 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot all tokens contribute equally to diffusion learning
Apr 08, 2026With the rapid development of conditional diffusion models, significant progress has been made in text-to-video generation. However, we observe that these models often neglect semantically important tokens during inference, leading to biased or incomplete generations under classifier-free guidance. We attribute this issue to two key factors: distributional bias caused by the long-tailed token frequency in training data, and spatial misalignment in cross-attention where semantically important tokens are overshadowed by less informative ones. To address these issues, we propose Distribution-Aware Rectification and Spatial Ensemble (DARE), a unified framework that improves semantic guidance in diffusion models from the perspectives of distributional debiasing and spatial consistency. First, we introduce Distribution-Rectified Classifier-Free Guidance (DR-CFG), which regularizes the training process by dynamically suppressing dominant tokens with low semantic density, encouraging the model to better capture underrepresented semantic cues and learn a more balanced conditional distribution. This design mitigates the risk of the model distribution overfitting to tokens with low semantic density. Second, we propose Spatial Representation Alignment (SRA), which adaptively reweights cross-attention maps according to token importance and enforces representation consistency, enabling semantically important tokens to exert stronger spatial guidance during generation. This mechanism effectively prevents low semantic-density tokens from dominating the attention allocation, thereby avoiding the dilution of the spatial and distributional guidance provided by high semantic-density tokens. Extensive experiments on multiple benchmark datasets demonstrate that DARE consistently improves generation fidelity and semantic alignment, achieving significant gains over existing approaches.
Patch Spatio-Temporal Relation Prediction for Video Anomaly Detection
Mar 28, 2024



Video Anomaly Detection (VAD), aiming to identify abnormalities within a specific context and timeframe, is crucial for intelligent Video Surveillance Systems. While recent deep learning-based VAD models have shown promising results by generating high-resolution frames, they often lack competence in preserving detailed spatial and temporal coherence in video frames. To tackle this issue, we propose a self-supervised learning approach for VAD through an inter-patch relationship prediction task. Specifically, we introduce a two-branch vision transformer network designed to capture deep visual features of video frames, addressing spatial and temporal dimensions responsible for modeling appearance and motion patterns, respectively. The inter-patch relationship in each dimension is decoupled into inter-patch similarity and the order information of each patch. To mitigate memory consumption, we convert the order information prediction task into a multi-label learning problem, and the inter-patch similarity prediction task into a distance matrix regression problem. Comprehensive experiments demonstrate the effectiveness of our method, surpassing pixel-generation-based methods by a significant margin across three public benchmarks. Additionally, our approach outperforms other self-supervised learning-based methods.
Layer-adaptive Structured Pruning Guided by Latency
May 23, 2023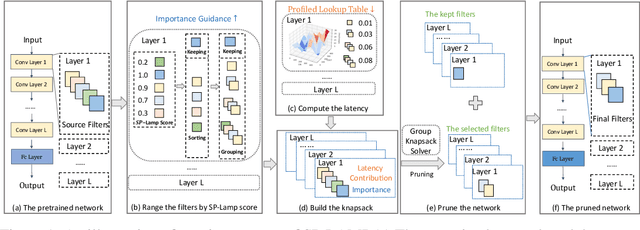
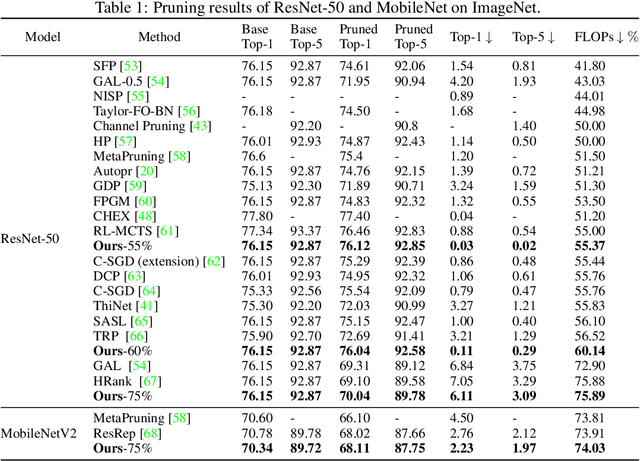
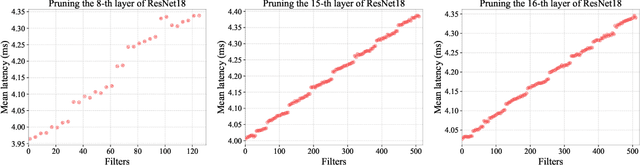
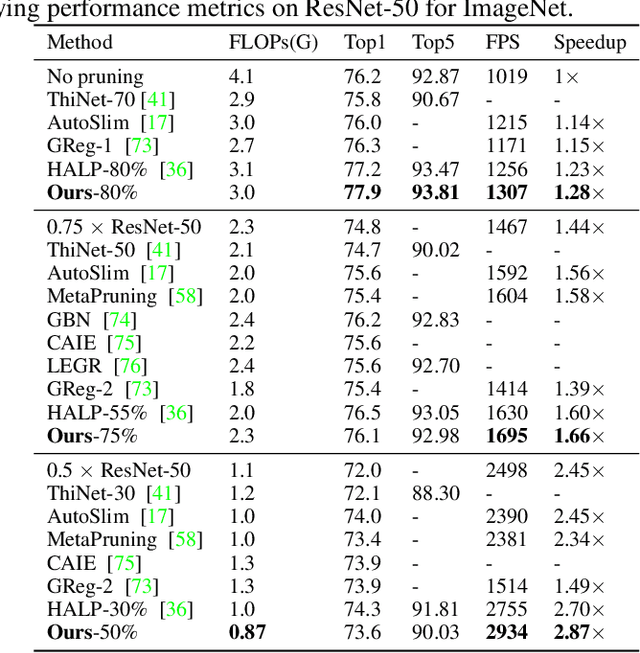
Structured pruning can simplify network architecture and improve inference speed. Combined with the underlying hardware and inference engine in which the final model is deployed, better results can be obtained by using latency collaborative loss function to guide network pruning together. Existing pruning methods that optimize latency have demonstrated leading performance, however, they often overlook the hardware features and connection in the network. To address this problem, we propose a global importance score SP-LAMP(Structured Pruning Layer-Adaptive Magnitude-based Pruning) by deriving a global importance score LAMP from unstructured pruning to structured pruning. In SP-LAMP, each layer includes a filter with an SP-LAMP score of 1, and the remaining filters are grouped. We utilize a group knapsack solver to maximize the SP-LAMP score under latency constraints. In addition, we improve the strategy of collect the latency to make it more accurate. In particular, for ResNet50/ResNet18 on ImageNet and CIFAR10, SP-LAMP is 1.28x/8.45x faster with +1.7%/-1.57% top-1 accuracy changed, respectively. Experimental results in ResNet56 on CIFAR10 demonstrate that our algorithm achieves lower latency compared to alternative approaches while ensuring accuracy and FLOPs.