 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatch Spatio-Temporal Relation Prediction for Video Anomaly Detection
Mar 28, 2024



Video Anomaly Detection (VAD), aiming to identify abnormalities within a specific context and timeframe, is crucial for intelligent Video Surveillance Systems. While recent deep learning-based VAD models have shown promising results by generating high-resolution frames, they often lack competence in preserving detailed spatial and temporal coherence in video frames. To tackle this issue, we propose a self-supervised learning approach for VAD through an inter-patch relationship prediction task. Specifically, we introduce a two-branch vision transformer network designed to capture deep visual features of video frames, addressing spatial and temporal dimensions responsible for modeling appearance and motion patterns, respectively. The inter-patch relationship in each dimension is decoupled into inter-patch similarity and the order information of each patch. To mitigate memory consumption, we convert the order information prediction task into a multi-label learning problem, and the inter-patch similarity prediction task into a distance matrix regression problem. Comprehensive experiments demonstrate the effectiveness of our method, surpassing pixel-generation-based methods by a significant margin across three public benchmarks. Additionally, our approach outperforms other self-supervised learning-based methods.
2D+3D facial expression recognition via embedded tensor manifold regularization
Jan 29, 2022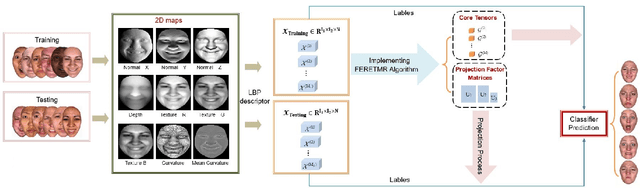
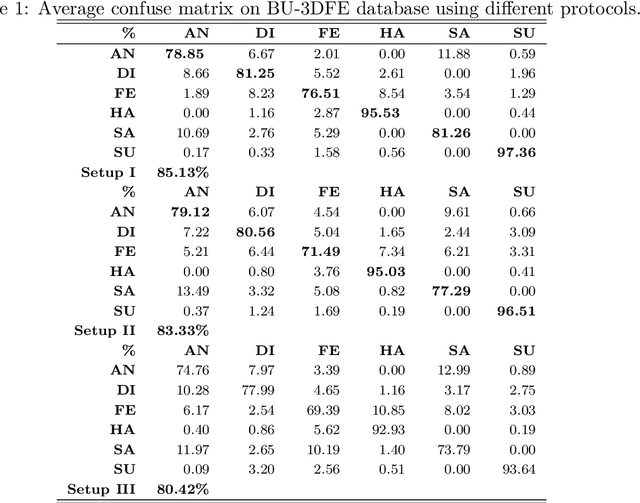
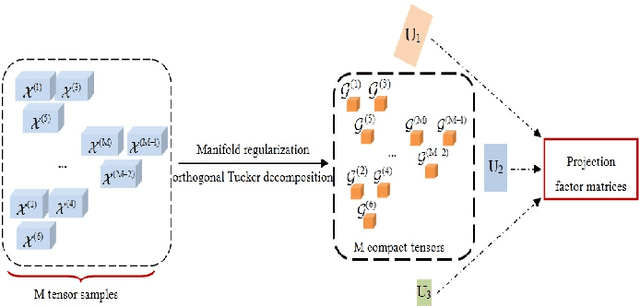
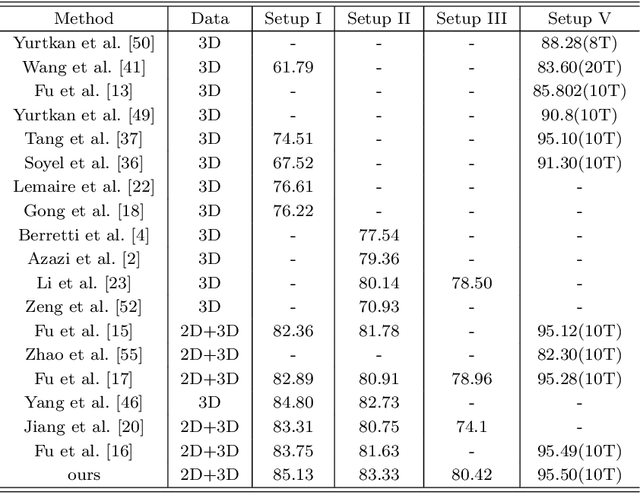
In this paper, a novel approach via embedded tensor manifold regularization for 2D+3D facial expression recognition (FERETMR) is proposed. Firstly, 3D tensors are constructed from 2D face images and 3D face shape models to keep the structural information and correlations. To maintain the local structure (geometric information) of 3D tensor samples in the low-dimensional tensors space during the dimensionality reduction, the $\ell_0$-norm of the core tensors and a tensor manifold regularization scheme embedded on core tensors are adopted via a low-rank truncated Tucker decomposition on the generated tensors. As a result, the obtained factor matrices will be used for facial expression classification prediction. To make the resulting tensor optimization more tractable, $\ell_1$-norm surrogate is employed to relax $\ell_0$-norm and hence the resulting tensor optimization problem has a nonsmooth objective function due to the $\ell_1$-norm and orthogonal constraints from the orthogonal Tucker decomposition. To efficiently tackle this tensor optimization problem, we establish the first-order optimality condition in terms of stationary points, and then design a block coordinate descent (BCD) algorithm with convergence analysis and the computational complexity. Numerical results on BU-3DFE database and Bosphorus databases demonstrate the effectiveness of our proposed approach.
Prototype Guided Network for Anomaly Segmentation
Jan 15, 2022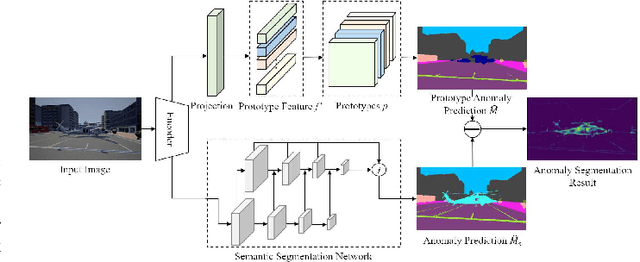


Semantic segmentation methods can not directly identify abnormal objects in images. Anomaly Segmentation algorithm from this realistic setting can distinguish between in-distribution objects and Out-Of-Distribution (OOD) objects and output the anomaly probability for pixels. In this paper, a Prototype Guided Anomaly segmentation Network (PGAN) is proposed to extract semantic prototypes for in-distribution training data from limited annotated images. In the model, prototypes are used to model the hierarchical category semantic information and distinguish OOD pixels. The proposed PGAN model includes a semantic segmentation network and a prototype extraction network. Similarity measures are adopted to optimize the prototypes. The learned semantic prototypes are used as category semantics to compare the similarity with features extracted from test images and then to generate semantic segmentation prediction. The proposed prototype extraction network can also be integrated into most semantic segmentation networks and recognize OOD pixels. On the StreetHazards dataset, the proposed PGAN model produced mIoU of 53.4% for anomaly segmentation. The experimental results demonstrate PGAN may achieve the SOTA performance in the anomaly segmentation tasks.
STSM: Spatio-Temporal Shift Module for Efficient Action Recognition
Dec 05, 2021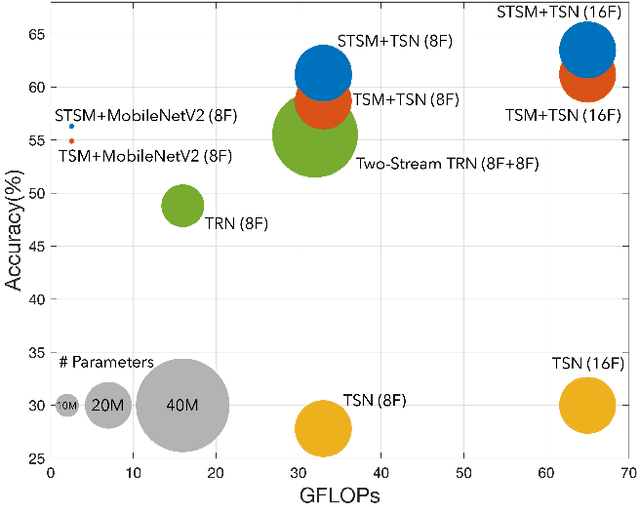



The modeling, computational cost, and accuracy of traditional Spatio-temporal networks are the three most concentrated research topics in video action recognition. The traditional 2D convolution has a low computational cost, but it cannot capture the time relationship; the convolutional neural networks (CNNs) model based on 3D convolution can obtain good performance, but its computational cost is high, and the amount of parameters is large. In this paper, we propose a plug-and-play Spatio-temporal Shift Module (STSM), which is a generic module that is both effective and high-performance. Specifically, after STSM is inserted into other networks, the performance of the network can be improved without increasing the number of calculations and parameters. In particular, when the network is 2D CNNs, our STSM module allows the network to learn efficient Spatio-temporal features. We conducted extensive evaluations of the proposed module, conducted numerous experiments to study its effectiveness in video action recognition, and achieved state-of-the-art results on the kinetics-400 and Something-Something V2 datasets.
E2-Capsule Neural Networks for Facial Expression Recognition Using AU-Aware Attention
Dec 05, 2019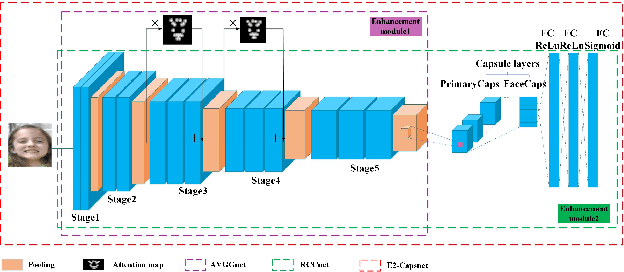



Capsule neural network is a new and popular technique in deep learning. However, the traditional capsule neural network does not extract features sufficiently before the dynamic routing between the capsules. In this paper, the one Double Enhanced Capsule Neural Network (E2-Capsnet) that uses AU-aware attention for facial expression recognition (FER) is proposed. The E2-Capsnet takes advantage of dynamic routing between the capsules, and has two enhancement modules which are beneficial for FER. The first enhancement module is the convolutional neural network with AU-aware attention, which can help focus on the active areas of the expression. The second enhancement module is the capsule neural network with multiple convolutional layers, which enhances the ability of the feature representation. Finally, squashing function is used to classify the facial expression. We demonstrate the effectiveness of E2-Capsnet on the two public benchmark datasets, RAF-DB and EmotioNet. The experimental results show that our E2-Capsnet is superior to the state-of-the-art methods. Our implementation will be publicly available online.
Squeeze-and-Excitation on Spatial and Temporal Deep Feature Space for Action Recognition
Jul 20, 2018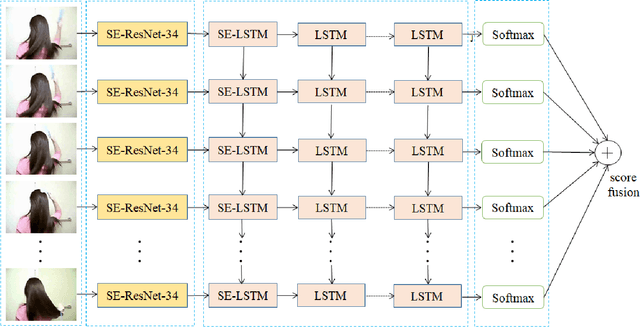
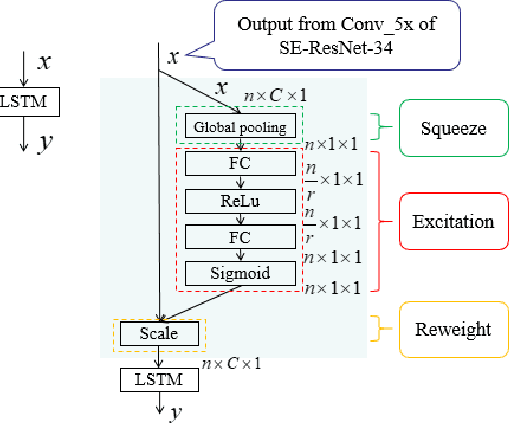
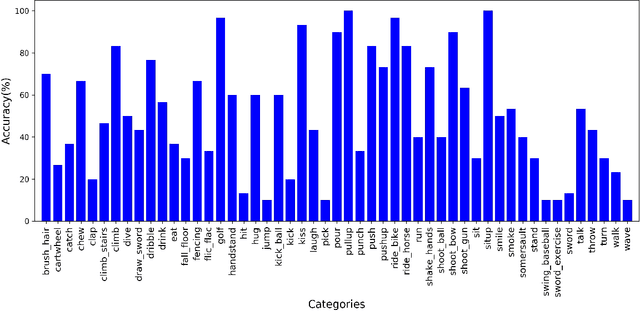

Spatial and temporal features are two key and complementary information for human action recognition. In order to make full use of the intra-frame spatial characteristics and inter-frame temporal relationships, we propose the Squeeze-and-Excitation Long-term Recurrent Convolutional Networks (SE-LRCN) for human action recognition. The Squeeze and Excitation operations are used to implement the feature recalibration. In SE-LRCN, Squeeze-and-Excitation ResNet-34 (SE-ResNet-34) network is adopted to extract spatial features to enhance the dependencies and importance of feature channels of pixel granularity. We also propose the Squeeze-and-Excitation Long Short-Term Memory (SE-LSTM) network to model the temporal relationship, and to enhance the dependencies and importance of feature channels of frame granularity. We evaluate the proposed model on two challenging benchmarks, HMDB51 and UCF101, and the proposed SE-LRCN achieves the competitive results with the state-of-the-art.
Multi-Level Recurrent Residual Networks for Action Recognition
Jan 03, 2018



Most existing Convolutional Neural Networks(CNNs) used for action recognition are either difficult to optimize or underuse crucial temporal information. Inspired by the fact that the recurrent model consistently makes breakthroughs in the task related to sequence, we propose a novel Multi-Level Recurrent Residual Networks(MRRN) which incorporates three recognition streams. Each stream consists of a Residual Networks(ResNets) and a recurrent model. The proposed model captures spatiotemporal information by employing both alternative ResNets to learn spatial representations from static frames and stacked Simple Recurrent Units(SRUs) to model temporal dynamics. Three distinct-level streams learned low-, mid-, high-level representations independently are fused by computing a weighted average of their softmax scores to obtain the complementary representations of the video. Unlike previous models which boost performance at the cost of time complexity and space complexity, our models have a lower complexity by employing shortcut connection and are trained end-to-end with greater efficiency. MRRN displays significant performance improvements compared to CNN-RNN framework baselines and obtains comparable performance with the state-of-the-art, achieving 51.3% on HMDB-51 dataset and 81.9% on UCF-101 dataset although no additional data.