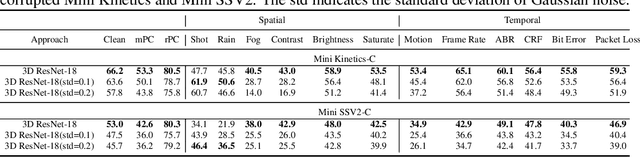
The state-of-the-art deep neural networks are vulnerable to common corruptions (e.g., input data degradations, distortions, and disturbances caused by weather changes, system error, and processing). While much progress has been made in analyzing and improving the robustness of models in image understanding, the robustness in video understanding is largely unexplored. In this paper, we establish a corruption robustness benchmark, Mini Kinetics-C and Mini SSV2-C, which considers temporal corruptions beyond spatial corruptions in images. We make the first attempt to conduct an exhaustive study on the corruption robustness of established CNN-based and Transformer-based spatial-temporal models. The study provides some guidance on robust model design and training: Transformer-based model performs better than CNN-based models on corruption robustness; the generalization ability of spatial-temporal models implies robustness against temporal corruptions; model corruption robustness (especially robustness in the temporal domain) enhances with computational cost and model capacity, which may contradict the current trend of improving the computational efficiency of models. Moreover, we find the robustness intervention for image-related tasks (e.g., training models with noise) may not work for spatial-temporal models.