 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving the bias-precision paradox with stochastic causal representation learning for personalized medicine
May 07, 2026Estimating individualized treatment effects from longitudinal observational data is central to data-driven medicine, yet existing methods face a fundamental limitation: reducing confounding bias often suppresses clinically informative heterogeneity, degrading patient-specific predictions. Here, we identify this tension as a bias-precision paradox in causal representation learning and introduce sampling-based maximum mean discrepancy (sMMD), a stochastic alignment strategy that replaces global adversarial balancing with subset-level matching. We instantiate this approach in a framework for counterfactual outcome prediction with attribution-grounded interpretability. Across two large-scale ICU cohorts (n = 27,783), our framework improves accuracy under distribution shift, reducing error by up to 11.5% and substantially increasing recall in high-risk tasks. Mechanistic analyses show that sMMD selectively preserves clinically decisive variables. In human-AI evaluation, our method outperforms clinicians-in-training and large language models, and improves clinician accuracy by 14.7% while reducing decision time, enabling interpretable, real-time clinical decision support.
When would Vision-Proprioception Policies Fail in Robotic Manipulation?
Feb 12, 2026Proprioceptive information is critical for precise servo control by providing real-time robotic states. Its collaboration with vision is highly expected to enhance performances of the manipulation policy in complex tasks. However, recent studies have reported inconsistent observations on the generalization of vision-proprioception policies. In this work, we investigate this by conducting temporally controlled experiments. We found that during task sub-phases that robot's motion transitions, which require target localization, the vision modality of the vision-proprioception policy plays a limited role. Further analysis reveals that the policy naturally gravitates toward concise proprioceptive signals that offer faster loss reduction when training, thereby dominating the optimization and suppressing the learning of the visual modality during motion-transition phases. To alleviate this, we propose the Gradient Adjustment with Phase-guidance (GAP) algorithm that adaptively modulates the optimization of proprioception, enabling dynamic collaboration within the vision-proprioception policy. Specifically, we leverage proprioception to capture robotic states and estimate the probability of each timestep in the trajectory belonging to motion-transition phases. During policy learning, we apply fine-grained adjustment that reduces the magnitude of proprioception's gradient based on estimated probabilities, leading to robust and generalizable vision-proprioception policies. The comprehensive experiments demonstrate GAP is applicable in both simulated and real-world environments, across one-arm and dual-arm setups, and compatible with both conventional and Vision-Language-Action models. We believe this work can offer valuable insights into the development of vision-proprioception policies in robotic manipulation.
UniLayDiff: A Unified Diffusion Transformer for Content-Aware Layout Generation
Dec 09, 2025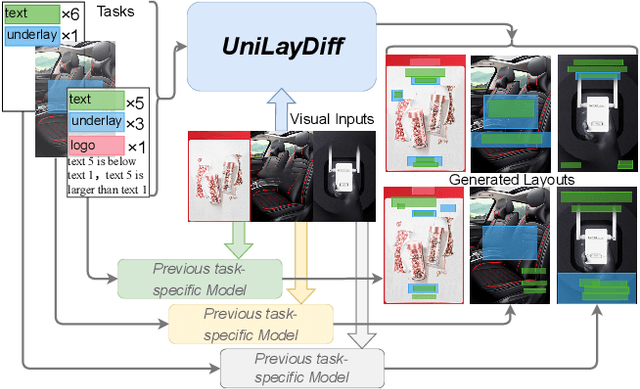
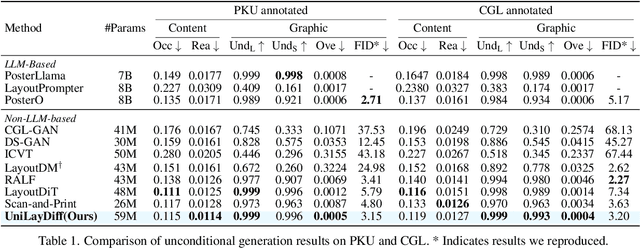
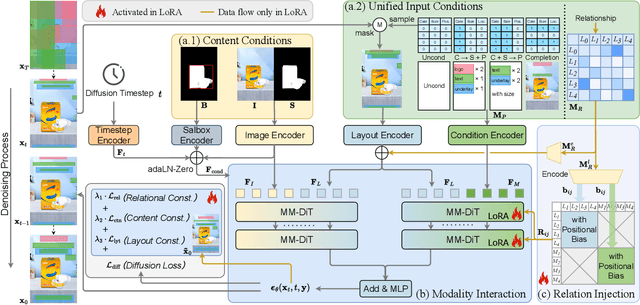
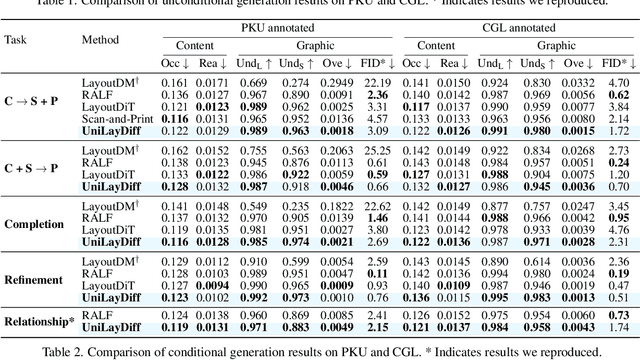
Content-aware layout generation is a critical task in graphic design automation, focused on creating visually appealing arrangements of elements that seamlessly blend with a given background image. The variety of real-world applications makes it highly challenging to develop a single model capable of unifying the diverse range of input-constrained generation sub-tasks, such as those conditioned by element types, sizes, or their relationships. Current methods either address only a subset of these tasks or necessitate separate model parameters for different conditions, failing to offer a truly unified solution. In this paper, we propose UniLayDiff: a Unified Diffusion Transformer, that for the first time, addresses various content-aware layout generation tasks with a single, end-to-end trainable model. Specifically, we treat layout constraints as a distinct modality and employ Multi-Modal Diffusion Transformer framework to capture the complex interplay between the background image, layout elements, and diverse constraints. Moreover, we integrate relation constraints through fine-tuning the model with LoRA after pretraining the model on other tasks. Such a schema not only achieves unified conditional generation but also enhances overall layout quality. Extensive experiments demonstrate that UniLayDiff achieves state-of-the-art performance across from unconditional to various conditional generation tasks and, to the best of our knowledge, is the first model to unify the full range of content-aware layout generation tasks.
Improving End-to-End Training of Retrieval-Augmented Generation Models via Joint Stochastic Approximation
Aug 25, 2025



Retrieval-augmented generation (RAG) has become a widely recognized paradigm to combine parametric memory with non-parametric memories. An RAG model consists of two serial connecting components (retriever and generator). A major challenge in end-to-end optimization of the RAG model is that marginalization over relevant passages (modeled as discrete latent variables) from a knowledge base is required. Traditional top-K marginalization and variational RAG (VRAG) suffer from biased or high-variance gradient estimates. In this paper, we propose and develop joint stochastic approximation (JSA) based end-to-end training of RAG, which is referred to as JSA-RAG. The JSA algorithm is a stochastic extension of the EM (expectation-maximization) algorithm and is particularly powerful in estimating discrete latent variable models. Extensive experiments are conducted on five datasets for two tasks (open-domain question answering, knowledge-grounded dialogs) and show that JSA-RAG significantly outperforms both vanilla RAG and VRAG. Further analysis shows the efficacy of JSA-RAG from the perspectives of generation, retrieval, and low-variance gradient estimate.
Bi-Directional Multi-Scale Graph Dataset Condensation via Information Bottleneck
Dec 23, 2024Dataset condensation has significantly improved model training efficiency, but its application on devices with different computing power brings new requirements for different data sizes. Thus, condensing multiple scale graphs simultaneously is the core of achieving efficient training in different on-device scenarios. Existing efficient works for multi-scale graph dataset condensation mainly perform efficient approximate computation in scale order (large-to-small or small-to-large scales). However, for non-Euclidean structures of sparse graph data, these two commonly used paradigms for multi-scale graph dataset condensation have serious scaling down degradation and scaling up collapse problems of a graph. The main bottleneck of the above paradigms is whether the effective information of the original graph is fully preserved when consenting to the primary sub-scale (the first of multiple scales), which determines the condensation effect and consistency of all scales. In this paper, we proposed a novel GNN-centric Bi-directional Multi-Scale Graph Dataset Condensation (BiMSGC) framework, to explore unifying paradigms by operating on both large-to-small and small-to-large for multi-scale graph condensation. Based on the mutual information theory, we estimate an optimal ``meso-scale'' to obtain the minimum necessary dense graph preserving the maximum utility information of the original graph, and then we achieve stable and consistent ``bi-directional'' condensation learning by optimizing graph eigenbasis matching with information bottleneck on other scales. Encouraging empirical results on several datasets demonstrates the significant superiority of the proposed framework in graph condensation at different scales.
RL-GSBridge: 3D Gaussian Splatting Based Real2Sim2Real Method for Robotic Manipulation Learning
Sep 30, 2024
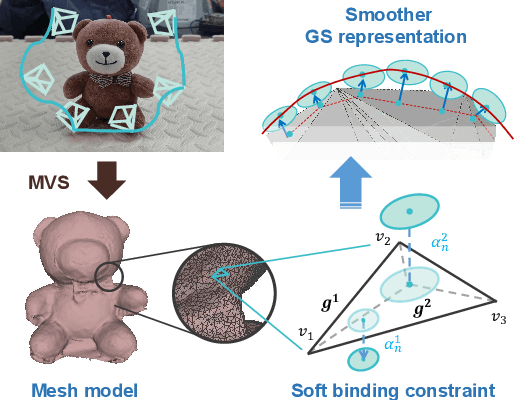
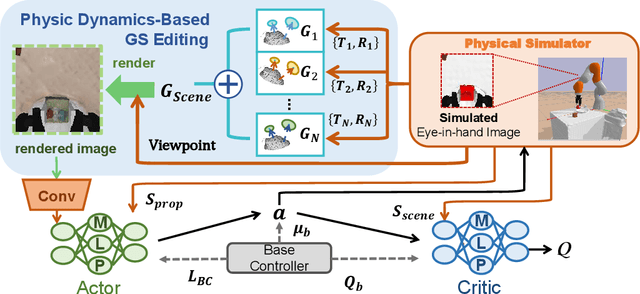

Sim-to-Real refers to the process of transferring policies learned in simulation to the real world, which is crucial for achieving practical robotics applications. However, recent Sim2real methods either rely on a large amount of augmented data or large learning models, which is inefficient for specific tasks. In recent years, radiance field-based reconstruction methods, especially the emergence of 3D Gaussian Splatting, making it possible to reproduce realistic real-world scenarios. To this end, we propose a novel real-to-sim-to-real reinforcement learning framework, RL-GSBridge, which introduces a mesh-based 3D Gaussian Splatting method to realize zero-shot sim-to-real transfer for vision-based deep reinforcement learning. We improve the mesh-based 3D GS modeling method by using soft binding constraints, enhancing the rendering quality of mesh models. We then employ a GS editing approach to synchronize rendering with the physics simulator, reflecting the interactions of the physical robot more accurately. Through a series of sim-to-real robotic arm experiments, including grasping and pick-and-place tasks, we demonstrate that RL-GSBridge maintains a satisfactory success rate in real-world task completion during sim-to-real transfer. Furthermore, a series of rendering metrics and visualization results indicate that our proposed mesh-based 3D Gaussian reduces artifacts in unstructured objects, demonstrating more realistic rendering performance.
RING#: PR-by-PE Global Localization with Roto-translation Equivariant Gram Learning
Aug 30, 2024



Global localization using onboard perception sensors, such as cameras and LiDARs, is crucial in autonomous driving and robotics applications when GPS signals are unreliable. Most approaches achieve global localization by sequential place recognition and pose estimation. Some of them train separate models for each task, while others employ a single model with dual heads, trained jointly with separate task-specific losses. However, the accuracy of localization heavily depends on the success of place recognition, which often fails in scenarios with significant changes in viewpoint or environmental appearance. Consequently, this renders the final pose estimation of localization ineffective. To address this, we propose a novel paradigm, PR-by-PE localization, which improves global localization accuracy by deriving place recognition directly from pose estimation. Our framework, RING#, is an end-to-end PR-by-PE localization network operating in the bird's-eye view (BEV) space, designed to support both vision and LiDAR sensors. It introduces a theoretical foundation for learning two equivariant representations from BEV features, which enables globally convergent and computationally efficient pose estimation. Comprehensive experiments on the NCLT and Oxford datasets across both vision and LiDAR modalities demonstrate that our method outperforms state-of-the-art approaches. Furthermore, we provide extensive analyses to confirm the effectiveness of our method. The code will be publicly released.
A PLMs based protein retrieval framework
Jul 16, 2024



Protein retrieval, which targets the deconstruction of the relationship between sequences, structures and functions, empowers the advancing of biology. Basic Local Alignment Search Tool (BLAST), a sequence-similarity-based algorithm, has proved the efficiency of this field. Despite the existing tools for protein retrieval, they prioritize sequence similarity and probably overlook proteins that are dissimilar but share homology or functionality. In order to tackle this problem, we propose a novel protein retrieval framework that mitigates the bias towards sequence similarity. Our framework initiatively harnesses protein language models (PLMs) to embed protein sequences within a high-dimensional feature space, thereby enhancing the representation capacity for subsequent analysis. Subsequently, an accelerated indexed vector database is constructed to facilitate expedited access and retrieval of dense vectors. Extensive experiments demonstrate that our framework can equally retrieve both similar and dissimilar proteins. Moreover, this approach enables the identification of proteins that conventional methods fail to uncover. This framework will effectively assist in protein mining and empower the development of biology.
Emergent Interpretable Symbols and Content-Style Disentanglement via Variance-Invariance Constraints
Jul 04, 2024



We contribute an unsupervised method that effectively learns from raw observation and disentangles its latent space into content and style representations. Unlike most disentanglement algorithms that rely on domain-specific labels and knowledge, our method is based on the insight of domain-general statistical differences between content and style -- content varies more among different fragments within a sample but maintains an invariant vocabulary across data samples, whereas style remains relatively invariant within a sample but exhibits more significant variation across different samples. We integrate such inductive bias into an encoder-decoder architecture and name our method after V3 (variance-versus-invariance). Experimental results show that V3 generalizes across two distinct domains in different modalities, music audio and images of written digits, successfully learning pitch-timbre and digit-color disentanglements, respectively. Also, the disentanglement robustness significantly outperforms baseline unsupervised methods and is even comparable to supervised counterparts. Furthermore, symbolic-level interpretability emerges in the learned codebook of content, forging a near one-to-one alignment between machine representation and human knowledge.
Motif-Centric Representation Learning for Symbolic Music
Sep 19, 2023

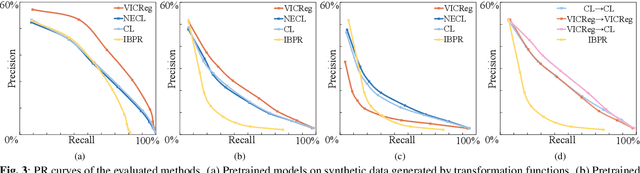
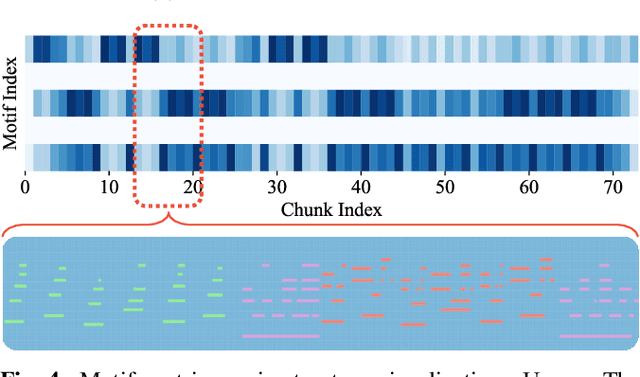
Music motif, as a conceptual building block of composition, is crucial for music structure analysis and automatic composition. While human listeners can identify motifs easily, existing computational models fall short in representing motifs and their developments. The reason is that the nature of motifs is implicit, and the diversity of motif variations extends beyond simple repetitions and modulations. In this study, we aim to learn the implicit relationship between motifs and their variations via representation learning, using the Siamese network architecture and a pretraining and fine-tuning pipeline. A regularization-based method, VICReg, is adopted for pretraining, while contrastive learning is used for fine-tuning. Experimental results on a retrieval-based task show that these two methods complement each other, yielding an improvement of 12.6% in the area under the precision-recall curve. Lastly, we visualize the acquired motif representations, offering an intuitive comprehension of the overall structure of a music piece. As far as we know, this work marks a noteworthy step forward in computational modeling of music motifs. We believe that this work lays the foundations for future applications of motifs in automatic music composition and music information retrieval.