 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueeze-and-Excitation on Spatial and Temporal Deep Feature Space for Action Recognition
Jul 20, 2018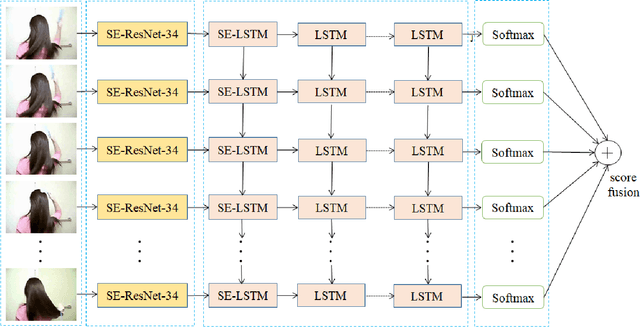
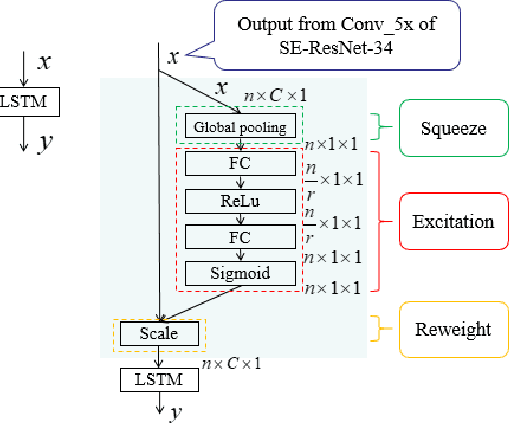
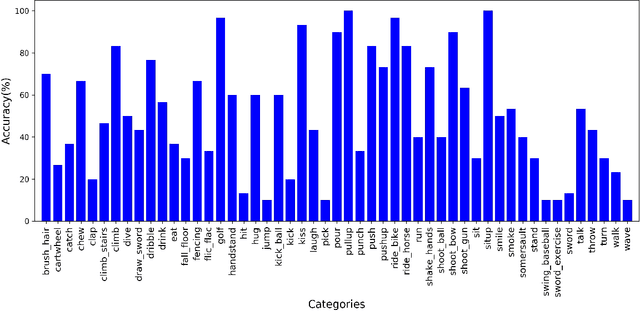

Spatial and temporal features are two key and complementary information for human action recognition. In order to make full use of the intra-frame spatial characteristics and inter-frame temporal relationships, we propose the Squeeze-and-Excitation Long-term Recurrent Convolutional Networks (SE-LRCN) for human action recognition. The Squeeze and Excitation operations are used to implement the feature recalibration. In SE-LRCN, Squeeze-and-Excitation ResNet-34 (SE-ResNet-34) network is adopted to extract spatial features to enhance the dependencies and importance of feature channels of pixel granularity. We also propose the Squeeze-and-Excitation Long Short-Term Memory (SE-LSTM) network to model the temporal relationship, and to enhance the dependencies and importance of feature channels of frame granularity. We evaluate the proposed model on two challenging benchmarks, HMDB51 and UCF101, and the proposed SE-LRCN achieves the competitive results with the state-of-the-art.
Multi-Level Recurrent Residual Networks for Action Recognition
Jan 03, 2018



Most existing Convolutional Neural Networks(CNNs) used for action recognition are either difficult to optimize or underuse crucial temporal information. Inspired by the fact that the recurrent model consistently makes breakthroughs in the task related to sequence, we propose a novel Multi-Level Recurrent Residual Networks(MRRN) which incorporates three recognition streams. Each stream consists of a Residual Networks(ResNets) and a recurrent model. The proposed model captures spatiotemporal information by employing both alternative ResNets to learn spatial representations from static frames and stacked Simple Recurrent Units(SRUs) to model temporal dynamics. Three distinct-level streams learned low-, mid-, high-level representations independently are fused by computing a weighted average of their softmax scores to obtain the complementary representations of the video. Unlike previous models which boost performance at the cost of time complexity and space complexity, our models have a lower complexity by employing shortcut connection and are trained end-to-end with greater efficiency. MRRN displays significant performance improvements compared to CNN-RNN framework baselines and obtains comparable performance with the state-of-the-art, achieving 51.3% on HMDB-51 dataset and 81.9% on UCF-101 dataset although no additional data.