 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTop-Down Viewing for Weakly Supervised Grounded Image Captioning
Jun 15, 2023Weakly supervised grounded image captioning (WSGIC) aims to generate the caption and ground (localize) predicted object words in the input image without using bounding box supervision. Recent two-stage solutions mostly apply a bottom-up pipeline: (1) first apply an off-the-shelf object detector to encode the input image into multiple region features; (2) and then leverage a soft-attention mechanism for captioning and grounding. However, object detectors are mainly designed to extract object semantics (i.e., the object category). Besides, they break down the structural images into pieces of individual proposals. As a result, the subsequent grounded captioner is often overfitted to find the correct object words, while overlooking the relation between objects (e.g., what is the person doing?), and selecting incompatible proposal regions for grounding. To address these difficulties, we propose a one-stage weakly supervised grounded captioner that directly takes the RGB image as input to perform captioning and grounding at the top-down image level. In addition, we explicitly inject a relation module into our one-stage framework to encourage the relation understanding through multi-label classification. The relation semantics aid the prediction of relation words in the caption. We observe that the relation words not only assist the grounded captioner in generating a more accurate caption but also improve the grounding performance. We validate the effectiveness of our proposed method on two challenging datasets (Flick30k Entities captioning and MSCOCO captioning). The experimental results demonstrate that our method achieves state-of-the-art grounding performance.
POAR: Towards Open-World Pedestrian Attribute Recognition
Mar 26, 2023



Pedestrian attribute recognition (PAR) aims to predict the attributes of a target pedestrian in a surveillance system. Existing methods address the PAR problem by training a multi-label classifier with predefined attribute classes. However, it is impossible to exhaust all pedestrian attributes in the real world. To tackle this problem, we develop a novel pedestrian open-attribute recognition (POAR) framework. Our key idea is to formulate the POAR problem as an image-text search problem. We design a Transformer-based image encoder with a masking strategy. A set of attribute tokens are introduced to focus on specific pedestrian parts (e.g., head, upper body, lower body, feet, etc.) and encode corresponding attributes into visual embeddings. Each attribute category is described as a natural language sentence and encoded by the text encoder. Then, we compute the similarity between the visual and text embeddings of attributes to find the best attribute descriptions for the input images. Different from existing methods that learn a specific classifier for each attribute category, we model the pedestrian at a part-level and explore the searching method to handle the unseen attributes. Finally, a many-to-many contrastive (MTMC) loss with masked tokens is proposed to train the network since a pedestrian image can comprise multiple attributes. Extensive experiments have been conducted on benchmark PAR datasets with an open-attribute setting. The results verified the effectiveness of the proposed POAR method, which can form a strong baseline for the POAR task.
VLT: Vision-Language Transformer and Query Generation for Referring Segmentation
Oct 28, 2022We propose a Vision-Language Transformer (VLT) framework for referring segmentation to facilitate deep interactions among multi-modal information and enhance the holistic understanding to vision-language features. There are different ways to understand the dynamic emphasis of a language expression, especially when interacting with the image. However, the learned queries in existing transformer works are fixed after training, which cannot cope with the randomness and huge diversity of the language expressions. To address this issue, we propose a Query Generation Module, which dynamically produces multiple sets of input-specific queries to represent the diverse comprehensions of language expression. To find the best among these diverse comprehensions, so as to generate a better mask, we propose a Query Balance Module to selectively fuse the corresponding responses of the set of queries. Furthermore, to enhance the model's ability in dealing with diverse language expressions, we consider inter-sample learning to explicitly endow the model with knowledge of understanding different language expressions to the same object. We introduce masked contrastive learning to narrow down the features of different expressions for the same target object while distinguishing the features of different objects. The proposed approach is lightweight and achieves new state-of-the-art referring segmentation results consistently on five datasets.
Vision-Language Transformer and Query Generation for Referring Segmentation
Aug 12, 2021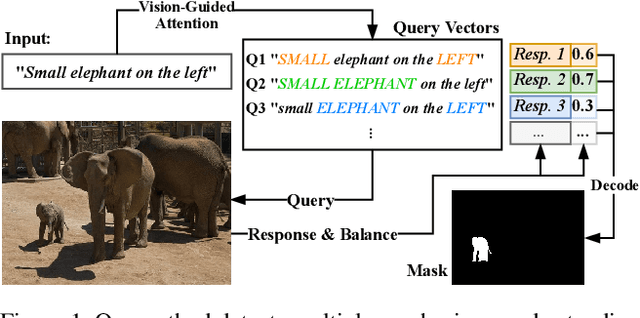
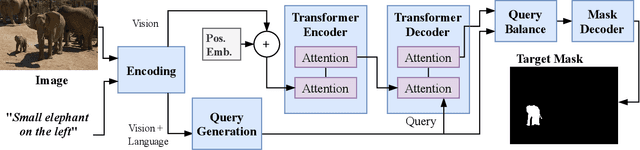
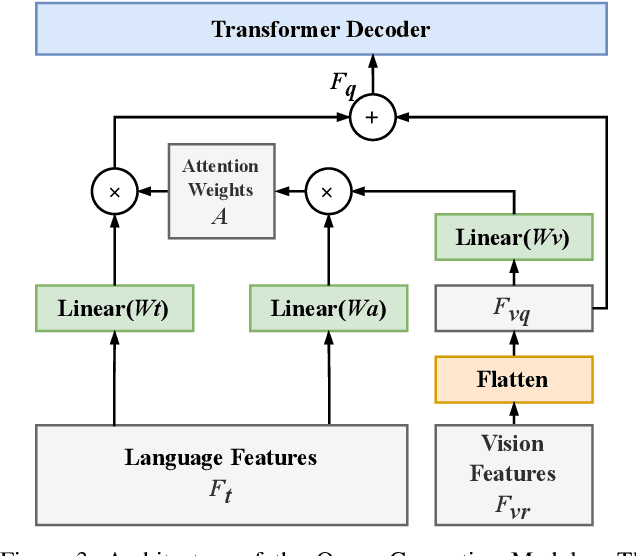
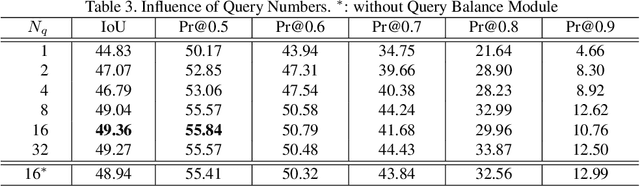
In this work, we address the challenging task of referring segmentation. The query expression in referring segmentation typically indicates the target object by describing its relationship with others. Therefore, to find the target one among all instances in the image, the model must have a holistic understanding of the whole image. To achieve this, we reformulate referring segmentation as a direct attention problem: finding the region in the image where the query language expression is most attended to. We introduce transformer and multi-head attention to build a network with an encoder-decoder attention mechanism architecture that "queries" the given image with the language expression. Furthermore, we propose a Query Generation Module, which produces multiple sets of queries with different attention weights that represent the diversified comprehensions of the language expression from different aspects. At the same time, to find the best way from these diversified comprehensions based on visual clues, we further propose a Query Balance Module to adaptively select the output features of these queries for a better mask generation. Without bells and whistles, our approach is light-weight and achieves new state-of-the-art performance consistently on three referring segmentation datasets, RefCOCO, RefCOCO+, and G-Ref. Our code is available at https://github.com/henghuiding/Vision-Language-Transformer.