 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSD-Score: Multi-Scale Distributional Scoring for Reference-Free Image Caption Evaluation
May 07, 2026Evaluating image captions without references remains challenging because global embedding similarity often misses fine-grained mismatches such as hallucinated objects, missing attributes, or incorrect relations. We propose MSD-Score, a reference-free metric that models image patch and text token embeddings as von Mises-Fisher mixtures on the unit hypersphere. Instead of treating each modality as a single point, MSD-Score formulates image-text matching as a multi-scale distributional scoring problem. Semantic discrepancies are quantified via a weighted bi-directional KL divergence and combined with global similarity in a multi-scale framework for both single- and multi-candidate evaluations. Extensive experiments show that MSD-Score achieves state-of-the-art correlation with human judgments among reference-free metrics. Beyond accuracy, its probabilistic formulation yields transparent and decomposable diagnostics of local grounding errors, providing a deterministic complementary signal to holistic similarity metrics and judge-based evaluators.
Not all tokens contribute equally to diffusion learning
Apr 08, 2026With the rapid development of conditional diffusion models, significant progress has been made in text-to-video generation. However, we observe that these models often neglect semantically important tokens during inference, leading to biased or incomplete generations under classifier-free guidance. We attribute this issue to two key factors: distributional bias caused by the long-tailed token frequency in training data, and spatial misalignment in cross-attention where semantically important tokens are overshadowed by less informative ones. To address these issues, we propose Distribution-Aware Rectification and Spatial Ensemble (DARE), a unified framework that improves semantic guidance in diffusion models from the perspectives of distributional debiasing and spatial consistency. First, we introduce Distribution-Rectified Classifier-Free Guidance (DR-CFG), which regularizes the training process by dynamically suppressing dominant tokens with low semantic density, encouraging the model to better capture underrepresented semantic cues and learn a more balanced conditional distribution. This design mitigates the risk of the model distribution overfitting to tokens with low semantic density. Second, we propose Spatial Representation Alignment (SRA), which adaptively reweights cross-attention maps according to token importance and enforces representation consistency, enabling semantically important tokens to exert stronger spatial guidance during generation. This mechanism effectively prevents low semantic-density tokens from dominating the attention allocation, thereby avoiding the dilution of the spatial and distributional guidance provided by high semantic-density tokens. Extensive experiments on multiple benchmark datasets demonstrate that DARE consistently improves generation fidelity and semantic alignment, achieving significant gains over existing approaches.
Condition Weaving Meets Expert Modulation: Towards Universal and Controllable Image Generation
Aug 24, 2025The image-to-image generation task aims to produce controllable images by leveraging conditional inputs and prompt instructions. However, existing methods often train separate control branches for each type of condition, leading to redundant model structures and inefficient use of computational resources. To address this, we propose a Unified image-to-image Generation (UniGen) framework that supports diverse conditional inputs while enhancing generation efficiency and expressiveness. Specifically, to tackle the widely existing parameter redundancy and computational inefficiency in controllable conditional generation architectures, we propose the Condition Modulated Expert (CoMoE) module. This module aggregates semantically similar patch features and assigns them to dedicated expert modules for visual representation and conditional modeling. By enabling independent modeling of foreground features under different conditions, CoMoE effectively mitigates feature entanglement and redundant computation in multi-condition scenarios. Furthermore, to bridge the information gap between the backbone and control branches, we propose WeaveNet, a dynamic, snake-like connection mechanism that enables effective interaction between global text-level control from the backbone and fine-grained control from conditional branches. Extensive experiments on the Subjects-200K and MultiGen-20M datasets across various conditional image generation tasks demonstrate that our method consistently achieves state-of-the-art performance, validating its advantages in both versatility and effectiveness. The code has been uploaded to https://github.com/gavin-gqzhang/UniGen.
CFIS-YOLO: A Lightweight Multi-Scale Fusion Network for Edge-Deployable Wood Defect Detection
Apr 15, 2025Wood defect detection is critical for ensuring quality control in the wood processing industry. However, current industrial applications face two major challenges: traditional methods are costly, subjective, and labor-intensive, while mainstream deep learning models often struggle to balance detection accuracy and computational efficiency for edge deployment. To address these issues, this study proposes CFIS-YOLO, a lightweight object detection model optimized for edge devices. The model introduces an enhanced C2f structure, a dynamic feature recombination module, and a novel loss function that incorporates auxiliary bounding boxes and angular constraints. These innovations improve multi-scale feature fusion and small object localization while significantly reducing computational overhead. Evaluated on a public wood defect dataset, CFIS-YOLO achieves a mean Average Precision (mAP@0.5) of 77.5\%, outperforming the baseline YOLOv10s by 4 percentage points. On SOPHON BM1684X edge devices, CFIS-YOLO delivers 135 FPS, reduces power consumption to 17.3\% of the original implementation, and incurs only a 0.5 percentage point drop in mAP. These results demonstrate that CFIS-YOLO is a practical and effective solution for real-world wood defect detection in resource-constrained environments.
Patch Spatio-Temporal Relation Prediction for Video Anomaly Detection
Mar 28, 2024



Video Anomaly Detection (VAD), aiming to identify abnormalities within a specific context and timeframe, is crucial for intelligent Video Surveillance Systems. While recent deep learning-based VAD models have shown promising results by generating high-resolution frames, they often lack competence in preserving detailed spatial and temporal coherence in video frames. To tackle this issue, we propose a self-supervised learning approach for VAD through an inter-patch relationship prediction task. Specifically, we introduce a two-branch vision transformer network designed to capture deep visual features of video frames, addressing spatial and temporal dimensions responsible for modeling appearance and motion patterns, respectively. The inter-patch relationship in each dimension is decoupled into inter-patch similarity and the order information of each patch. To mitigate memory consumption, we convert the order information prediction task into a multi-label learning problem, and the inter-patch similarity prediction task into a distance matrix regression problem. Comprehensive experiments demonstrate the effectiveness of our method, surpassing pixel-generation-based methods by a significant margin across three public benchmarks. Additionally, our approach outperforms other self-supervised learning-based methods.
Unsupervised Collaborative Metric Learning with Mixed-Scale Groups for General Object Retrieval
Mar 16, 2024



The task of searching for visual objects in a large image dataset is difficult because it requires efficient matching and accurate localization of objects that can vary in size. Although the segment anything model (SAM) offers a potential solution for extracting object spatial context, learning embeddings for local objects remains a challenging problem. This paper presents a novel unsupervised deep metric learning approach, termed unsupervised collaborative metric learning with mixed-scale groups (MS-UGCML), devised to learn embeddings for objects of varying scales. Following this, a benchmark of challenges is assembled by utilizing COCO 2017 and VOC 2007 datasets to facilitate the training and evaluation of general object retrieval models. Finally, we conduct comprehensive ablation studies and discuss the complexities faced within the domain of general object retrieval. Our object retrieval evaluations span a range of datasets, including BelgaLogos, Visual Genome, LVIS, in addition to a challenging evaluation set that we have individually assembled for open-vocabulary evaluation. These comprehensive evaluations effectively highlight the robustness of our unsupervised MS-UGCML approach, with an object level and image level mAPs improvement of up to 6.69% and 10.03%, respectively. The code is publicly available at https://github.com/dengyuhai/MS-UGCML.
POAR: Towards Open-World Pedestrian Attribute Recognition
Mar 26, 2023



Pedestrian attribute recognition (PAR) aims to predict the attributes of a target pedestrian in a surveillance system. Existing methods address the PAR problem by training a multi-label classifier with predefined attribute classes. However, it is impossible to exhaust all pedestrian attributes in the real world. To tackle this problem, we develop a novel pedestrian open-attribute recognition (POAR) framework. Our key idea is to formulate the POAR problem as an image-text search problem. We design a Transformer-based image encoder with a masking strategy. A set of attribute tokens are introduced to focus on specific pedestrian parts (e.g., head, upper body, lower body, feet, etc.) and encode corresponding attributes into visual embeddings. Each attribute category is described as a natural language sentence and encoded by the text encoder. Then, we compute the similarity between the visual and text embeddings of attributes to find the best attribute descriptions for the input images. Different from existing methods that learn a specific classifier for each attribute category, we model the pedestrian at a part-level and explore the searching method to handle the unseen attributes. Finally, a many-to-many contrastive (MTMC) loss with masked tokens is proposed to train the network since a pedestrian image can comprise multiple attributes. Extensive experiments have been conducted on benchmark PAR datasets with an open-attribute setting. The results verified the effectiveness of the proposed POAR method, which can form a strong baseline for the POAR task.
Contrastive Bayesian Analysis for Deep Metric Learning
Oct 10, 2022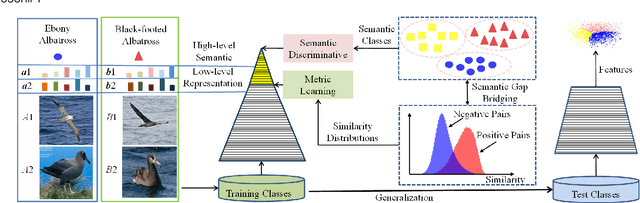
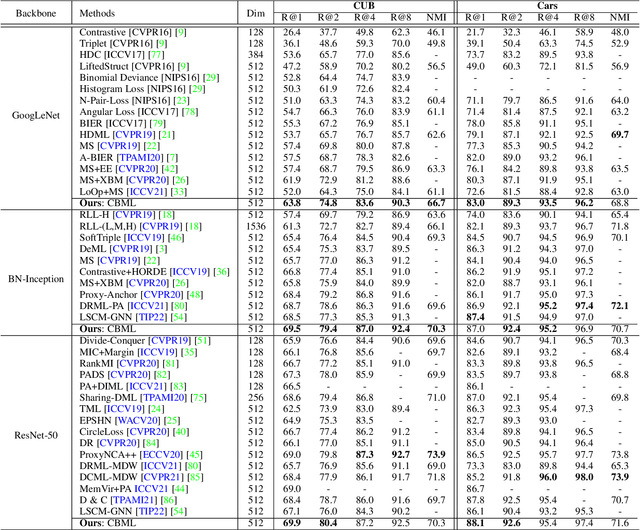
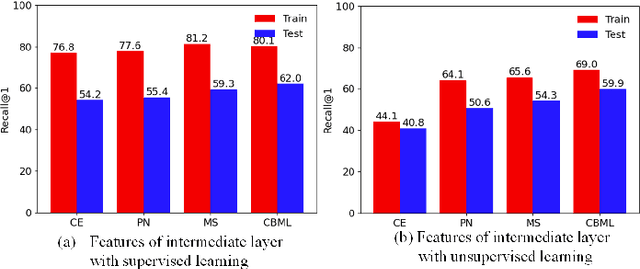
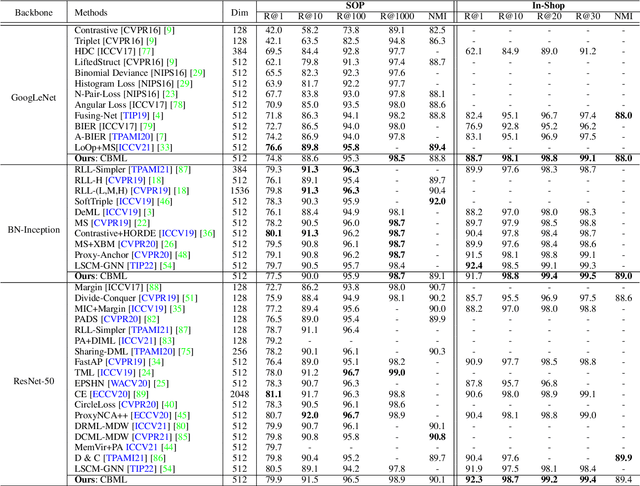
Recent methods for deep metric learning have been focusing on designing different contrastive loss functions between positive and negative pairs of samples so that the learned feature embedding is able to pull positive samples of the same class closer and push negative samples from different classes away from each other. In this work, we recognize that there is a significant semantic gap between features at the intermediate feature layer and class labels at the final output layer. To bridge this gap, we develop a contrastive Bayesian analysis to characterize and model the posterior probabilities of image labels conditioned by their features similarity in a contrastive learning setting. This contrastive Bayesian analysis leads to a new loss function for deep metric learning. To improve the generalization capability of the proposed method onto new classes, we further extend the contrastive Bayesian loss with a metric variance constraint. Our experimental results and ablation studies demonstrate that the proposed contrastive Bayesian metric learning method significantly improves the performance of deep metric learning in both supervised and pseudo-supervised scenarios, outperforming existing methods by a large margin.
Coded Residual Transform for Generalizable Deep Metric Learning
Oct 09, 2022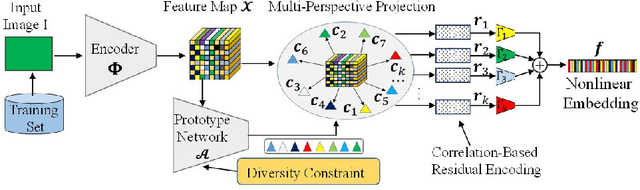

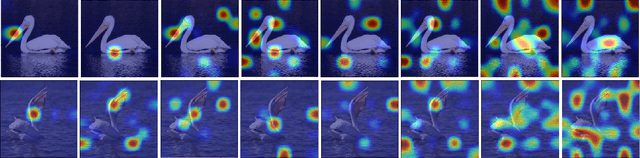
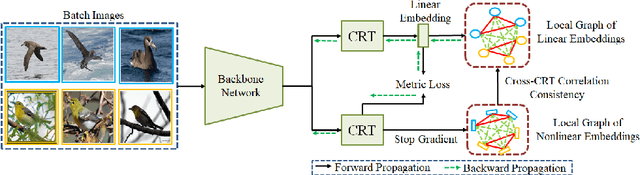
A fundamental challenge in deep metric learning is the generalization capability of the feature embedding network model since the embedding network learned on training classes need to be evaluated on new test classes. To address this challenge, in this paper, we introduce a new method called coded residual transform (CRT) for deep metric learning to significantly improve its generalization capability. Specifically, we learn a set of diversified prototype features, project the feature map onto each prototype, and then encode its features using their projection residuals weighted by their correlation coefficients with each prototype. The proposed CRT method has the following two unique characteristics. First, it represents and encodes the feature map from a set of complimentary perspectives based on projections onto diversified prototypes. Second, unlike existing transformer-based feature representation approaches which encode the original values of features based on global correlation analysis, the proposed coded residual transform encodes the relative differences between the original features and their projected prototypes. Embedding space density and spectral decay analysis show that this multi-perspective projection onto diversified prototypes and coded residual representation are able to achieve significantly improved generalization capability in metric learning. Finally, to further enhance the generalization performance, we propose to enforce the consistency on their feature similarity matrices between coded residual transforms with different sizes of projection prototypes and embedding dimensions. Our extensive experimental results and ablation studies demonstrate that the proposed CRT method outperform the state-of-the-art deep metric learning methods by large margins and improving upon the current best method by up to 4.28% on the CUB dataset.
LighTN: Light-weight Transformer Network for Performance-overhead Tradeoff in Point Cloud Downsampling
Feb 13, 2022Compared with traditional task-irrelevant downsampling methods, task-oriented neural networks have shown improved performance in point cloud downsampling range. Recently, Transformer family of networks has shown a more powerful learning capacity in visual tasks. However, Transformer-based architectures potentially consume too many resources which are usually worthless for low overhead task networks in downsampling range. This paper proposes a novel light-weight Transformer network (LighTN) for task-oriented point cloud downsampling, as an end-to-end and plug-and-play solution. In LighTN, a single-head self-correlation module is presented to extract refined global contextual features, where three projection matrices are simultaneously eliminated to save resource overhead, and the output of symmetric matrix satisfies the permutation invariant. Then, we design a novel downsampling loss function to guide LighTN focuses on critical point cloud regions with more uniform distribution and prominent points coverage. Furthermore, We introduce a feed-forward network scaling mechanism to enhance the learnable capacity of LighTN according to the expand-reduce strategy. The result of extensive experiments on classification and registration tasks demonstrates LighTN can achieve state-of-the-art performance with limited resource overhead.