 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCondition Weaving Meets Expert Modulation: Towards Universal and Controllable Image Generation
Aug 24, 2025The image-to-image generation task aims to produce controllable images by leveraging conditional inputs and prompt instructions. However, existing methods often train separate control branches for each type of condition, leading to redundant model structures and inefficient use of computational resources. To address this, we propose a Unified image-to-image Generation (UniGen) framework that supports diverse conditional inputs while enhancing generation efficiency and expressiveness. Specifically, to tackle the widely existing parameter redundancy and computational inefficiency in controllable conditional generation architectures, we propose the Condition Modulated Expert (CoMoE) module. This module aggregates semantically similar patch features and assigns them to dedicated expert modules for visual representation and conditional modeling. By enabling independent modeling of foreground features under different conditions, CoMoE effectively mitigates feature entanglement and redundant computation in multi-condition scenarios. Furthermore, to bridge the information gap between the backbone and control branches, we propose WeaveNet, a dynamic, snake-like connection mechanism that enables effective interaction between global text-level control from the backbone and fine-grained control from conditional branches. Extensive experiments on the Subjects-200K and MultiGen-20M datasets across various conditional image generation tasks demonstrate that our method consistently achieves state-of-the-art performance, validating its advantages in both versatility and effectiveness. The code has been uploaded to https://github.com/gavin-gqzhang/UniGen.
CLIP-driven Dual Feature Enhancing Network for Gaze Estimation
Feb 27, 2025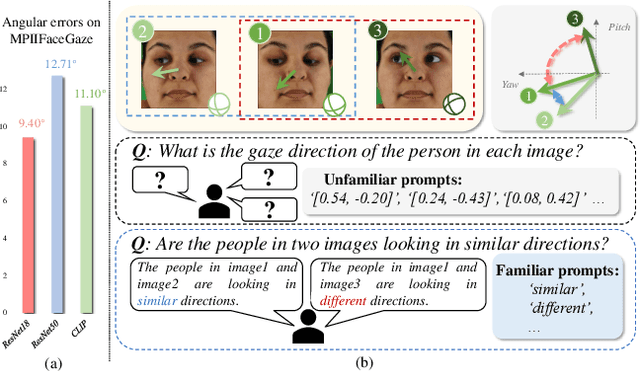
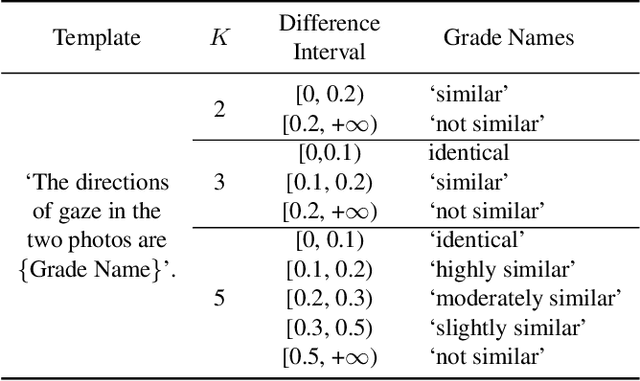
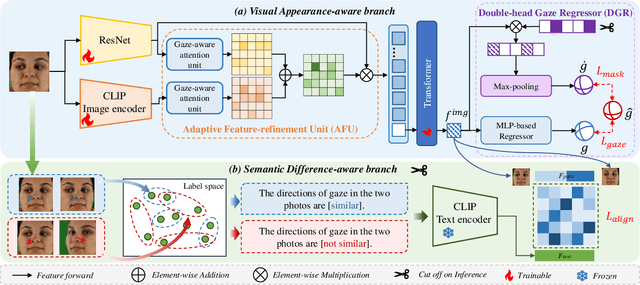
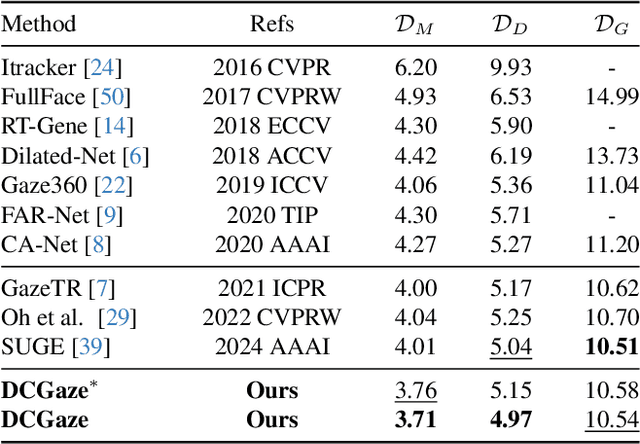
The complex application scenarios have raised critical requirements for precise and generalizable gaze estimation methods. Recently, the pre-trained CLIP has achieved remarkable performance on various vision tasks, but its potentials have not been fully exploited in gaze estimation. In this paper, we propose a novel CLIP-driven Dual Feature Enhancing Network (CLIP-DFENet), which boosts gaze estimation performance with the help of CLIP under a novel `main-side' collaborative enhancing strategy. Accordingly, a Language-driven Differential Module (LDM) is designed on the basis of the CLIP's text encoder to reveal the semantic difference of gaze. This module could empower our Core Feature Extractor with the capability of characterizing the gaze-related semantic information. Moreover, a Vision-driven Fusion Module (VFM) is introduced to strengthen the generalized and valuable components of visual embeddings obtained via CLIP's image encoder, and utilizes them to further improve the generalization of the features captured by Core Feature Extractor. Finally, a robust Double-head Gaze Regressor is adopted to map the enhanced features to gaze directions. Extensive experimental results on four challenging datasets over within-domain and cross-domain tasks demonstrate the discriminability and generalizability of our CLIP-DFENet.
Patch Spatio-Temporal Relation Prediction for Video Anomaly Detection
Mar 28, 2024



Video Anomaly Detection (VAD), aiming to identify abnormalities within a specific context and timeframe, is crucial for intelligent Video Surveillance Systems. While recent deep learning-based VAD models have shown promising results by generating high-resolution frames, they often lack competence in preserving detailed spatial and temporal coherence in video frames. To tackle this issue, we propose a self-supervised learning approach for VAD through an inter-patch relationship prediction task. Specifically, we introduce a two-branch vision transformer network designed to capture deep visual features of video frames, addressing spatial and temporal dimensions responsible for modeling appearance and motion patterns, respectively. The inter-patch relationship in each dimension is decoupled into inter-patch similarity and the order information of each patch. To mitigate memory consumption, we convert the order information prediction task into a multi-label learning problem, and the inter-patch similarity prediction task into a distance matrix regression problem. Comprehensive experiments demonstrate the effectiveness of our method, surpassing pixel-generation-based methods by a significant margin across three public benchmarks. Additionally, our approach outperforms other self-supervised learning-based methods.